
問題
如果你保存數據包含空字符串和null值在表的一列是分區的,後兩個值成為零寫作和閱讀。
為了說明這一點,創建一個簡單的DataFrame:
% scala org.apache.spark.sql.types進口。_進口org.apache.spark.sql.catalyst.encoders。RowEncoder val數據= Seq(行(" ")、行(2”)、行(3 "),行(4,“你好”)、行(5,null) val模式= new StructType ()。add (“a”, IntegerType)。添加(“b”, StringType) val df = spark.createDataFrame (spark.sparkContext.parallelize(數據),模式)
在這一點上,如果你顯示的內容df似乎沒有改變:

寫df讀一遍,並顯示它。空字符串替換為null值:
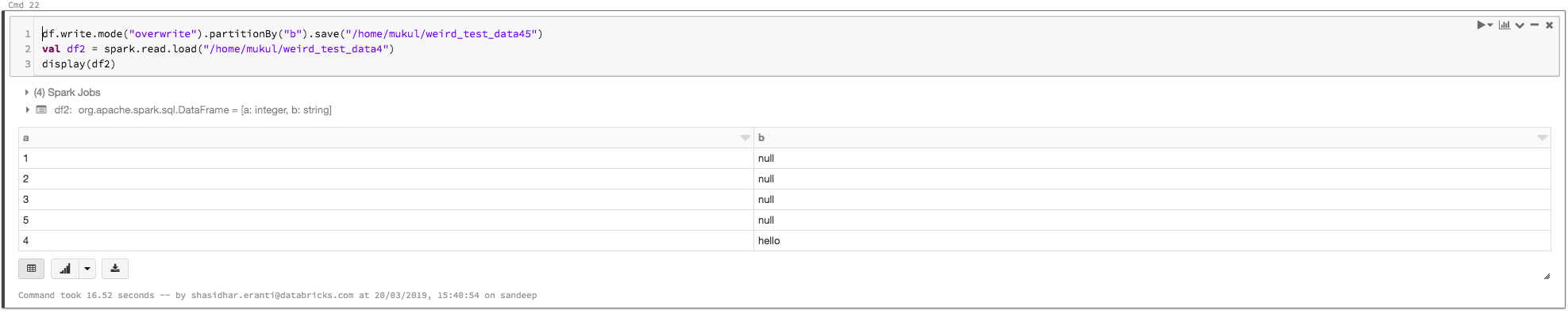
導致
這是預期的行為。它是繼承Apache蜂巢。
解決方案
一般來說,你不應該使用null和空字符串值在分區列。