
本文闡述了如何引發三角洲湖分區修剪合並成(AWS|Azure|GCP從磚)查詢。
分區修剪是一種優化技術來限製分區的數量所檢查的一個查詢。
討論
合並成可以計算昂貴的如果處理效率低下。你應該分區底層數據之前使用合並成。如果你不這樣做,可以影響查詢性能。
主要的教訓是:如果你知道哪些分區合並成查詢需要檢查,你應該查詢中指定它們,以便執行分區修剪。
示範:沒有分區修剪
這是業績不佳的一個例子合並成查詢沒有分區修剪。
首先創建以下δ表,調用delta_merge_into:
% scala
val df = spark.range (30000000)
.withColumn (“par”(“id”% 1000美元).cast (IntegerType))
.withColumn (“t”, current_timestamp ())
.write
.format(“δ”)
.mode(“覆蓋”)
.partitionBy(“標準”)
.saveAsTable (“delta_merge_into”)
然後合並DataFrame到三角洲表中創建一個表更新:
% scala
val updatesTableName = "更新"
val targetTableName = " delta_merge_into "
val更新= spark.range (100)。withColumn (“id”, (rand () * 30000000 * 2) .cast (IntegerType))
.withColumn (“par”(“id”% 2美元).cast (IntegerType))
.withColumn (“t”, current_timestamp ())
.dropDuplicates (" id ")
updates.createOrReplaceTempView (updatesTableName)
的更新表有100行三列,id,票麵價值,ts。的價值票麵價值總是1或0。
假設你運行以下簡單合並成查詢:
% scala
spark.sql (s”“”
|並入targetTableName美元
|使用$ updatesTableName
| targetTableName美元。id= $updatesTableName.id
|當匹配
|更新設置targetTableName美元。ts = $ updatesTableName.ts
|不匹配
|插入(id、par ts)值(updatesTableName美元。id, updatesTableName美元。票麵價值,$updatesTableName.ts)
”““.stripMargin)
查詢需要13.16分鍾來完成:
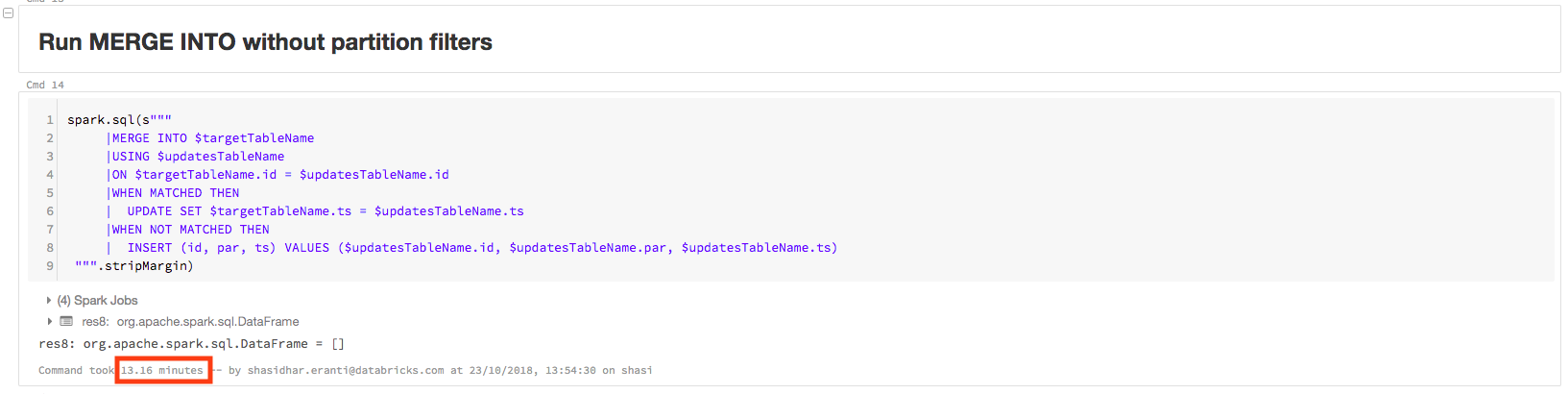
該查詢包含的物理方案PartitionCount: 1000,如下所示。這意味著Apache火花是掃描所有1000個分區來執行查詢。這不是一個有效的查詢,因為更新數據隻有分區的值1和0:
= = = =物理計劃
* (5)HashAggregate(鍵=[],函數= [finalmerge_count(合並計算# 8452 l)計數(1)# 8448 l),輸出= [count # 8449 l])
+ -交換SinglePartition
+ - * (4)HashAggregate(鍵=[],函數= [partial_count(1)計數# 8452 l),輸出= [count # 8452 l])
+ - *(4)項目
+ - *(4)濾波器(isnotnull (count # 8440 l) & & (count # 8440 l > 1))
+ - * (4)HashAggregate(鍵= (_row_id_ # 8399 l),函數= [finalmerge_sum(合並和# 8454 l)和(cast(1 # 8434為bigint)) # 8439 l),輸出= [count # 8440 l])
+ -交換hashpartitioning (_row_id_ # 8399 l, 200)
+ - * (3)HashAggregate(鍵= (_row_id_ # 8399 l),函數= [partial_sum (cast(1 # 8434為bigint))和# 8454 l),輸出= [_row_id_ # 8399 l,和# 8454 l))
+ - *(3)項目(_row_id_ # 8399 l, UDF (_file_name_ # 8404)作為一個# 8434)
+ - * (3)BroadcastHashJoin[鑄(id # 7514為bigint)], [id # 8390 l],內心,BuildLeft,假的
:- BroadcastExchange HashedRelationBroadcastMode(列表(cast(輸入[0,int,真]為bigint)))
:+ - * (2)HashAggregate(鍵= [id # 7514] =[],功能輸出= (# 7514)
:+ -交換hashpartitioning (id # 7514、200)
:+ - * (1)HashAggregate(鍵= [id # 7514] =[],功能輸出= (# 7514)
:+ - *(1)過濾isnotnull (id # 7514)
:+ - *(1)項目(鑄造(((rand (8188829649009385616) * 3.0 e7) * 2.0) int) id # 7514)
:+ - *(1)範圍(0 100 = 1步,分裂= 36)
+ - *(3)過濾器isnotnull (id # 8390 l)
+ - *(3)項目[id # 8390 l, _row_id_ # 8399 l, input_file_name () _file_name_ # 8404)
+ - *(3)項目[id # 8390 l, monotonically_increasing_id () _row_id_ # 8399 l)
+ - *(3)項目[id # 8390, # 8391, ts # 8392)
+ - * (3)FileScan拚花[id # 8390 l ts # 8392, par # 8391)分批處理:真的,DataFilters:[],格式:拚花,地點:TahoeBatchFileIndex [dbfs: / user /蜂巢/倉庫/ delta_merge_into], PartitionCount: 1000年,PartitionFilters: [], PushedFilters: [], ReadSchema: struct < id: bigint ts:時間戳>
解決方案
重寫查詢指定分區。
這合並成直接查詢指定分區:
% scala
spark.sql (s”“”
|並入targetTableName美元
|使用$ updatesTableName
| targetTableName美元。票麵價值IN (1,0) AND $targetTableName.id = $updatesTableName.id
|當匹配
|更新設置targetTableName美元。ts = $ updatesTableName.ts
|不匹配
|插入(id、par ts)值(updatesTableName美元。id, updatesTableName美元。票麵價值,$updatesTableName.ts)
”““.stripMargin)
現在查詢隻需要20.54秒完成在同一集群:
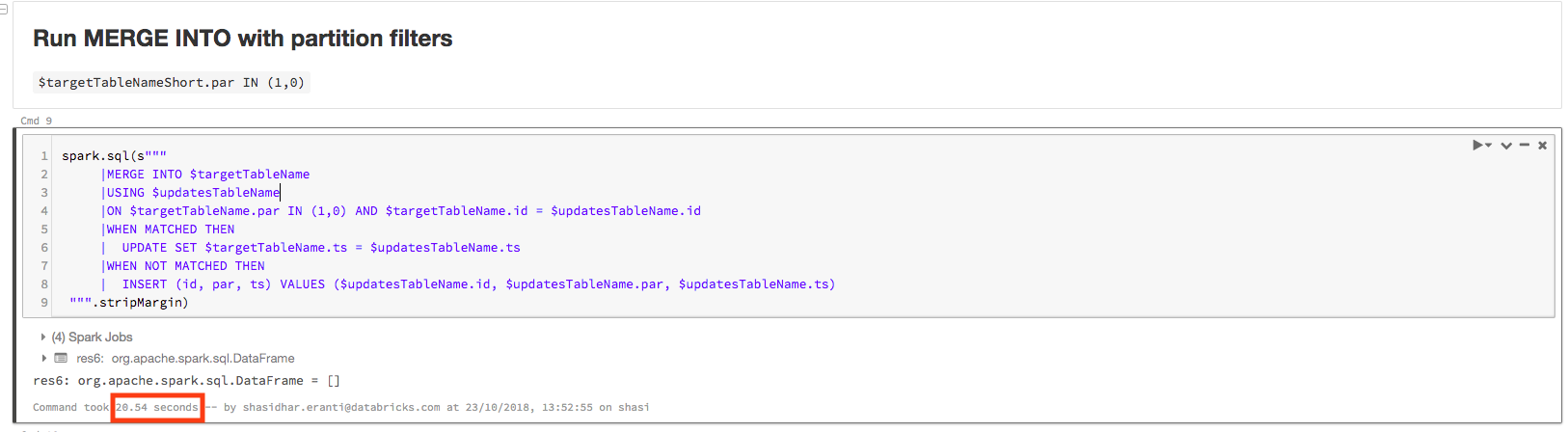
該查詢包含的物理方案PartitionCount: 2,如下所示。隻有一些小的變化,查詢現在快40多倍:
= = = =物理計劃
* (5)HashAggregate(鍵=[],函數= [finalmerge_count(合並計算# 7892 l)計數(1)# 7888 l),輸出= [count # 7889 l])
+ -交換SinglePartition
+ - * (4)HashAggregate(鍵=[],函數= [partial_count(1)計數# 7892 l),輸出= [count # 7892 l])
+ - *(4)項目
+ - *(4)濾波器(isnotnull (count # 7880 l) & & (count # 7880 l > 1))
+ - * (4)HashAggregate(鍵= (_row_id_ # 7839 l),函數= [finalmerge_sum(合並和# 7894 l)和(cast(1 # 7874為bigint)) # 7879 l),輸出= [count # 7880 l])
+ -交換hashpartitioning (_row_id_ # 7839 l, 200)
+ - * (3)HashAggregate(鍵= (_row_id_ # 7839 l),函數= [partial_sum (cast(1 # 7874為bigint))和# 7894 l),輸出= [_row_id_ # 7839 l,和# 7894 l))
+ - *(3)項目(_row_id_ # 7839 l, UDF (_file_name_ # 7844)作為一個# 7874)
+ - * (3)BroadcastHashJoin[鑄(id # 7514為bigint)], [id # 7830 l],內心,BuildLeft,假的
:- BroadcastExchange HashedRelationBroadcastMode(列表(cast(輸入[0,int,真]為bigint)))
:+ - * (2)HashAggregate(鍵= [id # 7514] =[],功能輸出= (# 7514)
:+ -交換hashpartitioning (id # 7514、200)
:+ - * (1)HashAggregate(鍵= [id # 7514] =[],功能輸出= (# 7514)
:+ - *(1)過濾isnotnull (id # 7514)
:+ - *(1)項目(鑄造(((rand (8188829649009385616) * 3.0 e7) * 2.0) int) id # 7514)
:+ - *(1)範圍(0 100 = 1步,分裂= 36)
+ - *(3)項目[id # 7830 l, _row_id_ # 7839 l, _file_name_ # 7844)
+ - *(3)過濾器(par # 7831 (1,0) & & isnotnull (id # 7830 l))
+ - *(3)項目[id # 7830, # 7831, _row_id_ # 7839 l, input_file_name () _file_name_ # 7844)
+ - *(3)項目[id # 7830, # 7831, monotonically_increasing_id () _row_id_ # 7839 l)
+ - *(3)項目[id # 7830, # 7831, ts # 7832)
+ - * (3)FileScan拚花[id # 7830 l ts # 7832, par # 7831)分批處理:真的,DataFilters:[],格式:拚花,地點:TahoeBatchFileIndex [dbfs: / user /蜂巢/倉庫/ delta_merge_into], PartitionCount: 2, PartitionFilters: [], PushedFilters: [], ReadSchema: struct < id: bigint ts:時間戳>