問題
你有一個結構體數組列與一個或多個DataFrame重複的列名。
如果你想創建一個增量表得到一個發現重複的列(s)在數據保存:錯誤。
示例代碼
你可以用這個例子複製錯誤代碼。
1)第一步設置一個數組與重複的列名。重複的列在示例代碼被注釋。
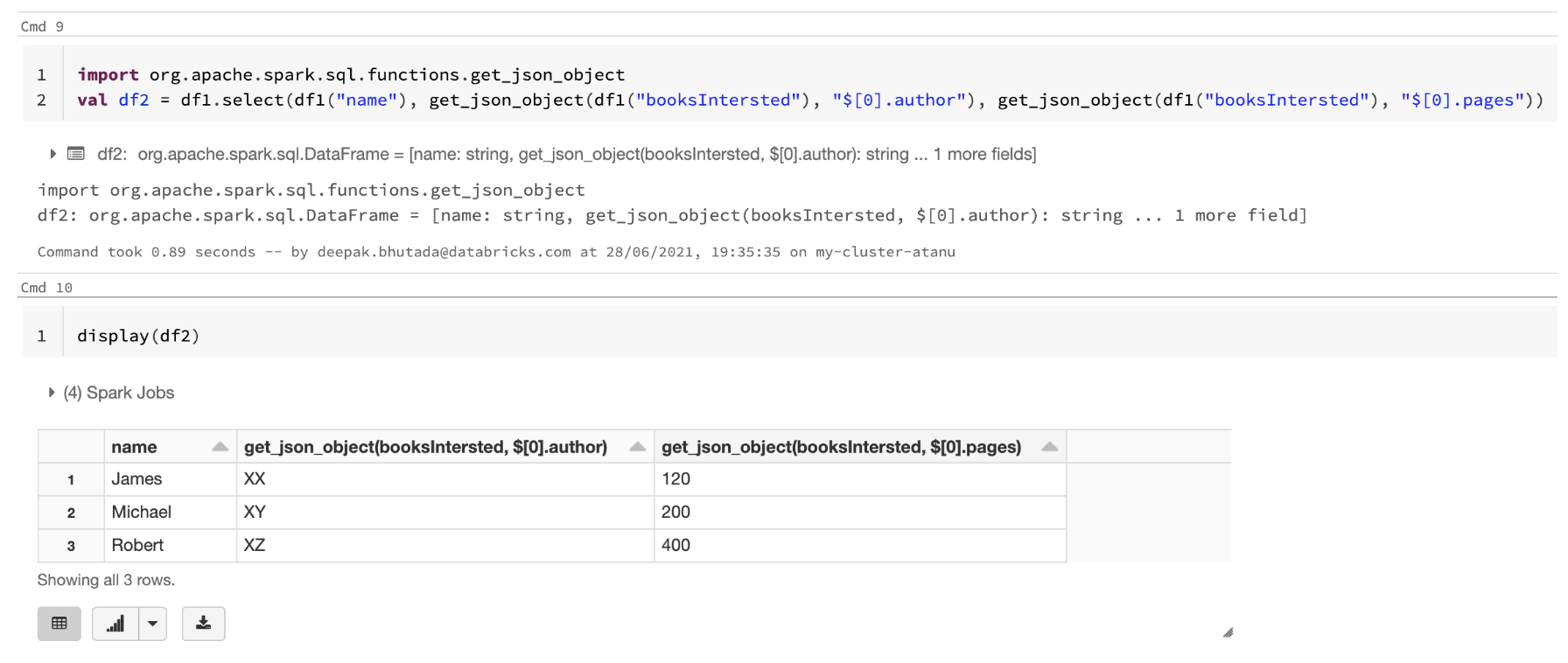
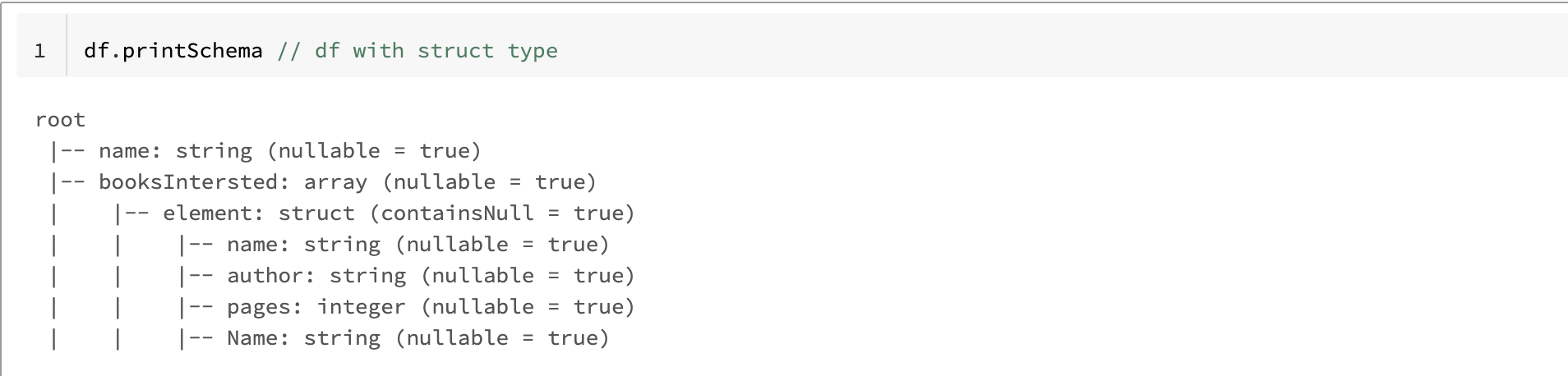
% scala / /示例json文件測試to_json函數val arrayStructData = Seq(行(“詹姆斯”,列表(行(“Java”、“XX”, 120年,“Java”)、行(“scala”、“XA”, 300年,“scala”)))、行(“邁克爾”,列表(行(“Java”、“XY”, 200年,“Java”)、行(“scala”、“XB”, 500年,“scala”)))、行(“羅伯特”,列表(行(“Java”、“XZ”, 400年,“Java”)、行(“scala”,“我”,250年,“scala”))))進口org.apache.spark.sql.types。{StructType, StructField, StringType、IntegerType ArrayType};val arrayStructSchema = new StructType閥門()(“名字”,StringType)閥門(“booksIntersted ArrayType(新StructType閥門()(“名字”,StringType) /閥門/複製列(“作者”,StringType)閥門閥門(“頁麵”,IntegerType)(“名字”,StringType))) / /複製列val df = spark.createDataFrame(火花。df sparkContext .parallelize (arrayStructData) arrayStructSchema)。printSchema / / df和結構類型
2)驗證DataFrame後,我們試圖創建一個增量表和獲得發現重複的列(s)在數據保存:錯誤。
% scala df.createOrReplaceTempView (df) df.write.format(“δ”).save (“/ mnt /δ/測試/ df_issue”)火花。sql(“使用三角洲位置創建表事件/ mnt /δ/測試/ df_issue’”)

導致
結構體數組具有相同名稱的列包含重複的列不能出現在三角洲表。這是真的,即使名稱在不同的情況下。
三角洲湖case-preserving,但不區分大小寫,當存儲模式。
為了避免潛在的數據損壞或數據丟失,不允許重複的列名。
解決方案
這種方法涉及將父列重複的列名為json字符串。
1)你需要轉換structtype列字符串使用to_json ()函數創建三角洲表之前。
% scala org.apache.spark.sql.functions進口。to_json val df1 = df.select (df(“名字”),to_json (df (“booksIntersted”)) .alias (“booksIntersted_string”)) / /使用這個df1.write.format .save(“δ”)(“/ mnt /δ/ df1_solution”)火花。sql(“使用三角洲創建表events_solution位置/ mnt /δ/ df1_solution”)火花。sql(“描述events_solution”),告訴()
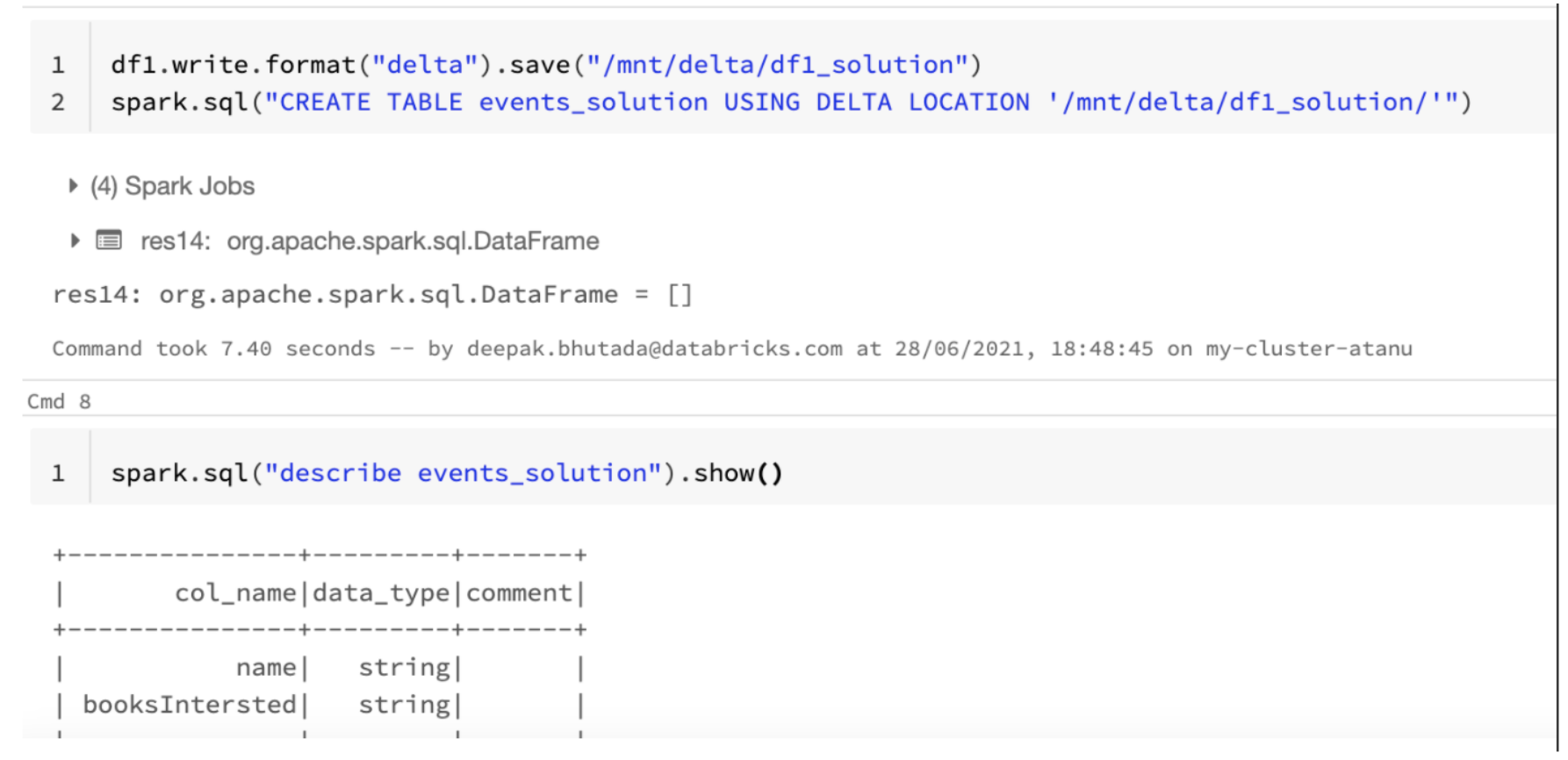
2)使用get_json_object ()函數從轉換後的字符串類型列中提取信息。
% scala org.apache.spark.sql.functions進口。get_json_object val df2 = df1.select (df1(“名字”),get_json_object (df1 (“bookInterested”)、“$ {0} .author”), get_json_object (df1 (“bookInterested”)、“$ {0} .pages "))顯示(df2)