問題
如果在S3中存儲的數據分區,分區列值用於源目錄結構中的文件夾名稱。然而,如果您使用一個SQS隊列作為流媒體來源,S3-SQS源不能檢測到分區列值。
例如,如果您保存以下DataFrame S3 JSON格式:
% scala val df = spark.range (10) .withColumn(“日期”,當前日期())df.write.partitionBy(“日期”). json (s3a: / / bucket名/ json)
將下麵的文件結構:
% scala s3a: / / bucket名/ json / _SUCCESS s3a: / / bucket名/ json /日期= 2018-10-25 / <單個json文件>
假設你有一個S3-SQS輸入流創建從隊列配置S3 bucket。如果你從這個S3-SQS直接加載數據輸入流使用下麵的代碼:
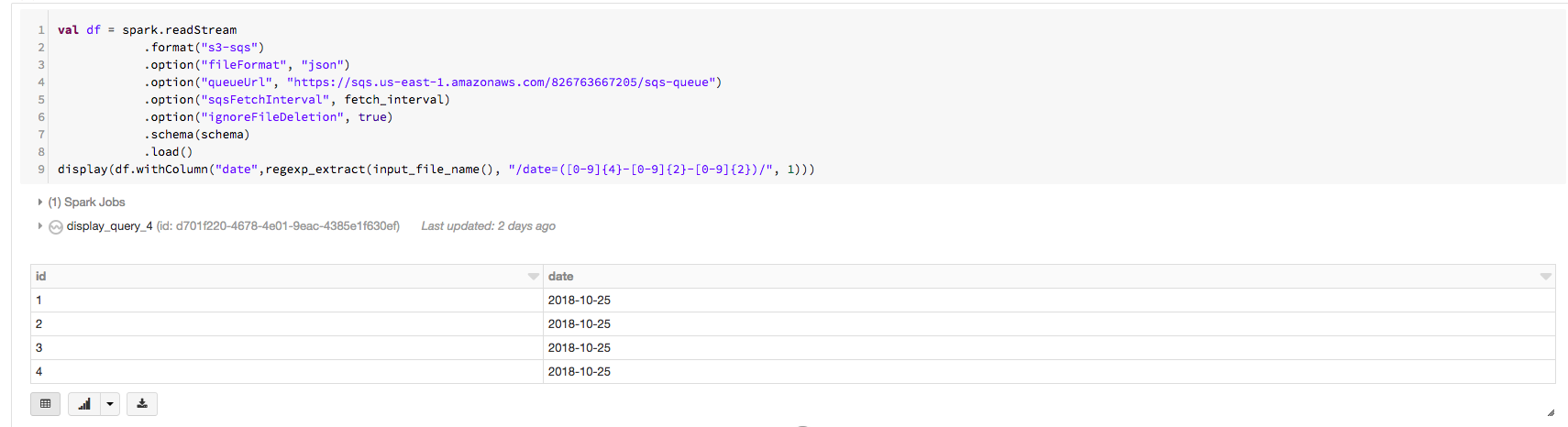
% scala org.apache.spark.sql.types進口。_ val模式= StructType(列表(StructField (“id”, IntegerType,假),StructField(“日期”,DateType假)))顯示(火花。readStream .format (“s3-sqs”) .option (“fileFormat”、“json”) .option (“queueUrl”、“https://sqs.us -東- 1. - amazonaws.com/826763667205/sqs隊列”).option (“sqsFetchInterval”、“1 m”) .option (“ignoreFileDeletion”,真正的). schema(模式).load ())
的輸出將會是:
你可以看到沒有正確填充列值的日期。
解決方案
您可以使用的組合input_file_name ()和regexp_extract ()udf正確地提取日期值,就像下麵的代碼片段:
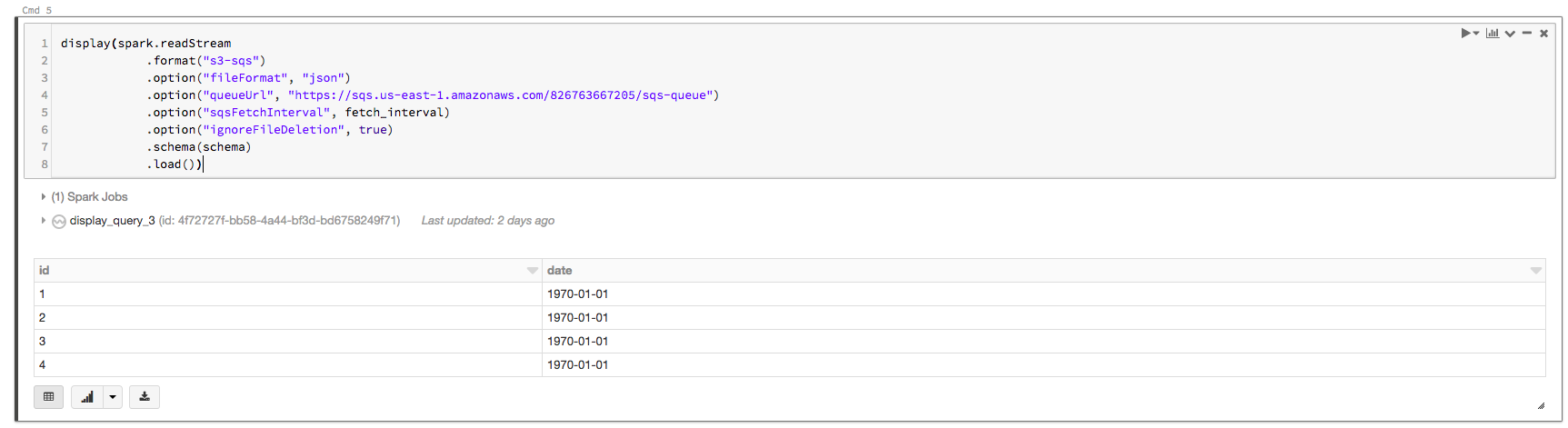
% scala org.apache.spark.sql.functions進口。_ val df =火花。readStream .format (“s3-sqs”) .option (“fileFormat”、“json”) .option (“queueUrl”、“https://sqs.us -東- 1. - amazonaws.com/826763667205/sqs隊列”).option (“sqsFetchInterval”, fetch_interval) .option (“ignoreFileDeletion”,真正的). schema(模式).load()顯示(df.withColumn(“日期”,regexp_extract (input_file_name(),“/日期= (\ \ d {4} - \ \ d {2} \ \ d {2}) / ", 1)))
現在你可以看到正確的日期列的值以下輸出: