
Apache火花不包括一個流API為XML文件。然而,您可以把自動裝載器的特征OSS的火花批API庫,Spark-XML流的XML文件。
在本文中,我們提出一個基於Scala解析XML數據使用一個裝載器的解決方案。
安裝Spark-XML圖書館
你必須安裝Spark-XMLOSS圖書館集群磚上。
檢查集群上安裝一個庫(AWS|Azure)文檔以了解更多的細節。
創建XML文件
創建XML文件,並使用DBUtils (AWS|Azure),將其保存到您的集群。
% scala val xml2 = " " <人> <人> <年齡出生= " 1990-02-24 " > 25歲< / > < /人> <人> <年齡出生= " 1985-01-01 " > 30歲< / > < /人> <人> <年齡出生= " 1980-01-01 " > 30歲< / > < /人> < /人> " " dbutils.fs.put (" / < path-to-save-xml-file > / < name-of-file > . xml”, xml2)
定義進口
進口所需的功能。
% scala進口com.databricks.spark.xml.functions.from_xml com.databricks.spark.xml進口。schema_of_xml spark.implicits進口。_進口com.databricks.spark.xml。_進口org.apache.spark.sql.functions。{< input_file_name >}
定義一個UDF將二進製轉換為字符串
流DataFrame需要字符串格式的數據。
你應該定義一個用戶定義的函數將二進製數據轉換成字符串數據。
% scala val toStrUDF = udf((字節:數組(字節))= >新字符串(字節,“utf - 8”))
提取XML模式
你必須提取XML模式才能實現流媒體DataFrame。
這可以推斷從文件使用schema_of_xml從Spark-XML方法。
XML字符串作為輸入,通過二進製火花數據。
% scala val df_schema = spark.read.format (binaryFile) .load (“/ FileStore /表/測試/ xml /數據/年齡/”).select (toStrUDF(“內容”)美元.alias(“文本”))val payloadSchema = schema_of_xml (df_schema.select(“文本”)。as [String])
實現流讀取器
在這一點上,所有必需的依賴項已滿足,所以你可以實現流的讀者。
使用readStream二進製和自動裝卸機清單模式選項啟用。
toStrUDF用於二進製數據轉換為字符串格式(文本)。
from_xml用於將字符串轉換為一個複雜的結構類型,與用戶定義的模式。
% scala val df = spark.readStream.format .option (“cloudFiles (“cloudFiles”)。useNotifications”、“假”)/ /使用清單模式,因此使用假.option (“cloudFiles。格式”、“binaryFile”) .load (“/ FileStore /表/測試/ xml /數據/年齡/”).select (toStrUDF(“內容”)美元.alias(“文本”))/ / UDF將二進製轉換成字符串.select (from_xml(“文本”美元,payloadSchema) .alias(“解析”))/ /函數將字符串轉換為複雜類型.withColumn(“路徑”,input_file_name) / / input_file_name用於提取輸入文件的路徑
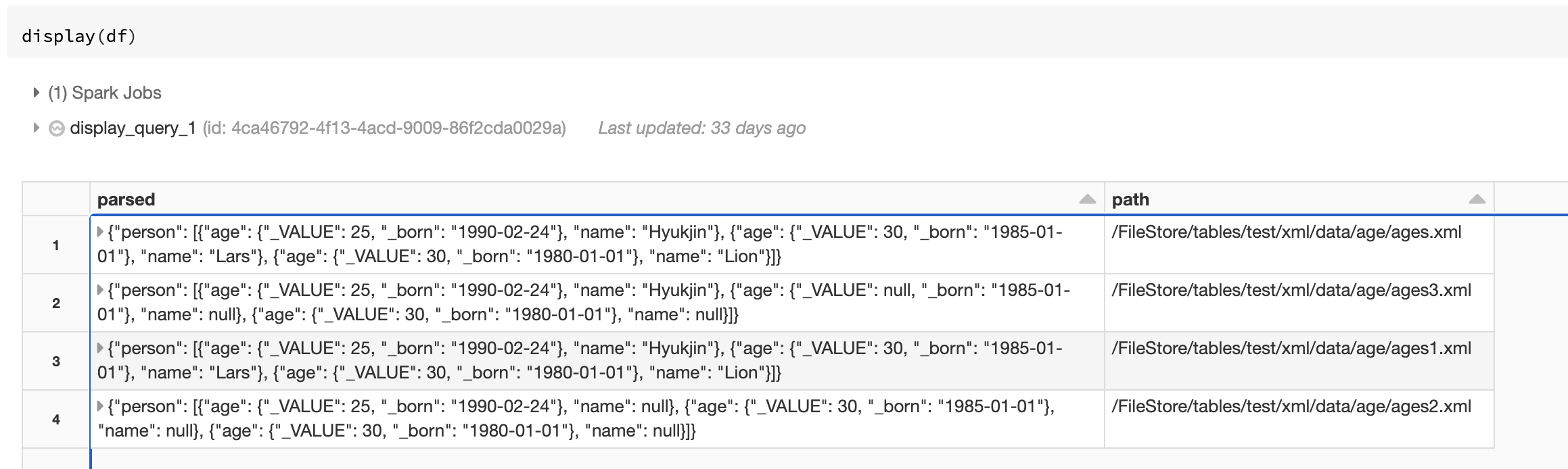
視圖輸出
一旦一切都設置,查看輸出顯示器(df)在一個筆記本上。
例如筆記本電腦
這個例子筆記本結合成一個單一的步驟,所有的功能的例子。
將其導入您的集群運行的例子。
流的XML例子筆記本
檢查流的XML例子筆記本。