

模型評價MLflow



許多數據科學家和ML工程師今天使用MLflow來管理他們的模型。MLflow是一個開源平台,使用戶能夠管理毫升生命Beplay体育安卓版本周期的所有方麵,包括但不限於實驗,再現性,部署和模型注冊表。毫升的關鍵步驟在開發模型的評估他們的表現在小說的數據集。
動機
為什麼我們評估模型?
模型評價毫升生命周期的一個組成部分。它使數據科學家測量、解釋和解釋他們的模型的性能。它加速模型開發時間內通過提供洞察如何以及為什麼模型執行的方式執行。尤其是毫升模型複雜度的增加,能夠迅速地觀察和理解毫升模型的性能是至關重要的一個成功的ML發展旅程。
在MLflow狀態的模型評價
直到現在,用戶可以評價的MLflow模型的性能python_function (pyfunc)模型的味道通過mlflow.evaluateAPI,它支持兩分類和回歸模型的評價。它計算和日誌一組內置的特定於任務的性能指標,模型性能的陰謀,和模型解釋MLflow跟蹤服務器。
評估MLflow模型對自定義指標不包括在內置的評價指標集,用戶必須定義一個自定義模型評估者插件。這包括創建一個自定義類,它實現了評估者ModelEvaluator接口,然後注冊一個求值程序入口點的一部分MLflow插件。這種剛性和複雜性可以為用戶禁止。
內部客戶的調查顯示,75%的受訪者表示他們經常或總是使用專業,業務指標除了基本的準確性和損失。數據科學家經常使用這些自定義指標更具描述性的業務目標(如轉化率),並包含額外的啟發式模型預測本身中沒有捕捉到。
在這個博客中,我們介紹一種簡單方便的方式評估MLflow模型定義的自定義指標。用這個功能,數據科學家可以很容易地將這個邏輯模型評價階段和快速確定下遊表現最好的模型沒有進一步分析
使用
內置的指標
MLflow烤在一組常用的性能和模型explainability指標分類和回歸量模型。評估模型對這些指標很簡單。我們所需要的是創建一個包含測試數據的評估數據集和目標和打電話mlflow.evaluate。
根據模型的類型,不同的指標計算。指的是默認的評估者行為部分在API文檔mlflow.evaluate最新的信息關於內置的指標。
例子
下麵是一個簡單的例子,如何評估分類器MLflow模型內置的指標。
首先,導入必要的庫
進口xgboost進口世鵬科技電子進口mlflow從sklearn.model_selection進口train_test_split然後,我們把數據集,適合模型,創建我們的評估數據集
#負載成人UCI數據集;它劃分為訓練集和測試集X, y = shap.datasets.adult ()X_train、X_test y_train y_test = train_test_split (X, y, test_size =0.33random_state =42)#火車XGBoost模型模型= xgboost.XGBClassifier ()。fit (X_train y_train)#構建一套評價數據集的測試eval_data = X_testeval_data [“目標”]= y_test最後,我們開始一個MLflow運行和電話mlflow.evaluate
與mlflow.start_run ()作為運行:model_info = mlflow.sklearn.log_model(模型,“模型”)結果= mlflow.evaluate (model_info.model_uri,eval_data,目標=“目標”,model_type =“分類”,dataset_name =“成人”,評價者= [“默認”),)我們可以找到記錄的指標和MLflow UI工件:


自定義指標
對自定義指標評估模型,我們隻是通過自定義度量函數的列表mlflow.evaluateAPI。
函數定義的需求
自定義指標函數應該接受兩個必需的參數和一個可選的參數按照以下順序:
eval_df:熊貓或火花DataFrame包含預測和一個目標列。例如:如果輸出模型的三個數字是一個矢量,然後
eval_dfDataFrame會看起來像: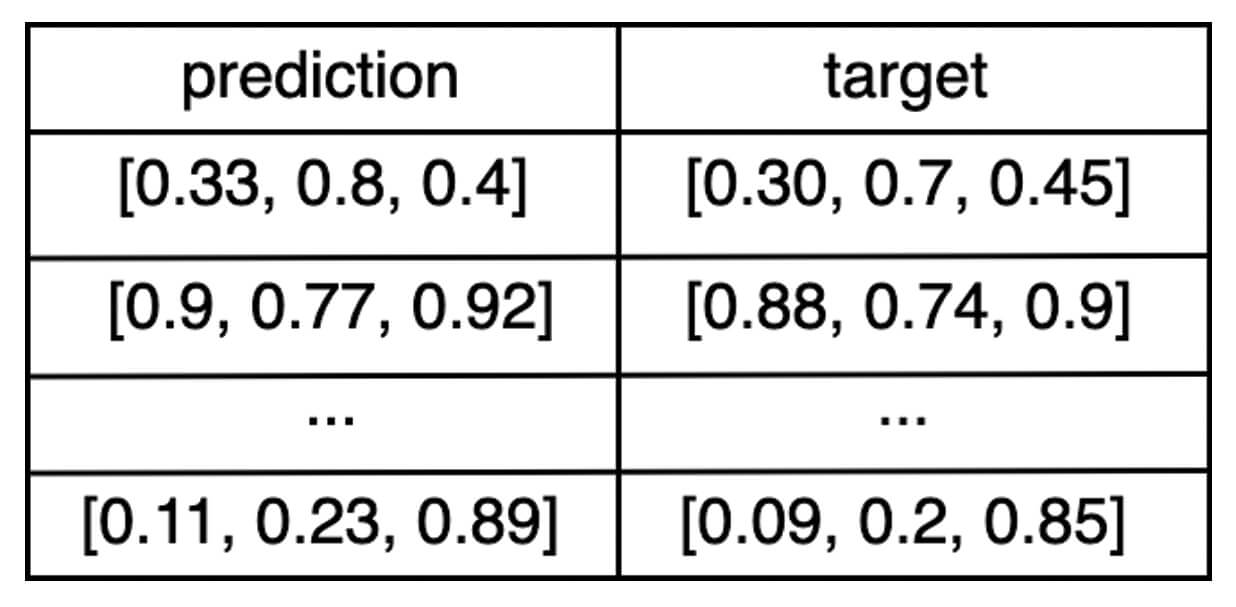
builtin_metrics:一本字典包含內置的指標例如回歸量模型,
builtin_metrics類似於:{“example_count”:4128年,“max_error”:3.815,“mean_absolute_error”:0.526,“mean_absolute_percentage_error”:0.311,“的意思是”:2.064,“mean_squared_error”:0.518,“r2_score”:0.61,“root_mean_squared_error”:0.72,“sum_on_label”:8520.4}- (可選)
artifacts_dir:通往一個臨時目錄中,可以使用自定義度量函數來臨時存儲日誌MLflow之前生產的工件。例如注意這將不同取決於具體的環境設置。例如,在MacOS它看起來像這樣:
/var/文件夾/ 5 d / lcq9fgm918l8mg8vlbcq4d0c0000gp / T / tmpizijtnvo如果文件存儲在其他地方比工件
artifacts_dir,確保他們堅持直到完成後執行的mlflow.evaluate。

返回值的要求
代表生產指標的函數應該返回一個字典,可以選擇返回第二個詞典代表產生的工件。對於這兩個字典,為每一個條目的關鍵代表相應指標的名稱或工件。
雖然每個指標必須是一個標量,有多種方法來定義構件:
- 工件的路徑文件
- 一個JSON對象的字符串表示
- 一個熊貓DataFrame
- numpy數組
- matplotlib圖
- 其他對象將會試圖榨菜默認協議
參考的文檔mlflow.evaluate為更深入的定義的細節。
例子
讓我們走進一個具體的例子,使用自定義指標。為此,我們將創建一個從玩具模型加州住房數據集。
從sklearn.linear_model進口LinearRegression從sklearn.datasets進口fetch_california_housing從sklearn.model_selection進口train_test_split進口matplotlib.pyplot作為plt進口numpy作為np進口mlflow進口操作係統然後,設置數據集和模型
#加載加州住房數據集cali_housing = fetch_california_housing (as_frame =真正的)#將數據集分為訓練和測試分區X_train、X_test y_train y_test = train_test_split (cali_housing。數據,cali_housing。目標,test_size =0.2random_state =123年)#火車模型lin_reg = LinearRegression ()。fit (X_train y_train)#創建評估dataframeeval_data = X_test.copy ()eval_data [“目標”]= y_test激動人心的部分來了:定義自定義指標函數!
defexample_custom_metric_fn(eval_df、builtin_metrics artifacts_dir):”“”這個例子定義度量函數創建一個度量基於“預測”和”“目標”“列”“eval_df ' '和一個度量來自現有的指標' ' builtin_metrics ' '。它還生成並保存一個散點圖“artifacts_dir ' '可視化預測和目標之間的關係對於一個給定的模型文件作為一個圖像工件。”“”指標= {“squared_diff_plus_one”:np。總和(np。腹肌(eval_df [“預測”]- eval_df [“目標”)+1)* *2),“sum_on_label_divided_by_two”:builtin_metrics (“sum_on_label”)/2,}plt.scatter (eval_df [“預測”],eval_df [“目標”])plt.xlabel (“目標”)plt.ylabel (“預測”)plt.title (“目標和預測”)plot_path = os.path.join (artifacts_dir,“example_scatter_plot.png”)plt.savefig (plot_path)工件= {“example_scatter_plot_artifact”:plot_path}返回指標、工件最後,將所有這些在一起,我們將開始一個MLflow運行和電話mlflow.evaluate:
與mlflow.start_run ()作為運行:mlflow.sklearn.log_model (lin_reg“模型”)model_uri = mlflow.get_artifact_uri (“模型”)結果= mlflow.evaluate (= model_uri模型,data = eval_data,目標=“目標”,model_type =“回歸量”,dataset_name =“cali_housing”,custom_metrics = [example_custom_metric_fn],)可以找到記錄自定義指標和工件與默認度量和工件。紅框區域顯示登錄頁麵上運行自定義指標和工件。

評估結果以編程方式訪問
到目前為止,我們已經探索了內置和自定義指標的評價結果MLflow UI。然而,我們也可以通過編程方式訪問它們EvaluationResult返回的對象mlflow.evaluate。讓我們繼續我們的自定義指標上麵的例子,看看我們可以通過編程方式訪問其評價結果。(假設結果是我們的EvaluationResult從這裏實例)。
我們可以通過計算指標的集合result.metrics字典包含名稱和標量值的度量。的內容result.metrics應該是這樣的:
{“example_count”:4128年,“max_error”:3.8147801844098375,“mean_absolute_error”:0.5255457157103748,“mean_absolute_percentage_error”:0.3109520331276797,“mean_on_label”:2.064041664244185,“mean_squared_error”:0.5180228655178677,“r2_score”:0.6104546894797874,“root_mean_squared_error”:0.7197380534040615,“squared_diff_plus_one”:6291.3320597821585,“sum_on_label”:8520.363989999996,“sum_on_label_divided_by_two”:4260.181994999998}同樣,工件通過訪問的集合result.artifacts字典。每個條目是一個的值EvaluationArtifact對象。result.artifacts應該是這樣的:
{“example_scatter_plot_artifact”:ImageEvaluationArtifact (uri =“some_uri / example_scatter_plot_artifact_on_data_cali_housing.png”),“shap_beeswarm_plot”:ImageEvaluationArtifact (uri =“some_uri / shap_beeswarm_plot_on_data_cali_housing.png”),“shap_feature_importance_plot”:ImageEvaluationArtifact (uri =“some_uri / shap_feature_importance_plot_on_data_cali_housing.png”),“shap_summary_plot”:ImageEvaluationArtifact (uri =“some_uri / shap_summary_plot_on_data_cali_housing.png”)}例如筆記本電腦
引擎蓋下麵
下圖說明了這一切是如何工作的引擎蓋下麵:

結論
在這篇文章中,我們介紹:
- 模型評價的意義和目前在MLflow支持。
- 為什麼一個簡單的方法為MLflow用戶將自定義指標納入MLflow模型是很重要的。
- 如何評估模型與默認度量。
- 如何評估模型與自定義指標。
- 在幕後MLflow如何處理模型評估。