創建一個集群
請注意
這些指令是為了統一目錄啟用工作區使用更新UI創建集群。切換到傳統集群創建UI,點擊用戶界麵預覽在頁麵的頂部創建集群和切換設置。
不統一的文檔目錄遺留UI,明白了配置集群。比較新和遺留的集群類型,明白了集群UI變化和集群訪問模式。
本文解釋了可用的配置選項,當你創建和編輯數據磚集群。它著重於創建和編輯集群使用UI。其他方法,請參閱集群CLI(遺留),集群API,磚起程拓殖的提供者。
集群創建用戶界麵允許您選擇集群配置細節,包括:
訪問集群創建接口
使用用戶界麵創建一個集群,您必須在數據科學與工程或機器學習persona-based環境。使用角色切換器如果有必要的話)。
然後你可以:
點擊
 計算在側邊欄創建計算在計算頁麵。
計算在側邊欄創建計算在計算頁麵。點擊新>集群在側邊欄。
集群訪問模式是什麼?
集群訪問模式是一個安全特性,決定誰可以使用一個集群和數據可以通過集群。當你創建任何集群在磚,你必須選擇一個訪問模式。
訪問模式 |
對用戶可見 |
加州大學的支持 |
支持的語言 |
筆記 |
|---|---|---|---|---|
單用戶 |
總是 |
是的 |
Python, SQL, Scala, R |
可以分配給單個用戶使用的。閱讀從一個視圖,你必須有 |
共享 |
總是(保費計劃要求) |
是的 |
Python(磚運行時的11.1及以上),SQL |
可以使用多個用戶與用戶之間數據隔離。看到共享的局限性。 |
任何隔離共享 |
管理員可以隱藏這個集群類型執行用戶隔離在管理頁麵設置。 |
沒有 |
Python, SQL, Scala, R |
|
自定義 |
隱藏(所有新集群) |
沒有 |
Python, SQL, Scala, R |
這個選項顯示隻有如果你有現有的集群,而無需指定的訪問模式。 |
你可以升級現有集群的要求統一目錄通過設置集群訪問模式單用戶或共享。有額外的訪問模式的局限性對結構化流統一目錄,看看結構化流媒體支持。
磚的運行時版本的
磚運行時核心組件的集合上運行您的集群。所有磚運行時版本包括Apache火花和添加組件和更新,提高可用性、性能和安全性。有關詳細信息,請參見磚運行時。
您選擇使用集群的運行時和版本磚的運行時版本的下拉當您創建或編輯一個集群。
集群節點類型
一個集群由一個驅動節點和零個或多個工作節點。你可以選擇單獨的雲提供商為司機和工人節點實例類型,盡管默認情況下司機節點使用相同的實例類型工作節點。不同家庭的實例類型適合不同的用例,如內存密集型或計算密集型工作負載。
司機節點
司機節點維護狀態信息的筆記本電腦連接到集群。司機節點還維護SparkContext,解釋所有的命令你在集群上運行從一個筆記本和一個圖書館,並運行Apache主坐標的火花引發執行人。
司機節點類型的默認值是一樣的工人節點類型。你可以選擇一個更大的驅動節點類型和更多的內存,如果你正計劃收集()大量的數據從引發工人和分析他們在筆記本上。
提示
因為司機節點維護的所有狀態信息的筆記本電腦,確保分離未使用的筆記本從司機節點。
工作者節點
磚工節點運行正常運轉所需的火花執行者和其他服務集群。當你分發工作負載與火花,所有的分布式處理發生在工作節點。磚一個人均執行器節點運行。因此,執行者和工人是交替使用的磚結構。
提示
火花運行工作,你至少需要一個工作節點。如果集群的工人為零,你可以運行non-Spark命令司機節點上,但火花命令將失敗。
GPU實例類型
對於需求的高性能的計算有挑戰性的任務,像那些與深度學習,磚支持集群加速的圖形處理單元(gpu)。有關更多信息,請參見GPU-enabled集群。
與當地ssd集群實例類型
最新的實例類型列表,每一個的價格,和當地的ssd的大小,看到GCP定價估計量。
實例類型,當地ssd自動使用默認穀歌雲服務器端加密和加密使用磁盤緩存改進的性能。緩存的大小在所有實例類型自動設置,所以你不需要顯式地設置磁盤使用情況。
為您的集群配置本地ssd
您可以配置的本地ssd附著當您使用您的集群集群API創建集群。
配置本地ssd的數量,設置一個值local_ssd_count在gcp_attributes對象。每個實例類型隻能支持一定數量的當地ssd。中指定的值local_ssd_count必須是有效的司機和工人實例類型。有關更多信息,請參見GCP的醫生當地的ssd和機器類型。
集群規模和自動定量
當你創建一個磚集群,可以為集群提供一個固定數量的工人或提供的最小和最大數量的工人集群。
當你提供固定大小的集群,磚確保集群有指定數量的工人。當你為工人的數量,提供一係列磚選擇適當數量的工人需要運行你的工作。這被稱為自動定量。
與自動定量、動態磚是重新分配人員占你的工作的特點。某些部位的管道可能比其他人更計算要求,和磚自動添加額外的工人在這階段的工作(並刪除他們當他們不再需要)。
自動定量使它更容易實現集群利用率高,因為你不需要提供集群匹配工作負載。這尤其適用於負載的需求隨時間變化(如每天探索過程中數據集),但它也能適用於一次性短工作負載的配置需求是未知的。自動定量因此提供了兩個優點:
工作負載可以運行得更快而constant-sized under-provisioned集群。
自動定量集群靜態大小的集群相比可以降低整體成本。
根據集群的常數大小和工作負載,自動定量給你其中的一個或兩個同時受益。集群規模可以低於最小數量的工人時選擇的雲提供商終止實例。在這種情況下,磚不斷重試重新供應實例為了維持最低的工人數量。
請注意
自動定量是不可用的spark-submit就業機會。
請注意
計算伸縮擴展限製了集群大小結構化流工作負載。磚建議使用三角洲表與增強的自動定量直播工作負載。看到增強的自動定量是多少?。
優化和標準自動定量
磚提供兩種類型的集群節點自動定量:優化和標準。優化自動定量僅可在保費和企業的定價方案。看到Beplay体育安卓版本平台層。
優化的自動定量用於:
所有工作的集群
互動集群溢價或企業計劃工作空間運行6.4 +磚運行時版本。
標準自動定量用於:
標準計劃工作區
交互式運行在磚上的集群運行時6.3或更低水平。
如何優化自動定量的行為
尺度從最小到最大2步驟。
集群可以縮小,即使不是閑置,通過觀察洗牌文件狀態。
基於當前節點的比例尺度。
工作群,尺度下如果集群充分利用過去40秒。
通用的集群,尺度下如果集群充分利用過去150秒。
的
spark.databricks.aggressiveWindowDownS火花在幾秒鍾內配置屬性指定集群頻率使縮小規模的決定。持續增加的值會導致一個集群規模更慢。最大值是600。


本地磁盤加密
實例類型,當地ssd與默認穀歌雲服務器端加密加密。看到與當地ssd集群實例類型。
集群的標簽
集群標簽允許您方便地監視各種團體所使用的雲資源的成本在你的組織中。您可以指定標簽作為鍵值對,當你創建一個集群,和磚這些標簽適用於磚GKE集群上運行時豆莢和持久卷和DBU的使用報告。
的磚計費使用圖表在賬戶控製台可以總使用個人標簽。計費使用CSV報告從相同的下載頁麵還包括違約和自定義標記。標簽也傳播GKE和GCE標簽。
為詳細的信息關於池和集群標簽類型一起工作,明白了使用集群和池監控使用標簽
集群配置標簽:
在標簽節中,為每個定製標記添加一個鍵-值對。
點擊添加。
穀歌雲配置
當您配置一個集群的穀歌穀歌雲實例可以指定特定於雲的選項。
可用性區域
在集群配置頁麵,高級選項,您可以選擇集群的可用性區域。此設置允許您指定使用哪個你想要的可用性區域集群。默認情況下,設置為可用性區域設置哈(高可用性)。
你也可以選擇一個特定的區域或汽車。選擇一個特定的區域主要是有用的,如果您的組織購買了保留的實例在特定的可用性區域。如果你選擇汽車,可用性區域自動為您選擇。
自動定量本地存儲
穀歌雲計算實例可以補充額外的存儲在工人級別使用帶狀持續固態磁盤。
自動定量本地存儲,數據磚監視器上可用的空閑磁盤空間集群的火花的工人。如果一個工人開始在磁盤上運行過低,磚自動調整大小的帶狀SSD PD之前耗盡了磁盤空間。Zonal-SSD PD卷附加到一個極限5 TB的總磁盤空間的每個實例(包括實例的本地存儲)。
配置自動定量儲存、選擇啟用自動定量本地存儲。
默認配置存儲
磚規定以下存儲為每個工作節點:
一個100 GB的引導磁盤根卷使用的主機操作係統和磚內部服務。
當地使用的SSD引發工人。這個主機火花服務日誌。配置本地ssd,明白了與當地ssd集群實例類型。
遠程ssd存儲自動定量時啟用。這些從150 GB在創建並根據需要自動定量。
使用搶占的實例
一個搶占式虛擬機實例是一個實例,您可以創建和運行在一個低得多的價格要比普通的實例。然而,穀歌雲可能會停止這些實例(搶占)如果需要訪問這些資源其他任務。搶占式實例使用穀歌計算引擎能力過剩,所以他們的可用性隨使用。
當你創建一個新的集群,您可以啟用搶占的VM實例在兩種不同的方式:
當你使用UI創建一個集群時,你可以點擊搶占式實例旁邊的工作類型細節。
當你使用UI創建一個實例池,您可以設置隨需應變/搶占式來所有的搶占式,搶占式與後備GCP,或對需求的質量。如果搶占的VM實例並不可用,默認情況下,使用隨需應變的VM實例集群將退回。配置默認行為,集
gcp_attributes.gcp_availability來PREEMPTIBLE_GCP或PREEMPTIBLE_WITH_FALLBACK_GCP。默認值是ON_DEMAND_GCP。
{“instance_pool_name”:“搶占的w / o後備API測試”,“node_type_id”:“n1-highmem-4”,“gcp_attributes”:{“gcp_availability”:“PREEMPTIBLE_GCP”}}
接下來,創建一個新的集群和設置池搶占式實例池。
火花配置
微調刺激就業,你可以提供自定義的火花配置屬性在一個集群中配置。
在集群配置頁麵,單擊高級選項切換。
單擊火花選項卡。
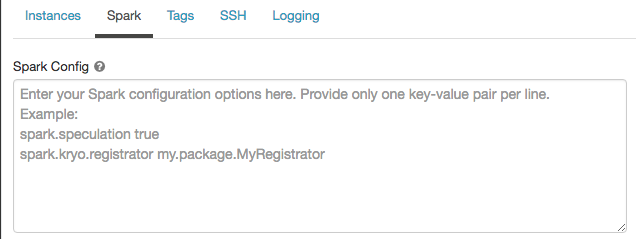
在火花配置進入配置屬性,每行一個鍵-值對。

當您配置集群使用集群API,設置火花屬性spark_conf字段創建新集群API或更新集群配置API。
執行火花在集群配置,工作空間管理員可以使用集群政策。
檢索一個火花配置屬性從一個秘密
磚建議存儲敏感信息,比如密碼,秘密而不是明文。引用一個秘密的火花配置,使用下麵的語法:
火花。<屬性名>{{秘密/ < scope-name > / <秘密名字>}}
例如,設置一個火花配置屬性密碼秘密存儲的值秘密/ acme_app /密碼:
火花。密碼{{秘密/ acme-app /密碼}}
有關更多信息,請參見語法引用火花配置中的秘密財產或環境變量。
環境變量
您可以配置自定義環境變量,您可以訪問init腳本在一個集群上運行。磚還提供了預定義的環境變量在init腳本,您可以使用。你不能覆蓋這些預定義的環境變量。
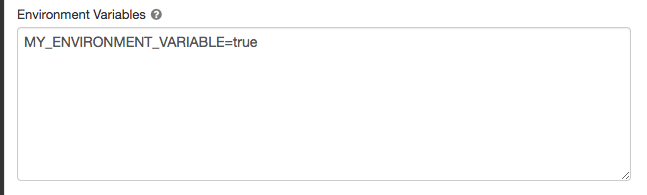
在集群配置頁麵,單擊高級選項切換。
單擊火花選項卡。
設置環境變量環境變量字段。

集群日誌交付
當您創建一個集群時,您可以指定一個位置提供的日誌引發司機節點,工作節點,和事件。日誌是每5分鍾發送到您所選擇的目的地。終止一個集群時,磚保證交付的所有日誌生成到集群是終止。
日誌的目的地取決於集群ID。如果指定的目的地dbfs: / cluster-log-delivery、集群日誌0630 - 191345 leap375交付給dbfs: / cluster-log-delivery / 0630 - 191345 leap375。
配置日誌交付地點:
在集群配置頁麵,單擊高級選項切換。
單擊日誌記錄選項卡。
選擇一個目的地類型。
進入集群日誌路徑。
日誌路徑必須是DBFS開頭的路徑
dbfs: /。
請注意
這個功能也可以在REST API。看到集群API。