工作區中的工程特性存儲特性
這個頁麵描述如何創建和使用功能表存儲在工作區中功能。
請注意
如果啟用了工作區為統一目錄,任何表由統一目錄管理有一個主鍵自動表,您可以使用一個特性模型訓練和推理。所有統一目錄功能,如安全,標簽,和cross-workspace訪問,可用自動功能表。信息處理功能表統一Catalog-enabled工作區,明白了特性工程統一目錄。
跟蹤特性血統和新鮮的信息,請參閱發現特性和跟蹤特性的血統。
請注意
數據庫和功能表名隻能包含字母數字字符和下劃線(_)。
為功能創建一個數據庫表
在創建任何特性表之前,您必須創建一個數據庫來存儲它們。
%sql創建數據庫如果不存在<數據庫- - - - - -的名字>
功能表存儲三角洲表。當你創建一個功能表create_table(功能存儲客戶端v0.3.6及以上)或create_feature_table(v0.3.5下麵),您必須指定數據庫名稱。例如,這個參數創建一個增量表命名customer_features在數據庫中recommender_system。
name = ' recommender_system.customer_features '
創建一個表在磚功能存儲特性
請注意
你也可以注冊一個存在差值表作為一個功能表。看到注冊一個現有的三角洲表特性表。
創建一個功能表的基本步驟是:
編寫的Python函數計算功能。每個函數的輸出應該是一個Apache火花DataFrame獨特的主鍵。主鍵可以包含一個或多個列。
通過實例化一個創建一個功能表
FeatureStoreClient和使用create_table(v0.3.6及以上)或create_feature_table(v0.3.5下麵)。填充功能表使用
write_table。
從databricks.feature_store進口feature_tabledefcompute_customer_features(數據):“特性計算代碼返回DataFrame customer_id“主鍵””通過由customer_id #創建功能表鍵#從compute_customer_features DataFrame輸出的模式從databricks.feature_store進口FeatureStoreClientcustomer_features_df=compute_customer_features(df)fs=FeatureStoreClient()customer_feature_table=fs。create_table(的名字=“recommender_system.customer_features”,primary_keys=“customer_id”,模式=customer_features_df。模式,描述=“客戶特性”)#一個替代方法是使用“create_table”並指定“df”的論點。#這段代碼自動保存功能的底層δ表。# customer_feature_table = fs.create_table (#……# df = customer_features_df,#……#)#使用組合鍵,通過所有鑰匙create_table調用# customer_feature_table = fs.create_table (#……# primary_keys = (“customer_id”、“日期”),#……#)#使用write_table寫數據到功能表#覆蓋模式全麵刷新功能表fs。write_table(的名字=“recommender_system.customer_features”,df=customer_features_df,模式=“覆蓋”)
從databricks.feature_store進口feature_tabledefcompute_customer_features(數據):“特性計算代碼返回DataFrame customer_id“主鍵””通過由customer_id #創建功能表鍵#從compute_customer_features DataFrame輸出的模式從databricks.feature_store進口FeatureStoreClientcustomer_features_df=compute_customer_features(df)fs=FeatureStoreClient()customer_feature_table=fs。create_feature_table(的名字=“recommender_system.customer_features”,鍵=“customer_id”,模式=customer_features_df。模式,描述=“客戶特性”)#一個替代方法是使用“create_feature_table”並指定“features_df”的論點。#這段代碼自動保存功能的底層δ表。# customer_feature_table = fs.create_feature_table (#……# features_df = customer_features_df,#……#)#使用組合鍵,通過所有鑰匙create_feature_table調用# customer_feature_table = fs.create_feature_table (#……#鍵= (“customer_id”、“日期”),#……#)#使用write_table寫數據到功能表#覆蓋模式全麵刷新功能表fs。write_table(的名字=“recommender_system.customer_features”,df=customer_features_df,模式=“覆蓋”)從databricks.feature_store進口feature_tabledefcompute_customer_features(數據):“特性計算代碼返回DataFrame customer_id“主鍵””通過由customer_id #創建功能表鍵#從compute_customer_features DataFrame輸出的模式從databricks.feature_store進口FeatureStoreClientcustomer_features_df=compute_customer_features(df)fs=FeatureStoreClient()customer_feature_table=fs。create_feature_table(的名字=“recommender_system.customer_features”,鍵=“customer_id”,模式=customer_features_df。模式,描述=“客戶特性”)#一個替代方法是使用“create_feature_table”並指定“features_df”的論點。#這段代碼自動保存功能的底層δ表。# customer_feature_table = fs.create_feature_table (#……# features_df = customer_features_df,#……#)#使用組合鍵,通過所有鑰匙create_feature_table調用# customer_feature_table = fs.create_feature_table (#……#鍵= (“customer_id”、“日期”),#……#)#使用write_table寫數據到功能表#覆蓋模式全麵刷新功能表fs。write_table(的名字=“recommender_system.customer_features”,df=customer_features_df,模式=“覆蓋”)
注冊一個現有的三角洲表特性表
v0.3.8和上麵,你可以注冊一個現有的差值表作為一個功能表。表必須存在於metastore三角洲。
請注意
來更新注冊表功能,你必須使用Python API特性存儲。
fs。register_table(delta_table=“recommender.customer_features”,primary_keys=“customer_id”,描述=“客戶特性”)
訪問控製功能表
看到訪問控製功能表。
更新一個功能表
你可以更新一個功能表添加新特性或通過修改特定行基於主鍵。
以下功能表元數據不能更新:
主鍵
分區鍵
名稱或類型的現有功能
新功能添加到現有的功能表
您可以將新功能添加到現有特性表兩種方式中的一種:
更新現有的特性計算功能和運行
write_tableDataFrame返回。這個更新功能表模式和合並新特性值基於主鍵。創建一個新的特性計算函數值計算新特性。這個新的計算函數必須包含返回的DataFrame功能表的主鍵和分區鍵(如果定義)。運行
write_table與DataFrame編寫新功能到現有的功能表,使用相同的主鍵。
隻更新特定的功能表中的行
使用模式=“合並”在write_table。主鍵的行不存在DataFrame發送的write_table電話保持不變。
fs。write_table(的名字=“recommender.customer_features”,df=customer_features_df,模式=“合並”)
安排一個工作表更新功能
確保功能特性表中總是有最新值,磚建議你創建一個工作運行一個筆記本表定期更新功能,如每天。如果你已經有一個非正常的工作,你可以將它轉換成一個安排的工作確保特性值總是最新的。
代碼更新表使用一個特征模式=“合並”,如以下示例所示。
fs=FeatureStoreClient()customer_features_df=compute_customer_features(數據)fs。write_table(df=customer_features_df,的名字=“recommender_system.customer_features”,模式=“合並”)
存儲過去值的日常功能
用一個複合主鍵定義一個功能表。包括主鍵的日期。例如,對於一個功能表store_purchases,您可以使用一個複合主鍵(日期,user_id)和分區鍵日期為有效的讀取。
fs。create_table(的名字=“recommender_system.customer_features”,primary_keys=(“日期”,“customer_id”),partition_columns=(“日期”),模式=customer_features_df。模式,描述=“客戶特性”)
然後,您可以創建代碼來讀取從功能表過濾日期感興趣的時期。
您還可以創建一個時間序列特征表通過指定日期作為時間戳列鍵使用timestamp_keys論點。
fs。create_table(的名字=“recommender_system.customer_features”,primary_keys=(“日期”,“customer_id”),timestamp_keys=(“日期”),模式=customer_features_df。模式,描述=“客戶timeseries特征”)
當你使用這使時間點查找create_training_set或score_batch。係統執行的時間戳的加入,使用timestamp_lookup_key你指定。
保持功能表,建立定期工作寫功能,或流新特性值到功能表中。
創建一個流特性計算管道更新功能
創建一個流特性計算管道,通過流媒體DataFrame作為參數write_table。這個方法返回一個StreamingQuery對象。
defcompute_additional_customer_features(數據):“返回流DataFrame“‘通過#沒有顯示customer_transactions=火花。readStream。負載(“dbfs: /事件/ customer_transactions”)stream_df=compute_additional_customer_features(customer_transactions)fs。write_table(df=stream_df,的名字=“recommender_system.customer_features”,模式=“合並”)
從功能表讀取
使用read_table讀特性值。
fs=feature_store。FeatureStoreClient()customer_features_df=fs。read_table(的名字=“recommender.customer_features”,)
搜索和瀏覽功能表
使用該特性存儲UI搜索或瀏覽功能表。
在側邊欄,選擇機器學習>特色商店存儲界麵顯示功能。
在搜索框中,輸入的全部或部分功能表的名稱,功能,或一個數據源用於特性計算。您還可以輸入的全部或部分鍵或值的標簽。搜索文本是不區分大小寫的。


得到特征表元數據
表元數據API獲得功能取決於磚使用運行時版本。v0.3.6和上麵使用get_table。v0.3.5和下麵使用get_feature_table。
#這個例子使用v0.3.6以上# v0.3.5,使用“get_feature_table”從databricks.feature_store進口FeatureStoreClientfs=FeatureStoreClient()fs。get_table(“feature_store_example.user_feature_table”)
工作特性表標簽
標簽是鍵值,您可以創建和使用搜索功能表。您可以創建、編輯和刪除使用特性存儲UI或標簽Python API特性存儲。
 如果尚未打開。標簽表出現。
如果尚未打開。標簽表出現。

工作特性表標簽使用Python特性存儲API
在集群v0.4.1以上運行,您可以創建、編輯和刪除標簽使用Python API特性存儲。
為一個功能表更新數據源
使用的數據源的功能存儲自動跟蹤計算功能。你也可以通過使用手動更新數據源Python API特性存儲。
添加數據源使用Python特性存儲API
下麵是一些示例命令。有關詳細信息,請參見API文檔。
從databricks.feature_store進口FeatureStoreClientfs=FeatureStoreClient()#使用' source_type =“表”中添加一個表metastore作為數據源。fs。add_data_sources(feature_table_name=“點擊”,data_sources=“user_info.clicks”,source_type=“表”)#使用source_type =“路徑”的路徑格式添加一個數據源。fs。add_data_sources(feature_table_name=“user_metrics”,data_sources=“dbfs: / FileStore / user_metrics.json”,source_type=“路徑”)#使用' source_type =“定製”如果源不是一個表或一個路徑。fs。add_data_sources(feature_table_name=“user_metrics”,data_sources=“user_metrics.txt”,source_type=“自定義”)
刪除數據源使用Python特性存儲API
有關詳細信息,請參見API文檔。
請注意
以下命令刪除所有類型的數據源(“表”、“路徑”和“自定義”)相匹配的名字來源。
從databricks.feature_store進口FeatureStoreClientfs=FeatureStoreClient()fs。delete_data_sources(feature_table_name=“點擊”,sources_names=“user_info.clicks”)
刪除一個功能表
你可以刪除一個使用特性存儲用戶界麵或功能表Python API特性存儲。
請注意
刪除功能表可以導致上遊生產商和下遊消費者意想不到的失敗(模型、端點和安排工作)。
當你刪除一個功能表使用API,底層三角洲表也下降了。當你刪除一個UI功能表,你必須單獨刪除底層三角洲表。
刪除一個表使用UI功能
在功能表頁麵,點擊
 在功能表名和選擇的權利刪除。如果你沒有可以管理權限功能表,你不會看到這個選項。
在功能表名和選擇的權利刪除。如果你沒有可以管理權限功能表,你不會看到這個選項。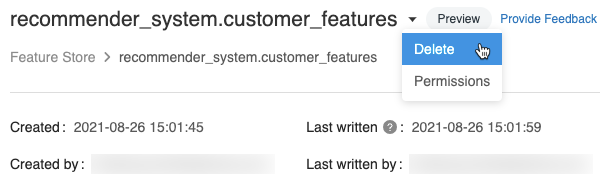
在刪除功能表對話框中,點擊刪除來確認。
如果你也想的話底層三角洲表下降運行以下命令在一個筆記本上。
%sql下降表如果存在<功能- - - - - -表- - - - - -的名字>;
 在功能表名和選擇的權利刪除。如果你沒有可以管理權限功能表,你不會看到這個選項。
在功能表名和選擇的權利刪除。如果你沒有可以管理權限功能表,你不會看到這個選項。
支持的數據類型
支持以下功能商店PySpark數據類型:
IntegerTypeFloatTypeBooleanTypeStringType倍增式LongTypeTimestampTypeDateTypeShortTypeArrayTypeBinaryType(v0.3.5及以上)DecimalType(v0.3.5及以上)MapType(v0.3.5及以上)
上麵列出的數據類型支持特性類型常見的機器學習應用。例如:
你可以儲存密度向量,張量和嵌入的
ArrayType。你可以存儲稀疏向量,張量和嵌入
MapType。你可以存儲文本
StringType。
功能界麵顯示元數據存儲在特性數據類型:

當發布到在線商店,ArrayType和MapType功能是存儲在JSON格式。