在磚使用印度生物技術部轉換工作
您可以運行你的印度生物技術部核心項目作為一個磚的工作任務。通過運行你的印度生物技術部核心項目的工作任務,可以受益於以下磚的工作特點:
自動化你的印度生物技術部任務和進度工作流,包括印度生物技術部工作。
監控你的印度生物技術部轉換並發送通知的狀態轉換。
包括你的印度生物技術部項目與其他任務工作流。例如,您的工作流可以攝取數據與自動加載程序,與印度生物技術部轉換數據,分析數據和一個筆記本電腦的任務。
工件的自動歸檔工作運行,包括日誌,結果,體現和配置。
了解更多關於印度生物技術部核心,看到印度生物技術部的文檔。
開發和生產工作流程
磚建議開發你的印度生物技術部項目磚SQL的倉庫。使用磚SQL的倉庫,可以測試生成的SQL印度生物技術部和倉庫使用SQL查詢曆史調試查詢由印度生物技術部。
在生產運行您的印度生物技術部的轉換,在磚磚推薦使用印度生物技術部的任務工作。默認情況下,印度生物技術部任務將印度生物技術部Python運行過程在一個集群節點工作,和印度生物技術部對選擇生成的SQL SQL倉庫。
您可以運行印度生物技術部在職業轉換SQL倉庫,一個通用的集群,或任何其他dbt-supported倉庫。本文討論了前兩個選項的例子。
請注意
開發印度生物技術部模型對SQL倉庫和生產運行在一個通用的集群性能可能導致細微的差別和SQL語言支持。磚建議使用相同的磚集群運行時版本通用和SQL的倉庫。
需求
學習如何使用印度生物技術部核心和
dbt-databricks包來創建和運行印度生物技術部項目在您的開發環境中,明白了連接到印度生物技術部核心。磚建議dbt-databricks包,而不是dbt-spark包。dbt-databricks包是一個叉的磚dbt-spark優化。
在磚使用印度生物技術部項目工作,必須設置Git與磚回購的集成。你不能運行一個從DBFS印度生物技術部項目。
你必須啟用了SQL倉庫。
你必須有磚的SQL權利。
創建並運行您的第一個印度生物技術部工作
下麵的例子使用了jaffle_shop項目,項目一個例子演示了印度生物技術部核心概念。創建一個工作運行jaffle店項目,執行以下步驟。
去你的磚的著陸頁,做以下之一:
點擊
 工作流在側邊欄,然後單擊
工作流在側邊欄,然後單擊 。
。在側邊欄中,單擊
 新並選擇工作。
新並選擇工作。
在任務出現在對話框任務選項卡中,取代添加一個名稱為你的工作…對你的工作名稱。
在任務名稱為任務,輸入一個名稱。
在類型,選擇印度生物技術部任務類型。
在源,點擊編輯並輸入jaffle商店GitHub庫的詳細信息。
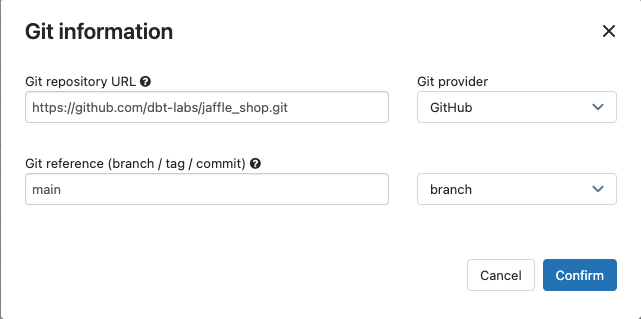
在Git存儲庫URL,輸入的URL jaffle店項目。
在Git參考(分支/標記/提交),輸入
主要。您還可以使用一個標簽或沙。
點擊確認。
在印度生物技術部的命令文本框中,指定印度生物技術部命令來運行(deps,種子,運行)。你必須每個命令前綴
印度生物技術部。命令運行在指定的順序。
在SQL倉庫,選擇一個SQL倉庫運行生成的SQL印度生物技術部。的SQL倉庫下拉菜單顯示隻有serverless和pro SQL倉庫。
(可選)您可以指定一個模式任務的輸出。默認情況下,模式
默認的使用。(可選)如果你想改變集群,印度生物技術部核心運行時,點擊印度生物技術部CLI集群。集群來最小化成本,默認為一個小型的單節點集群。
(可選)可以指定dbt-databricks版本的任務。例如,銷你的印度生物技術部開發和生產任務到一個特定的版本:
下依賴庫,點擊
 當前dbt-databricks旁邊的版本。
當前dbt-databricks旁邊的版本。點擊添加。
在添加依賴庫,單擊PyPI在選項卡並輸入dbt-package版本包文本框(例如,
dbt-databricks = = 1.2.0)。點擊添加。

請注意
磚建議把你的印度生物技術部任務到一個特定版本的dbt-databricks包以確保相同的版本是用於開發和生產運行。磚建議dbt-databricks的1.2.0或更高版本的包。
點擊創建。
現在運行工作,點擊
 。
。
 。
。



 。
。印度生物技術部的工作任務的查看結果
當工作完成後,您可以通過運行SQL查詢的測試結果筆記本或通過運行查詢在你的磚倉庫。例如,參見下麵的示例查詢:
顯示表在<模式>;
選擇*從<模式>。beplay体育app下载地址限製10;
取代<模式>任務配置中配置的模式名。
API的例子
您還可以使用喬布斯API創建和管理工作,包括印度生物技術部工作。下麵的示例創建一個單一的印度生物技術部的工作任務:
{“名稱”:“jaffle_shop印度生物技術部工作”,“max_concurrent_runs”:1,“git_source”:{“git_url”:“https://github.com/dbt-labs/jaffle_shop”,“git_provider”:“gitHub”,“git_branch”:“主要”},“job_clusters”:({“job_cluster_key”:“dbt_CLI”,“new_cluster”:{“spark_version”:“10.4.x-photon-scala2.12”,“node_type_id”:“c2-standard-16”,“num_workers”:0,“spark_conf”:{“spark.master”:“地方(* 4)”,“spark.databricks.cluster.profile”:“singleNode”},“custom_tags”:{“ResourceClass”:“SingleNode”}}}),“任務”:({“task_key”:“轉換”,“job_cluster_key”:“dbt_CLI”,“dbt_task”:{“命令”:(“印度生物技術部deps”,“印度生物技術部種子”,“印度生物技術部運行”),“warehouse_id”:“1 a234b567c8de912”},“庫”:({“pypi”:{“包”:“dbt-databricks > = 1.0.0, < 2.0.0”}}]}]}
(高級)印度生物技術部運行定製的概要文件
與SQL運行你的印度生物技術部任務倉庫(推薦)或一個通用的集群中,使用一個定製的profiles.yml定義倉庫或集群連接。創建一個工作運行jaffle店項目倉庫或一個通用的集群中,執行以下步驟。
請注意
隻可以使用SQL倉庫或一個通用集群作為印度生物技術部的目標任務。你不能使用集群工作作為印度生物技術部的一個目標。
創建一個叉的jaffle_shop存儲庫。
克隆到桌麵的分叉的存儲庫。例如,您可以運行一個命令如下:
git克隆https://github.com/ <用戶名> / jaffle_shop.git
取代
<用戶名>GitHub處理。創建一個新文件
profiles.yml在jaffle_shop目錄包含以下內容:jaffle_shop:目標:databricks_job輸出:databricks_job:類型:磚方法:http模式:“<模式>”主機:“< http host >”http_path:“< http-path >”令牌:”{{env_var (“DBT_ACCESS_TOKEN”)}}”
取代
<模式>與項目的模式名稱表。與SQL運行你的印度生物技術部任務倉庫,替換
< http host >與服務器主機名價值的連接細節為你的SQL選項卡倉庫。印度生物技術部任務運行通用集群,替換< http host >與服務器主機名價值的高級選項,JDBC / ODBC集群選項卡為你的磚。與SQL運行你的印度生物技術部任務倉庫,替換
< http-path >與HTTP路徑價值的連接細節為你的SQL選項卡倉庫。印度生物技術部任務運行通用集群,替換< http-path >與HTTP路徑價值的高級選項,JDBC / ODBC集群選項卡為你的磚。
你沒有指定的秘密,比如訪問令牌,在文件中,因為你要檢查這個文件源代碼控製。相反,這個文件使用印度生物技術部在運行時動態地插入憑證模板功能。
請注意
期間生成的證書是有效的,最多30天,完成後將自動撤銷。
檢查這個文件到Git並把它發送到你的倉庫。例如,您可以運行命令如下:
git添加配置文件。yml git commit - m“添加配置文件。yml磚的工作”git推點擊
工作流側邊欄的磚UI。選擇並單擊印度生物技術部工作任務選項卡。
在源,點擊編輯並輸入你的叉形jaffle商店GitHub庫的細節。
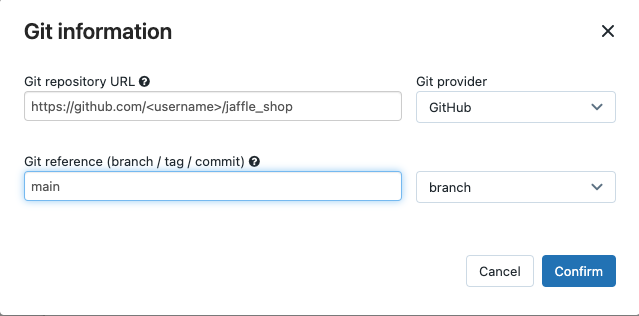
在SQL倉庫中,選擇沒有(手動)。
在配置文件目錄,輸入目錄包含的相對路徑
profiles.yml文件。離開路徑值留空,使用默認的存儲庫的根。

(高級)使用印度生物技術部Python在工作流模型
請注意
印度生物技術部支持Python模型是處於測試階段,需要印度生物技術部1.3或更高版本。
印度生物技術部現在支持Python模型在特定的數據倉庫,包括磚。印度生物技術部Python模型,您可以使用Python的生態係統來實現轉換的工具很難實現使用SQL。您可以創建一個磚的工作和你的印度生物技術部Python運行一個任務模型,或者你可以包括印度生物技術部任務作為一個工作流,包括多個任務的一部分。
你不能在印度生物技術部任務使用一個SQL運行Python模型倉庫。更多信息關於使用印度生物技術部Python模型與磚,明白了特定的數據倉庫印度生物技術部的文檔。