穀歌雲存儲
本文描述如何從Databricks中的穀歌雲存儲(GCS)表中讀取和寫入數據。對GCS桶進行讀寫操作時,需要創建綁定的服務帳戶,並在創建集群時關聯該桶和服務帳戶。
使用為服務帳戶生成的密鑰直接連接到桶。
直接訪問GCS桶
要直接讀寫存儲桶,需要配置定義在火花配置.
步驟1:使用穀歌雲控製台設置穀歌雲服務帳號
需要為Databricks集群創建一個服務帳號。Databricks建議給這個服務帳戶最少的權限來執行它的任務。
點擊我和管理在左側導航窗格中。
點擊服務帳戶.
點擊+創建服務帳戶.
輸入業務帳戶名稱和描述。
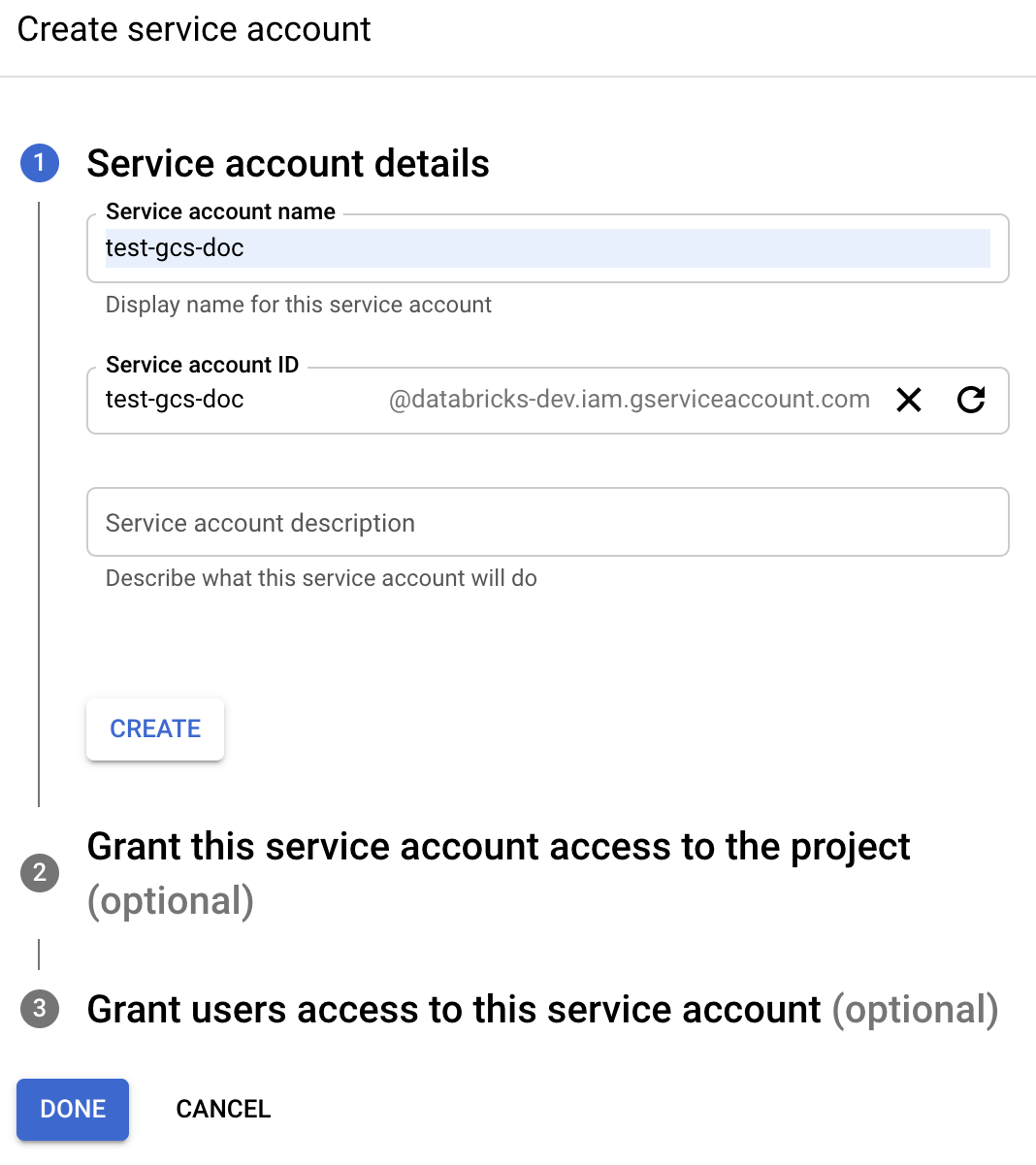
點擊創建.
點擊繼續.
點擊完成.
創建一個密鑰。看到創建直接訪問GCS桶的密鑰.





步驟3:搭建Databricks集群
當你配置您的集群:
在磚的運行時版本的下拉,選擇7.3 LTS或以上。
在火花配置選項卡,添加以下所有Spark配置。取代
< client_email >,< project_id >,< private_key >,< private_key_id >使用來自關鍵JSON文件的準確字段名的值。重要的
的值
< private_key >跨越多個行。粘貼整個私鑰。不要包含開頭和結尾的引號。spark.hadoop.google.cloud.auth.service.account.enable真實spark.hadoop.fs.gs.auth.service.account.email < client_email >spark.hadoop.fs.gs.project.id < project_id >spark.hadoop.fs.gs.auth.service.account.private.key < private_key >spark.hadoop.fs.gs.auth.service.account.private.key.id < private_key_id >
步驟4:使用
要從GCS桶中讀取,使用Spark read命令以任何支持的格式,例如:
df=火花.讀.格式(“鋪”).負載(“gs: / / < bucket名> / <路徑>”)
要寫入GCS桶,可以使用Spark的任何支持格式的寫命令,例如:
df.寫.格式(“鋪”).模式(“< >模式”).保存(“gs: / / < bucket名> / <路徑>”)
取代< bucket名>使用您在其中創建的桶的名稱步驟2:配置GCS桶.