最初公布的4月14日,2020;2020年4月21日更新
與當前的大規模破壞COVID-19大流行,許多數據工程師和科學家正在自問“社區的數據能幫上什麼忙?”的data community is already doing some amazing work in a short amount of time including (but certainly not limited to) one of the most commonly used COVID-19 data sources:2019年新型冠狀病毒COVID-19 (2019 - ncov)由約翰霍普金斯CSSE數據存儲庫。以下比例的GIF動畫是一個可視化表示的確診病例(縣)和死亡人數(圓圈)跨越從3月22日到4月14日。
https://www.youtube.com/watch?v=QjFZQyK2i2w
其他的例子包括新型冠狀病毒的基因組流行病學提供實時跟蹤病原體的進化(點擊傳輸和發展史)。
圖2:來源:基因流行病學新型冠狀病毒(2020-04-08)
醫院資源利用率的一個強有力的例子包括建模華盛頓大學研究所的健康和指標評價(健康)COVID-19預測。截圖提供預測醫院資源利用率指標,強調峰值資源使用3月28日,2020年。
(2020-04-08)
但我能幫什麼忙嗎?
我們相信,克服COVID-19此刻是世界上最困難的問題,並幫助做出重要決定,重要的是要理解底層數據。我們已經采取措施使任何人——從第一次data explorers數據專業人員參與工作。
3月下旬,我們開始COVID-19數據集的數據分析引物與我們的技術討論分析COVID-19:社區的數據可以幫助嗎?在這個會話中,我們進行了探索性數據分析和自然語言處理(NLP)各種開源項目,包括但不限於Apache火花™,Python,熊貓,伯特。我們也有這些筆記本電腦供你下載和使用環境的選擇,是否這是你自己的本地Python虛擬環境,雲計算,或磚社區版。
例如,我們分析了在此會話COVID-19開放研究數據集的挑戰(CORD-19)數據集和觀察:
- 有成千上萬的JSON文件,每個文件包含研究論文文本的細節包括引用。JSON模式的複雜性可以處理這些數據一個複雜的任務。幸運的是,Apache火花可以快速和自動推斷這些JSON文件和使用的模式這個筆記本,我們將成千上萬的JSON文件保存到幾鋪文件方便隨後的探索性數據分析。
- 本文的大多數是無結構的,有數據質量問題包括(但不限於)正確地識別的主要作者的國家。在這個筆記本,我們提供的步驟清除這個數據和識別ISOα3國家代碼我們可以隨後地圖論文主要作者的國家的數量。
- 在清理數據,我們可以獲得各種NLP算法應用於一些洞察力和直覺到這個數據。這個筆記本執行各種任務,包括概括論文摘要(一個紙從7800到1100個字符),以及創建下列詞雲基於這些研究論文的標題。
給我的數據!
像大多數數據分析師、工程師和科學家將證明,您的數據的質量有一個強大的影響你的探索性數據分析。正如一些有用的東西了解機器學習(2012年10月):
“一個愚蠢的算法用很多很多的數據比一個聰明的人一些。”
重要的是要注意,這句話強調的重要性有大量高質量的數據而不是瑣碎的機器學習的其他重要方麵,例如(但不限於)特性工程的重要性和數據僅是不夠的。
許多數據社區繼續工作方便地提供各種SARS-CoV-2(原因)和COVID-19(疾病)Kaggle和GitHub包括數據集。
方便你進行分析——如果你使用磚或磚社區版——我們是定期更新和提供各種COVID-19研究數據集(非商業)的目的。我們正在刷新數據集後,我們計劃增加更多的結束時間:
學習更多的與我們的探索性數據分析研討會
由於積極的反饋從我們技術討論後,我們很高興地宣布了一係列研討會在Python與COVID-19探索性數據分析數據集。在YouTube上的視頻可以和筆記本都可以https://github.com/databricks/tech-talks為你選擇的在您的環境中使用。
這個車間顯示您所需要的簡單的步驟程序在Python中使用一個筆記本環境自由磚Community Edition。Python是一種流行的編程語言,因為它廣泛的應用程序,包括數據分析、機器學習和web開發。本研討會涵蓋了主要的基本概念開始編碼在Python中,專注於數據分析。您將了解不同類型的變量,對循環、函數和條件語句。不需要任何編程知識。
誰應該參加這個研討會:任何人,每個人,CS學生甚至非技術人歡迎加入。不需要任何編程知識。如果你有了Python課程在過去,這對你可能太基本。

這個車間關注大熊貓,為數據分析和處理功能強大的開源Python包。在這個車間,您將了解如何讀取數據,計算彙總統計數據,檢查數據分布,進行基本的數據清洗和轉換,情節簡單的數據可視化。我們將使用約翰霍普金斯大學係統科學與工程中心(CSSE)新型冠狀病毒(COVID-19)數據集。
誰應該參加這個研討會:任何人和每個人都- CS學生甚至非技術人歡迎加入。基本的Python經驗建議。
你需要什麼:雖然不需要準備工作,我們所做的推薦基本的Python知識。如果你是新到Python,一個偉大的開始是我們的介紹了Python教程。

scikit-learn是機器學習的一個最流行的開源庫數據科學的實踐者。這個車間走過機器學習的基本知識,不同類型的機器學習,以及如何構建一個簡單的機器學習模型。本研討會的重點是技術應用和評估的機器學習方法,而不是背後的統計概念。我們將使用公布的數據約翰霍普金斯大學係統科學與工程中心(CSSE)新型冠狀病毒(COVID-19)。
誰應該參加這個研討會:任何人和每個人都- CS學生甚至非技術人歡迎加入。基本的Python和熊貓經驗是必需的。如果你是新到Python和熊貓,看介紹了Python教程和注冊數據分析與熊貓教程。

本研討會討論Apache火花的基本麵,最受歡迎的大數據處理引擎。在這個車間,您將學習如何攝取數據與火花,分析引發的UI,並更好地了解分布式計算。我們將使用公布的數據紐約時報。不需要先驗知識的火花,但Python經驗是強烈推薦。
誰應該參加這個研討會:任何人和每個人都- CS學生甚至非技術人歡迎加入。基本的Python和熊貓經驗是必需的。如果你是新到Python和熊貓,看介紹了Python教程。

獲得了一些洞察COVID-19數據集
幫助你啟動COVID-19數據集的分析,我們還包含額外的筆記本技術講座/樣品文件夾的紐約時報COVID-19數據集和2019年的小說《冠狀病毒COVID-19 (2019 - ncov)由約翰霍普金斯CSSE數據存儲庫(可用和定期刷新/ databricks-datasets / COVID)。
的紐約時報COVID-19分析筆記本包括分析COVID-19病例和死亡的縣。
圖6:比例COVID-19病例為華盛頓州前十縣強調教育設施關閉時(來源:紐約時報COVID-19數據截止到4月14日,2020)
圖7:比例COVID-19病例為紐約州十強縣強調教育設施關閉時(來源:紐約時報COVID-19數據截止到4月14日,2020)
一些觀察的基礎上JHU COVID-19分析筆記本電腦包括:
- 截至4月11日,2020年的模式JHU COVID-19日報報道已經改變了三次。前麵的筆記本包含一個腳本,遍曆每個文件,提取文件名(獲取日期),並一起合並三種不同的模式。
- 它包括牽牛星可視化可視化的指數增長COVID-19相關病例和死亡的數量在美國通過滑塊條靜態和動態。
COVID-19確診病例(縣)和死亡(緯度、經度)使用Altair等值線圖地圖在3/22和4/11 /約翰霍普金斯COVID-19數據集
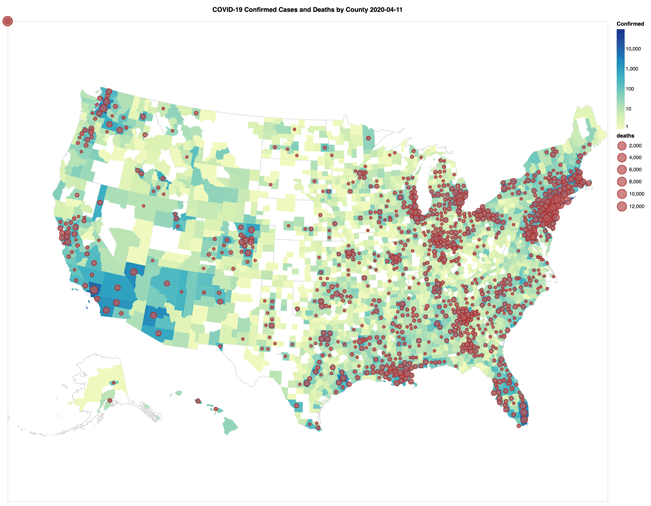
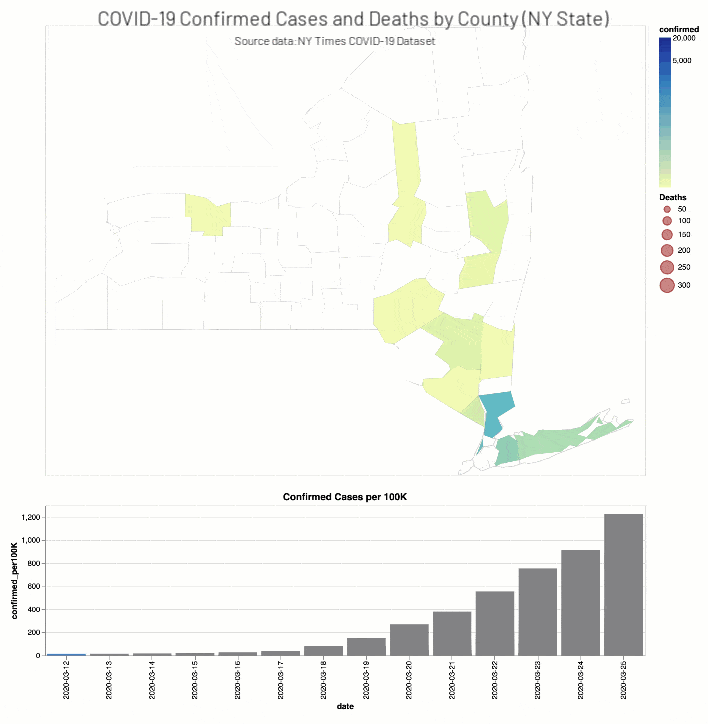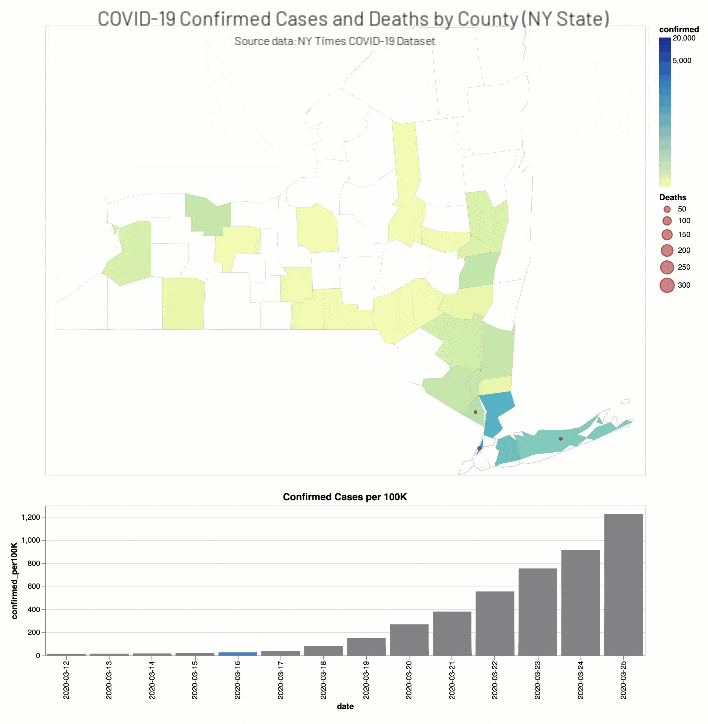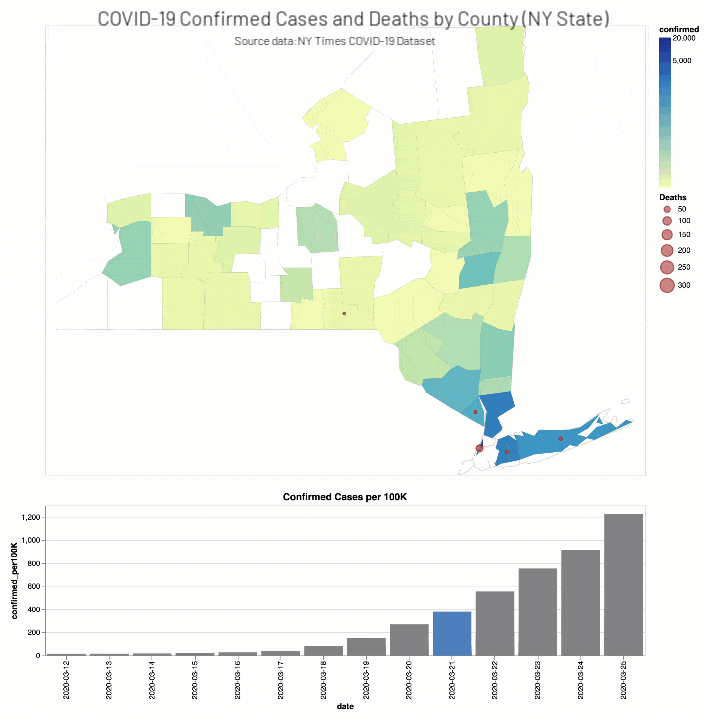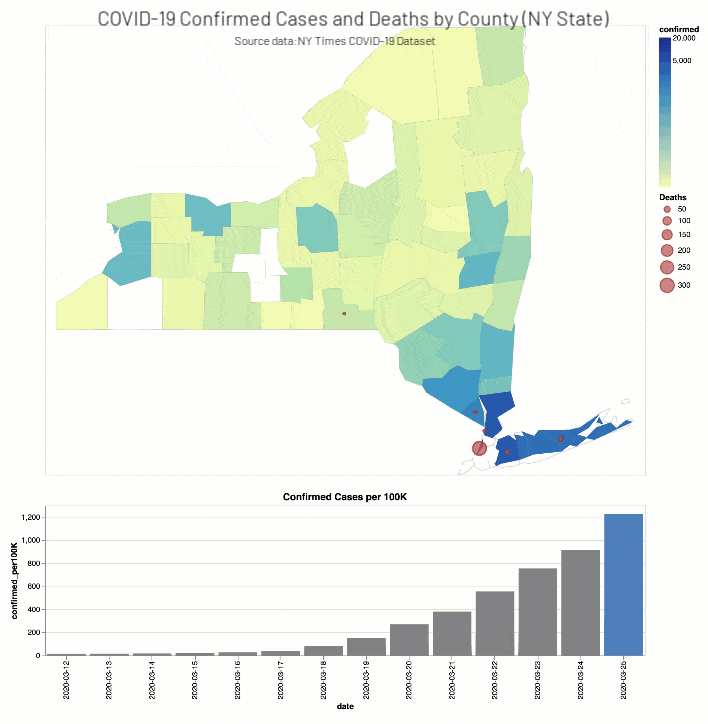
同時,紐約時報COVID-19分析筆記本包括縣等值線圖地圖和酒吧圖表COVID-19確診病例和死亡(實際和分別與人口成正比)為期兩周的窗口在當教育設施因華盛頓(2020年3月13日)和紐約(2020年3月18日)。
實際和比例COVID-19確診病例(縣)和死亡(緯度、經度)為期兩周的窗口在教育設施閉包使用Altair等值線圖地圖和酒吧圖表/紐約時報COVID-19數據集
討論
社區可以幫助在這個流行的數據提供至關重要的有關數據背後的模式:增長率確診病例和死亡人數在每個縣,對經濟增長的影響,國家應用社會距離,了解我們受到社會距離的平曲線,等。而在其核心,COVID-19是一個醫學問題,即我們如何拯救病人的生命,它也是流行病學問題理解數據將幫助醫學界做出更好的決策,如我們如何使用數據作出更好的公共衛生政策來阻止人們成為病人。
O ' reilly學習引發的書
3.0免費第二版包括更新火花,包括熊貓udf的新的Python類型提示,新的日期/時間實現等。