
Hadoop分布式文件係統(HDFS)

HDFS
HDFS (Hadoop分布式文件係統)是主要的存儲係統由Hadoop應用程序使用。這種開源框架是通過迅速節點之間傳輸數據。它常常被公司需要處理和存儲大數據。HDFS許多Hadoop係統是一個關鍵組成部分,因為它提供了一種方法來管理大數據,以及支持大數據分析。
有許多公司在全球範圍內,使用HDFS,那麼它到底是什麼,為什麼需要它?讓我們來深入了解HDFS是什麼和為什麼它可能是有用的企業。
HDFS是什麼?
HDFS代表Hadoop分布式文件係統。HDFS運行作為一個分布式文件係統設計的硬件上運行。
HDFS容錯和設計是部署在低成本、商品硬件。HDFS提供高吞吐量數據訪問應用程序數據,適用於大型數據集,使流媒體應用程序訪問文件係統中的數據Apache Hadoop。
所以,Hadoop是什麼?從HDFS如何變化?核心區別Hadoop的HDFS是Hadoop是開源框架,它可以存儲,處理和分析數據,而HDFS的Hadoop文件係統提供對數據的訪問。這基本上意味著Hadoop的HDFS是一個模塊。
讓我們看看HDFS架構:

正如我們所看到的,它關注namenode, datanode。NameNode是包含GNU / Linux操作係統的硬件和軟件。Hadoop分布式文件係統充當主服務器可以管理文件,控製客戶的訪問文件,和海外文件重命名等操作流程,打開和關閉文件。
一個DataNode硬件的GNU / Linux操作係統和DataNode軟件。對於在HDFS集群中的每個節點,您將找到一個DataNode。這些節點幫助控製他們的數據存儲係統,因為他們可以在文件係統上執行操作,如果客戶端請求,以及創建、複製和塊文件當NameNode指示。
HDFS的意義和目的是實現以下目標:
- 管理大型數據集——組織和存儲數據集可以是一個很難處理的討論。HDFS被用來管理應用程序必須處理巨大的數據集。為此,HDFS應該數百每個集群節點。
- 檢測故障——HDFS應該技術來掃描和檢測故障快速、有效,因為它包含大量的商品硬件。失敗的組件是一個常見的問題。
- 硬件效率——當涉及大型數據集可以減少網絡流量,提高處理速度。
HDFS的曆史
Hadoop的起源是什麼?HDFS的設計是基於Google文件係統。最初是作為Apache Nutch基礎設施建造的web搜索引擎項目但已經成為的一員Hadoop生態係統。
在早些年的互聯網,網絡爬蟲開始流行,人們搜索web頁麵上的信息。這創造了各種搜索引擎如雅虎和穀歌。
它還創建了另一個搜索引擎Nutch,想同時分發數據跨多個計算機和計算。Nutch然後搬到雅虎,並分為兩個。Apache Hadoop火花,現在自己的獨立的實體。Hadoop是設計用於處理批處理,火花是有效地處理實時數據。
如今,Hadoop的結構和框架由Apache軟件基金會管理這是一個全球社區的軟件開發人員和貢獻者。
HDFS出生,旨在取代硬件存儲解決方案與一個更好的,更有效的方法——虛擬文件係統。當它第一次到現場,MapReduce是唯一的分布式處理引擎,可以使用HDFS。最近,替代Hadoop數據服務組件(比如HBase和Solr還利用HDFS來存儲數據。
HDFS的大數據是什麼?
那麼,什麼是大數據和HDFS如何進入呢?“大數據”一詞指的是所有的數據難以儲存,處理和分析。HDFS大數據是數據組織成HDFS文件係統。
我們現在知道,Hadoop是一個框架,通過使用並行處理和分布式存儲工作。這可以用來存儲大數據,因為它不能存儲在傳統的生產方式。
事實上,它是最常用的軟件來處理大數據,並使用Netflix等公司Expedia,英國航空公司(British Airways)有積極的人使用Hadoop的關係數據存儲。HDFS在大數據是至關重要的,因為這是現在許多企業選擇如何存儲數據。
有五個核心元素的大數據由HDFS服務:
- 速度生成速度數據,整理和分析。
- 體積生成的數據量。
- 各種的數據類型,這可能是結構化、非結構化等。
- 真實性——數據的質量和準確性。
- 價值——如何使用這些數據將一個洞察你的業務流程。
Hadoop分布式文件係統的優點
內的一個開源子項目Hadoop, HDFS提供五個核心利益在處理大數據:
- 容錯。HDFS被設計來檢測故障並自動恢複迅速確保連續性和可靠性。
- 速度,因為它的集群架構,它可以維持每秒2 GB的數據。
- 對更多類型的數據的訪問,特別是流媒體數據。因為它的設計來處理大量數據的批處理它允許高數據吞吐率使它理想流數據的支持。
- 兼容性和可移植性。HDFS被設計為跨多種硬件設置和移植兼容多個底層操作係統最終用戶提供可選性使用HDFS自己定製的設置。這些優勢尤為重要在處理大數據,用特定的方式HDFS處理數據成為可能。
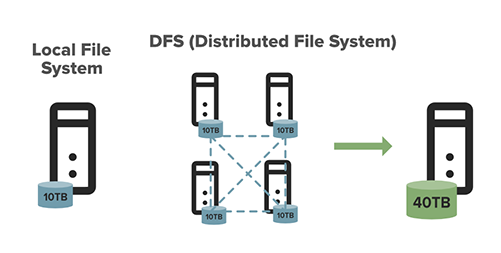
這個圖展示了一個本地文件係統和HDFS的區別。
- 可伸縮的。您可以擴展資源根據您的文件係統的大小。HDFS包括垂直和水平可伸縮性的機製。
- 數據本地化。在Hadoop文件係統,數據駐留在數據節點,而不是數據移動到計算單元的位置。通過縮短之間的距離數據和計算過程,減少網絡擁塞,使係統更加有效和高效。
- 成本效益。最初,我們認為數據時我們可能認為昂貴的硬件和帶寬占用。硬件故障發生時,它可以是非常昂貴的修複。HDFS,數據存儲廉價的虛擬,可大大減少文件係統元數據和文件係統名稱空間數據存儲成本。更重要的是,因為HDFS是開源的,企業不需要擔心需要支付許可費用。
- 存儲大量的數據。數據存儲是HDFS是什麼——這意味著數據的所有品種和大小——尤其是大量數據從企業正在努力儲存它。這包括結構化和非結構化數據。
- 靈活的。不像其他更傳統的存儲數據庫,不需要處理數據之前收集存儲它。你能夠存儲你想要盡可能多的數據,有機會決定你想做什麼以及如何使用它。這也包括非結構化數據如文本、視頻和圖片。

如何使用HDFS
那麼,如何使用HDFS嗎?HDFS與一個主要NameNode和多個其它datanode所有商品硬件集群上。這些節點在同一個地方組織在數據中心內。接下來,它的分解成塊分布在多個datanode用於存儲。為了減少數據丟失的可能性,塊往往跨節點複製。這是一個備份係統數據應該丟失。
讓我們看看namenode。NameNode是集群中的節點知道數據包含什麼,阻止它屬於什麼,塊大小,它應該去的地方。namenode也用於訪問控製文件包括當有人能寫,讀,創建、刪除和複製數據在各種數據筆記。
實時集群也可以適應在必要時,根據服務器容量時——這可能是有用的數據激增。節點可以在必要時添加或帶走。
現在,datanode上。datanode在不斷的交流與namenode確定他們是否需要開始和完成一項任務。這一致的協作流意味著NameNode是敏銳地意識到每個datanode的地位。
當一個DataNode指出不會操作它應該的方式,namemode能夠自動重新分配任務到另一個功能節點在同一個datablock。同樣,datanode也能夠相互通信,這意味著他們可以合作在標準文件操作。因為NameNode知道datanode和他們的表現,他們在維護係統至關重要。
Datablocks複製多個datanotes NameNode和訪問。
使用HDFS需要安裝和設置一個Hadoop集群。這可能是一個單獨的節點設置,哪個更適合第一次使用或集群設置大型分布式集群。你需要熟悉HDFS命令,如以下,操作和管理係統。
命令 |
描述 |
rm |
刪除文件或目錄 |
- ls |
列表文件權限和其他細節 |
mkdir |
創建一個名為路徑的目錄在HDFS |
貓 |
顯示文件的內容 |
刪除文件夾 |
刪除一個目錄 |
—— |
上傳一個文件或文件夾從本地磁盤到HDFS |
-rmr |
刪除文件的路徑或文件夾和子文件夾 |
在閑暇 |
移動文件或文件夾從HDFS到本地文件 |
數 |
計數的文件數量,數量的目錄和文件大小 |
df |
顯示了自由空間 |
-getmerge |
在HDFS合並多個文件 |
修改文件權限 |
修改文件權限 |
-copyToLocal |
將文件複製到本地係統 |
統計 |
打印文件或目錄統計信息 |
——頭 |
顯示第一個千字節的文件 |
使用 |
返回一個單獨的命令的幫助 |
喬恩 |
分配一個新文件的所有者和組 |
HDFS是如何工作的呢?
如前所述,HDFS使用namenode和datanode。HDFS允許快速計算節點之間傳輸的數據。HDFS接收數據時,它能夠將信息分解成塊,分發給不同的集群中的節點。
數據分解成塊,分布在datanode存儲,這些塊也可以跨節點複製它允許高效的並行處理。你可以訪問、移動通過各種命令和視圖數據。HDFS DFS選項等“-”和“——”允許您檢索和移動數據。
更重要的是,HDFS被設計成高度警覺和可以快速檢測故障。文件係統使用數據複製,確保每一塊數據多次保存,然後分配在各個節點,保證至少有一份是比其他副本不同的架子上。
這意味著當一個DataNode NameNode不再發送信號,它消除了DataNode的集群和運營沒有它。如果這個數據節點然後回來,它可以被分配給一個新的集群。加上,因為datablocks跨幾個datanode複製,刪除一個不會導致任何類型的任何文件錯誤了。
HDFS組件
重要的是要知道Hadoop有三個主要組成部分。Hadoop的HDFS, Hadoop MapReduce和Hadoop紗。讓我們來看看這些組件將Hadoop:
- Hadoop的HDFSHadoop分布式文件係統(HDFS) Hadoop的存儲單元。
- Hadoop MapReduce——Hadoop MapReduce是Hadoop的處理單元。此軟件框架用於編寫應用程序來處理大量的數據。
- Hadoop紗——Hadoop Hadoop的紗是一種資源管理組件。流,批處理流程和運行數據交互和圖形處理——所有這一切都是存儲在HDFS中。
如何創建一個HDFS文件係統
想知道如何創建HDFS文件係統?遵循以下步驟將指導您如何創建係統,編輯它,如果需要刪除它。
清單你HDFS
你的清單應該HDFS/ user / yourUserName。要查看HDFS的主目錄的內容,輸入:
hdfs dfs - ls當你剛剛開始,你將無法看到任何在這個階段。當你想要查看一個非空目錄的內容,輸入:
hdfs dfs- - - - - -ls/用戶你可以看到的名字其他Hadoop用戶的主目錄。
在HDFS中創建一個目錄
您現在可以創建一個測試目錄,我們叫它testHDFS。它將會出現在你的HDFS。隻要輸入以下:
hdfs dfs mkdir testHDFS現在你必須驗證時輸入的目錄存在通過使用命令清單你的HDFS。您應該看到testHDFS目錄列出。
驗證一遍使用HDFS HDFS完整路徑名。輸入:
hdfs dfs- - - - - -ls/用戶/yourUserName仔細檢查,這是在你工作的下一個步驟。
複製一個文件
從您的本地文件係統複製一個文件到HDFS,首先創建一個文件你想複製。要做到這一點,輸入:
回聲“HDFS測試文件”> >測試文件這將創建一個新文件稱為測試文件,包括字符HDFS測試文件。為了驗證這一點,輸入:
ls
然後創建驗證文件,輸入:
貓測試文件然後,您將需要將文件複製到HDFS。從Linux到HDFS複製文件,您需要使用:
hdfs dfs -copyFromLocal測試文件請注意,您必須使用該命令“-copyFromLocal”因為命令“- cp”用於在HDFS中複製文件。
現在你隻需要確認文件正確複製。通過輸入以下:
代碼> hdfs dfs - lshdfs dfs貓測試文件移動和複製文件
當複製測試文件放入基地主目錄。現在你可以移動它到testHDFS目錄中你已經創建。使用以下:
hdfs dfs mv測試文件testHDFShdfs dfs - lshdfs dfs - ls testHDFS /第一部分搬到你的測試文件從HDFS測試創建一個主目錄。這個命令之後的第二部分告訴我們,它不再是HDFS主目錄,和第三部分證實,現在已經搬到測試HDFS目錄。
複製一個文件,輸入:
hdfs testHDFS dfs - cp /測試文件testHDFS / testFile2hdfs dfs - ls testHDFS /檢查磁盤使用情況
檢查磁盤空間是非常有用的,當你使用HDFS。要做到這一點,你可以輸入以下命令:
hdfs dfs在這將會讓你看到你在HDFS使用多少空間。您還可以查看多少空間可以在HDFS跨集群通過輸入:
hdfs dfs df刪除一個文件/目錄
可能會有一段時間當你需要HDFS中刪除一個文件或目錄。這可以通過命令來實現:
hdfs dfs rm testHDFS /測試文件hdfs dfs - ls testHDFS /你會發現你還有testHDFS目錄,testFile2吃剩的創建。刪除目錄通過輸入:
hdfs dfs刪除文件夾testhdfs它會彈出一個錯誤信息——但不要恐慌。好像會讀“刪除文件夾:testhdfs:目錄非空”。目錄需要空才能被刪除。您可以使用“rm”命令來繞過這和刪除一個目錄包括所有它所包含的文件。輸入:
hdfs dfs rm - r testHDFShdfs dfs - ls如何安裝HDFS
安裝Hadoop,你需要記住,有一個singlenode和多節點。取決於您需要,您可以使用singlenode或多節點集群。
單個節點集群意味著隻有一個DataNode正在運行。它將包括NameNode, DataNode,資源管理器,一台機器上和節點管理器。
對某些行業來說,這是所有我需要做的。例如,在醫療領域,如果你進行研究,需要收集,分類,和過程數據序列,你可以使用一個singlenode集群。這可以很容易地處理數據規模較小,相對於數據分布在許多數以百計的機器。安裝一個singlenode集群,遵循這些步驟:
- 下載Java 8包。保存這個文件在您的主目錄。
- 提取Java Tar文件。
- Hadoop 2.7.3包下載。
- 提取Hadoop tar文件。
- 在bash中添加Hadoop和Java路徑文件(. bashrc)。
- Hadoop編輯配置文件。
- 開放的核心位點。xml和編輯屬性。
- 編輯hdfs-site.xml和編輯屬性。
- 編輯mapred-site.xml文件和編輯屬性。
- 編輯yarn-site.xml和編輯屬性。
- 編輯hadoop-env.sh並添加Java路徑。
- NameNode Hadoop主目錄和格式。
- 去hadoop-2.7.3 / sbin目錄和所有守護進程的開始。
- 檢查所有Hadoop服務正在運行。
你擁有它,你現在應該有一個成功安裝的HDFS。
如何訪問HDFS文件
將不足為奇安全緊張在HDFS,鑒於我們處理數據。HDFS虛擬存儲技術,它跨越集群所以你隻能看到在您的文件係統的元數據,您無法查看實際的具體數據。
訪問HDFS文件可以下載“罐子”從HDFS文件到你的本地文件係統。您還可以訪問HDFS使用它的web用戶界麵。隻是打開你的瀏覽器和類型“localhost: 50070”搜索欄。從這裏,您可以看到HDFS的web用戶界麵和移動工具選項卡在右邊。然後點擊“瀏覽文件係統,“這顯示了一個完整的列表的文件位於您的HDFS。
HDFS DFS的例子
下麵是一些最常見的Hadoop命令的例子。
一個例子
刪除一個目錄您需要應用以下(注意:這個隻能如果文件是空的):
Hadoop美元fs刪除目錄/目錄- name或
hdfs美元dfs刪除目錄/目錄- name例B
當你有多個文件在一個HDFS中,您可以使用一個“-getmerge”命令。這將多個文件合並成一個文件,你可以下載到你的本地文件係統。你可以用以下:
Hadoop fs美元- - - - - -getmerge [- - - - - -問)/源/當地的- - - - - -目的地或
hdfs dfs美元- - - - - -getmerge [- - - - - -問)/源/當地的- - - - - -目的地示例C
當你想要從HDFS本地上傳文件,您可以使用“——”命令。你指定你想複製的地方,什麼文件你想複製到HDFS。使用以下:
Hadoop fs美元- - - - - -把/當地的- - - - - -文件- - - - - -路徑/hdfs- - - - - -文件- - - - - -路徑或
hdfs dfs美元- - - - - -把/當地的- - - - - -文件- - - - - -路徑/hdfs- - - - - -文件- - - - - -路徑例D
伯爵命令用來跟蹤目錄的數量,在HDFS文件和文件大小。您可以使用以下:
Hadoop fs計數/ hdfs-file-path美元或
hdfs dfs計數/ hdfs-file-path美元例如E
“喬恩”命令可以用來改變文件的所有者和組。激活,使用以下:
Hadoop fs美元- - - - - -喬恩(- - - - - -R][所有者][:(集團]]hdfs- - - - - -文件- - - - - -路徑或
hdfs dfs美元- - - - - -喬恩(- - - - - -R][所有者][:(集團]]hdfs- - - - - -文件- - - - - -路徑HDFS存儲是什麼?
我們現在知道,HDFS數據存儲在稱為塊。這些模塊是數據的最小單位,可以存儲的文件係統上。文件處理和分解成這些塊,然後采取跨集群和分布式,也為安全複製。通常,每一塊可以被複製三次。這個圖表顯示了大數據,以及它如何可以存儲在HDFS。

第一個DataNode上你會發現,第二個是存儲在一個單獨的DataNode在集群中,三分之一是存儲在一個DataNode在不同的集群。這就像一個三重保護安全的步驟。因此,如果最壞的應該發生,一個副本失敗,數據不是一去不複返了。
NameNode保留重要的信息,如塊的數量和副本存儲的地方。相比之下,一個DataNode存儲實際數據,並可以創建模塊,刪除模塊,和複製命令塊。它看起來像這樣:
在hdfs-site.xmldfs.NameNode.name.dirfile:/ Hadoop /hdfs / NameNodedfs.DataNode.data.dir文件:/ Hadoop /hdfs / DataNodeDfs.DataNode.data.dir這決定了datanode應該存儲塊。
HDFS存儲數據如何?
HDFS文件係統由一組主服務(NameNode,二級NameNode, datanode)。NameNode和二級NameNode HDFS元數據管理。datanode主機底層HDFS數據。
NameNode追蹤哪些datanode包含在HDFS給定文件的內容。HDFS文件分為塊和DataNode商店每一塊。多個datanode與集群。NameNode然後分發這些跨集群數據塊的副本。它還指示用戶或應用程序在哪裏找到想要的信息。
什麼是Hadoop分布式文件係統(HDFS)用於處理?
簡單地說,當問“什麼是Hadoop分布式文件係統設計來處理?”The answer is first and foremost - big data. This can be invaluable to large corporations that would otherwise struggle to manage and store data from their business and customers.
使用Hadoop,您可以存儲和統一數據,無論是事務性、科學、社會媒體,廣告,和機器。這也意味著你可以回到這個數據和業務性能的有價值的見解和分析。
用來存儲數據,HDFS還可以處理原始數據常用的科學家或那些在醫療領域來分析這些數據。這些被稱為數據湖泊。它允許他們應對更加困難的問題沒有限製。
更重要的是,因為Hadoop主要是設計來處理大量數據以不同的方式,它也可以用來運行算法進行分析。這意味著它可以幫助企業更有效地處理和分析數據,使他們能夠發現新的趨勢和異常。某些數據集甚至被從數據倉庫和搬到Hadoop刪除。它隻是讓它更容易存儲一切都放在一個方便的地方。
當涉及到事務數據,Hadoop還具備處理數以百萬計的事務。由於其存儲和處理能力,它可以用來存儲和分析客戶數據。你也可以深入探究數據發現新興的趨勢和模式來幫助業務目標。別忘了,Hadoop是不斷更新最新數據,你可以比較新老數據看到發生了什麼變化,及其原因。
考慮與HDFS
默認情況下,HDFS是配置了3 x複製這意味著數據集將有兩個額外的副本。雖然這可以提高局部數據在處理的可能性,它引入的開銷存儲成本。
- HDFS配置了本地連接的存儲時效果最好。這樣可以確保文件係統的最佳性能。
- 增加HDFS的能力需要添加新的服務器(計算、內存、磁盤),不僅僅是存儲介質。
HDFS與雲對象存儲
如上所述,HDFS能力是緊密耦合的計算資源。增加存儲容量需要增加CPU資源,盡管後者不是必需的。HDFS當添加更多的數據節點,重新平衡操作需要將現有的數據分發給新添加的服務器。
這個操作可能要花費一些時間。擴展Hadoop集群在本地環境中也可以從成本和空間角度是很困難的。HDFS使用本地連接的存儲提供IO性能優勢假設紗線可以提供處理服務器上存儲的數據被處理。
與大量利用環境,可能大多數數據讀/寫操作將通過網絡與本地。雲湖對象存儲Azure等包括技術數據存儲,AWS S3,或者穀歌雲存儲。獨立的計算資源,訪問它,因此顧客可以在雲存儲的數據量更大。beplay体育app下载地址
beplay体育app下载地址客戶正在尋找價值pb的數據存儲在雲對象存儲可以很容易地這樣做。然而,所有針對雲存儲的讀和寫操作將在網絡上。因此,重要的是,應用程序可以訪問其數據盡可能利用緩存或包括邏輯最小化IO操作。