創建集群
請注意
這些說明用於更新後的創建集群UI。單擊,切換到原有的創建集群界麵用戶界麵預覽在創建集群頁麵的頂部,並將設置切換為關閉。有關遺留UI的文檔,請參見配置集群.有關新的和舊的集群類型的比較,請參見集群UI更改和集群訪問模式.
本文解釋了在創建和編輯Databricks集群時可用的配置選項。重點介紹了如何使用UI創建和編輯集群。其他方法請參見集群CLI,集群API 2.0,Databricks Terraform提供商.
集群創建用戶界麵允許您選擇集群配置細節,包括:
進入創建集群界麵
要使用用戶界麵創建集群,您必須處於基於角色的數據科學與工程或機器學習環境中。使用角色切換器如果有必要的話)。
那麼你可以:
點擊
 計算在側邊欄然後創建計算在“計算池”頁麵。
計算在側邊欄然後創建計算在“計算池”頁麵。點擊新>集群在側欄中。
集群政策
集群政策是一組規則,用於限製用戶在創建集群時可用的配置選項。集群策略具有acl,用於規範哪些特定用戶和組可以訪問某些策略。
默認情況下,所有用戶都可以訪問個人計算* * * *策略,允許它們創建單機計算資源。如果在創建集群時沒有將Personal Compute策略視為選項,則沒有授予您對該策略的訪問權。請與管理員聯係,請求訪問“個人計算”策略或相應的等效策略。
若要根據策略配置集群,請在列表中選擇集群策略政策下拉。
什麼是集群訪問模式?
的訪問模式下拉菜單取代了安全模式下拉。訪問模式標準化如下:
訪問模式下拉菜單 |
對用戶可見 |
Unity目錄支持 |
支持的語言 |
|---|---|---|---|
單用戶 |
總是 |
是的 |
Python, SQL, Scala, R |
共享 |
總是(需要保費計劃) |
是的 |
Python(適用於Databricks Runtime 11.1及以上版本),SQL |
未共享隔離 |
管理員可以通過強製用戶隔離在管理控製台。另見無隔離共享集群的相關帳戶級別設置. |
沒有 |
Python, SQL, Scala, R |
自定義 |
此選項僅針對現有集群顯示沒有訪問模式。如果使用遺留集群模式(如標準並發或高並發)創建集群,則Databricks將在新UI中顯示此訪問模式的值。此值不能用於創建新集群。 |
沒有 |
Python, SQL, Scala, R |
重要的
不支持集群API中的訪問模式。
Databricks運行時版本號
Databricks運行時是運行在集群上的核心組件集。所有Databricks Runtime版本都包含Apache Spark,並添加了提高可用性、性能和安全性的組件和更新。詳細信息請參見磚運行時.
選項選擇集群的運行時和版本Databricks運行時版本下拉菜單,當您創建或編輯集群時。
光子加速
光子對正在運行的集群可用嗎Databricks Runtime 9.1 LTS及以上。
要啟用光子加速,請選擇使用光子加速複選框。
如果需要,可以在Worker type和Driver type下拉菜單中指定實例類型。
集群節點類型
集群由一個驅動節點和零個或多個工作節點組成。您可以為驅動程序和工作節點選擇單獨的雲提供程序實例類型,盡管默認情況下驅動程序節點使用與工作節點相同的實例類型。不同的實例類型適用於不同的用例,例如內存密集型或計算密集型工作負載。
司機節點
驅動程序節點維護連接到集群的所有筆記本的狀態信息。驅動程序節點還維護SparkContext,解釋您在集群上的筆記本或庫中運行的所有命令,並運行與Spark執行器協調的Apache Spark master。
驅動節點類型默認值與工作節點類型相同。如果您打算這樣做,可以選擇具有更多內存的較大驅動程序節點類型收集()收集Spark員工的大量數據,並在筆記本上進行分析。
提示
由於驅動程序節點維護所附筆記本的所有狀態信息,請確保從驅動程序節點分離未使用的筆記本。
工作者節點
Databricks工作節點運行Spark執行器和正常運行的集群所需的其他服務。當您使用Spark分布工作負載時,所有的分布式處理都發生在工作節點上。Databricks為每個工作節點運行一個執行程序。因此,術語executor和worker在Databricks體係結構上下文中可以互換使用。
提示
要運行Spark作業,至少需要一個工作節點。如果集群中沒有工人,可以在驅動節點上運行非Spark命令,但Spark命令會失敗。
GPU實例類型
對於需要高性能的計算挑戰任務,例如與深度學習相關的任務,Databricks支持使用圖形處理單元(gpu)加速的集群。有關更多信息,請參見GPU-enabled集群.
AWS Graviton實例類型
Databricks支持使用AWS Graviton處理器的集群。基於arm的AWS Graviton實例是由AWS設計的,可以提供比同時代的基於x86的實例更好的性價比。看到AWS啟用引力子的集群.
集群大小和自動縮放
創建Databricks集群時,可以為集群提供固定數量的工作人員,也可以為集群提供最小和最大數量的工作人員。
當您提供一個固定大小的集群時,Databricks確保您的集群具有指定數量的工人。當您為工作人員的數量提供一個範圍時,Databricks將選擇運行作業所需的適當數量的工作人員。這被稱為自動定量.
隨著自動伸縮,Databricks動態地重新分配工人,以說明你的工作的特點。管道的某些部分可能比其他部分更需要計算,Databricks會在工作的這些階段自動添加額外的工作人員(並在不再需要時刪除他們)。
自動伸縮可以更容易地實現高集群利用率,因為您不需要配置集群來匹配工作負載。這尤其適用於需求隨時間變化的工作負載(比如在一天中探索一個數據集),但它也適用於一次性的較短工作負載,其配置需求未知。自動縮放提供了兩個優勢:
與固定大小的未配置的集群相比,工作負載可以更快地運行。
與靜態大小的集群相比,自動伸縮集群可以降低總體成本。
根據集群和工作負載的恒定大小,自動伸縮可以同時為您提供其中一種或兩種好處。當雲提供商終止實例時,集群大小可以低於所選擇的最小工作數。在這種情況下,Databricks會不斷嚐試重新提供實例,以保持最少的工作人員數量。
請注意
無法使用自動縮放功能spark-submit就業機會。
請注意
計算自動伸縮限製了為結構化流工作負載縮小集群大小。Databricks建議使用帶有增強自動伸縮功能的Delta Live Tables來處理流工作負載。看到什麼是增強型自動縮放?.
自動縮放的行為
在2步內從最小到最大。
可以縮小規模,即使集群不空閑,通過查看shuffle文件狀態。
根據當前節點的百分比遞減。
在作業集群上,如果集群在過去40秒內未得到充分利用,則減少。
在通用集群上,如果集群在過去150秒內未得到充分利用,則會減小。
的
spark.databricks.aggressiveWindowDownSSpark配置屬性以秒為單位指定集群做出降級決策的頻率。增大該值會導致集群縮小的速度變慢。最大值為600。
啟用並配置自動伸縮
為了允許Databricks自動調整您的集群大小,您可以為集群啟用自動縮放,並提供最小和最大的worker範圍。
啟用自動定量。
通用集群—在集群創建和編輯頁麵,選擇啟用自動定量中的複選框自動駕駛儀的選擇箱:
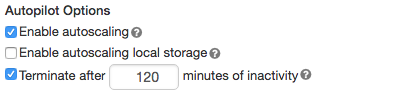
作業集群—在集群創建和編輯頁麵上,選擇啟用自動定量中的複選框自動駕駛儀的選擇箱:

配置最小工人和最大工人。

當集群運行時,集群詳細信息頁麵顯示分配的工人數量。您可以將分配的工作者數量與工作者配置進行比較,並根據需要進行調整。



自動定量的例子
如果將靜態集群重新配置為自動伸縮集群,Databricks將立即在最小和最大邊界內調整集群大小,然後開始自動伸縮。作為示例,下表演示了如果將集群重新配置為在5到10個節點之間自動伸縮,具有一定初始大小的集群將會發生什麼。
初始大小 |
重新配置後的尺寸 |
|---|---|
6 |
6 |
12 |
10 |
3. |
5 |
實例配置文件
要在不使用AWS密鑰的情況下安全地訪問AWS資源,可以使用實例概要啟動Databricks集群。看到使用實例概要配置S3訪問有關如何創建和配置實例概要文件的信息。創建實例概要文件後,在實例配置文件下拉列表。
請注意
一旦集群使用實例概要文件啟動,對該集群具有附加權限的任何人都可以訪問由該角色控製的底層資源。為了防止不必要的訪問,您可以使用集群訪問控製限製對集群的權限。
自動縮放本地存儲
如果不想在創建集群時分配固定數量的EBS卷,請使用自動伸縮本地存儲。通過自動伸縮本地存儲,Databricks可以監視集群Spark worker上可用的空閑磁盤空間的數量。如果一個worker的磁盤容量開始過低,Databricks會在它耗盡磁盤空間之前自動將一個新的EBS卷附加到這個worker上。每個實例(包括實例的本地存儲)所附加的EBS卷的總磁盤空間不超過5 TB。
如果需要配置自動伸縮存儲,請選擇啟用自動縮放本地存儲.

隻有當實例返回到AWS時,才會分離附加到實例的EBS卷。也就是說,隻要實例是運行中的集群的一部分,就不會從實例中分離EBS卷。為了減少EBS的使用,Databricks建議在配置了AWS Graviton實例類型或自動終止.
請注意
Databricks使用吞吐量優化HDD (st1)擴展實例的本地存儲。的默認AWS容量限製這些卷的價格是20 xb。為了避免達到此限製,管理員應該根據自己的使用需求請求增加此限製。
本地磁盤加密
預覽
此功能已在公共預覽.
用於運行集群的某些實例類型可能具有本地連接的磁盤。數據庫可以在這些本地連接的磁盤上存儲隨機數據或臨時數據。要確保對所有存儲類型(包括臨時存儲在集群本地磁盤上的隨機數據)的所有靜止數據進行加密,可以啟用本地磁盤加密。
重要的
由於從本地卷讀取和寫入加密數據對性能的影響,您的工作負載可能運行得更慢。
啟用本地磁盤加密後,Databricks會在本地生成每個集群節點唯一的加密密鑰,用於加密存儲在本地磁盤上的所有數據。該鍵的作用域對於每個集群節點都是本地的,並且與集群節點本身一起銷毀。在其生命周期內,密鑰駐留在內存中進行加密和解密,並加密存儲在磁盤上。
若要啟用本地磁盤加密,必須使用集群API 2.0.在創建或編輯集群時,設置:
{“enable_local_disk_encryption”:真正的}
看到創建而且編輯關於如何調用這些API的示例,請參閱集群API參考。
下麵是一個集群創建調用的例子,它啟用了本地磁盤加密:
{“cluster_name”:“my-cluster”,“spark_version”:“7.3.x-scala2.12”,“node_type_id”:“r3.xlarge”,“enable_local_disk_encryption”:真正的,“spark_conf”:{“spark.speculation”:真正的},“num_workers”:25}
集群的標簽
集群標記允許您輕鬆監控組織中各個組使用的雲資源的成本。在創建集群時,可以將標記指定為鍵-值對,Databricks將這些標記應用於虛擬機和磁盤卷等雲資源DBU使用報告.
對於從池啟動的集群,自定義集群標記僅應用於DBU使用情況報告,而不會傳播到雲資源。
有關池和群集標記類型如何協同工作的詳細信息,請參見使用集群和池標記監視使用情況.
配置集群標簽。
在標簽節中,為每個自定義標記添加一個鍵-值對。
點擊添加.
AWS的配置
在配置集群的AWS實例時,可以選擇可用分區、最大現貨價格和EBS卷類型。這些設置在高級選項切換到實例選項卡。
可用性區域
通過該設置,您可以指定集群使用的可用分區。缺省情況下,該設置設置為汽車,根據工作空間子網中可用ip自動選擇可用分區。如果AWS返回容量不足錯誤,Auto-AZ將在其他可用分區中重試。
如果您的組織在特定可用分區中購買了預留實例,那麼為集群選擇特定的AZ是非常有用的。閱讀更多AWS可用分區.
現貨實例
您可以指定是否使用現貨實例,以及在啟動現貨實例時使用的最大現貨價格(按相應需求價格的百分比)。默認情況下,最大價格是按需價格的100%。看到AWS現貨定價.
EBS卷
本節介紹工作節點的默認EBS卷設置、如何添加隨機卷以及如何配置集群以便Databricks自動分配EBS卷。
要配置EBS卷,請單擊實例選項卡中選擇一個選項EBS卷類型下拉列表。
默認EBS卷
Databricks為每個工作節點提供的EBS卷如下:
主機操作係統和Databricks內部服務使用的30gb加密的EBS實例根卷。
Spark worker使用的150gb加密的EBS容器根卷。存放Spark服務和日誌。
(僅限HIPAA)一個75 GB加密的EBS工作日誌卷,用於存儲Databricks內部服務的日誌。
添加EBS shuffle卷
如果需要添加shuffle卷,請選擇通用SSD在EBS卷類型下拉列表。
缺省情況下,Spark shuffle輸出到實例本地磁盤。對於沒有本地磁盤的實例類型,或者如果希望增加Spark隨機存儲空間,可以指定額外的EBS卷。當運行產生大量shuffle輸出的Spark作業時,這對於防止磁盤空間耗盡特別有用。
Databricks為按需和現場實例加密這些EBS卷。閱讀更多AWS EBS卷.
AWS EBS限製
確保您的AWS EBS限製足夠高,以滿足所有集群中所有工作者的運行時需求。有關默認EBS限製以及如何更改它們的信息,請參見Amazon彈性塊存儲(EBS)限製.
AWS EBS SSD卷類型
您可以為AWS EBS SSD卷類型選擇gp2或gp3。要做到這一點,看SSD存儲管理.Databricks建議您改用gp3,因為與gp2相比,它可以節省成本。有關gp2和gp3的技術信息,請參見Amazon EBS卷類型.
火花配置
為了優化Spark作業,您可以提供自定義Spark配置屬性在集群配置中。
2 .在集群配置界麵,單擊高級選項切換。
單擊火花選項卡。
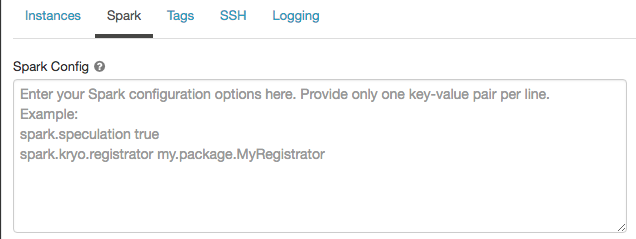
在火花配置,以每行一個鍵值對的形式輸入配置屬性。

屬性配置集群時集群API 2.0中設置Spark屬性spark_conf在創建集群請求或編輯集群請求.
若要為所有集群設置Spark屬性,請創建全局初始化腳本:
dbutils.fs.把(“dbfs: /磚/ init / set_spark_params.sh”,”“”| # !/bin/bash||cat << 'EOF' > /databricks/driver/conf/00-custom-spark-driver-defaults.conf . |cat << 'EOF' > /databricks/driver/conf/00-custom-spark-driver-defaults.conf .conf . |cat|(司機){|“spark.sql.sources。partitionOverwriteMode" = "DYNAMIC"|}| EOF”“”.stripMargin,真正的)
從secret中檢索Spark配置屬性
Databricks建議將密碼等敏感信息存儲在數據庫中秘密而不是明文。要在Spark配置中引用一個秘密,請使用以下語法:
火花。<屬性名>{{秘密/ < scope-name > / <秘密名字>}}
例如,設置Spark配置屬性為密碼對儲存在裏麵的秘密的價值秘密/ acme_app /密碼:
火花。密碼{{秘密/ acme-app /密碼}}
有關更多信息,請參見在Spark配置屬性或環境變量中引用秘密的語法.
環境變量
您可以配置可以從中訪問的自定義環境變量init腳本在集群上運行。Databricks還提供預定義的環境變量你可以在初始化腳本中使用。不能重寫這些預定義的環境變量。
2 .在集群配置界麵,單擊高級選項切換。
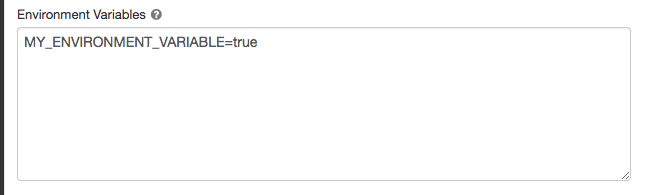
單擊火花選項卡。
中設置環境變量環境變量字段。

集群日誌傳遞
在創建集群時,可以指定Spark driver節點、worker節點和事件的日誌傳遞位置。日誌每5分鍾發送一次到您選擇的目的地。當一個集群被終止時,Databricks保證交付在集群被終止之前生成的所有日誌。
日誌的目的地取決於集群ID。如果指定的目標為dbfs: / cluster-log-delivery,集群日誌0630 - 191345 leap375送貨至dbfs: / cluster-log-delivery / 0630 - 191345 leap375.
設置日誌傳遞位置。
2 .在集群配置界麵,單擊高級選項切換。
單擊日誌記錄選項卡。
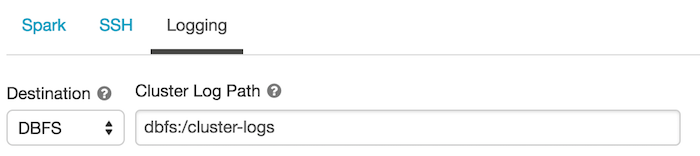
選擇目標類型。
輸入集群日誌路徑。

S3桶目的地
如果選擇S3目的地,則必須為集群配置可以訪問桶的實例概要文件。實例概要文件必須同時具有propertynames而且PutObjectAcl權限。為了方便起見,還包括了一個示例實例概要文件。看到使用實例概要配置S3訪問獲取有關如何設置實例概要文件的說明。
{“版本”:“2012-10-17”,“聲明”:[{“效應”:“允許”,“行動”:[“s3: ListBucket”],“資源”:[“攻擊:aws: s3::: < my-s3-bucket >”]},{“效應”:“允許”,“行動”:[“s3: propertynames”,“s3: PutObjectAcl”,“s3: GetObject”,“s3: DeleteObject”],“資源”:[“攻擊:aws: s3::: < my-s3-bucket > / *”]}]}