捕獲和視圖數據沿襲統一目錄
您可以使用統一的目錄來捕獲運行時數據沿襲在磚上運行查詢。血統是支持所有語言和捕獲到列的水平。譜係數據包括筆記本、工作流和儀表板相關查詢。血統可以以接近實時的可視化在數據瀏覽和檢索數據磚REST API。
請注意
您還可以查看和查詢係統使用血統譜係數據表(公共預覽)。有關更多信息,請參見分析家族係統表。
血統是聚合所有工作區目錄metastore附加到團結。這意味著血統捕獲在一個工作區中是可見的在其他任何工作區metastore共享。用戶必須有正確的權限查看數據血統。譜係數據保留30天。
本文介紹了可視化沿襲使用數據瀏覽和REST API。
需求
以下是需要捕獲數據沿襲統一目錄:
工作區必須統一目錄啟用和推出高端層。
表必須注冊在統一目錄metastore才有資格血統捕捉。
查詢必須使用火花DataFrame(例如,火花SQL函數,返回一個DataFrame)或磚SQL接口。磚的SQL和PySpark查詢的例子,請參閱例子。
查看表或視圖的血統,用戶必須有
選擇表或視圖特權。為筆記本血統信息視圖,工作流,或指示板,用戶必須定義這些對象的訪問控製權限設置在工作區中。看到血統的權限。
查看血統的統一Catalog-enabled管道,你必須有
CAN_VIEW管道的權限。
限製
流三角洲表之間隻在磚運行時支持11.3 LTS或以上。
因為血統是計算一個30天的滾動窗口,血統收集了超過30天前不顯示。例如,如果一個工作或查詢數據從表中讀取數據,並將其寫入表B, B表一和表之間的聯係是顯示隻有30天。
工作流使用API的工作
運行提交請求查看血統時不可用。表和列級血統仍使用時被捕獲運行提交請求,但運行的鏈接不是被俘。統一目錄捕捉盡可能多的列級血統。然而,有些情況下,列級血統不能捕獲。
如果一個表重命名,血統不是捕獲的重命名表。
如果你使用火花SQL數據庫檢查點,血統不是捕獲。看到pyspark.sql.DataFrame.checkpoint在Apache火花文檔。
例子
請注意
下麵的例子使用目錄名稱
lineage_data和模式名稱lineagedemo。使用不同的目錄和模式,改變的例子中使用的名稱。完成這個例子中,您必須有
創建和使用模式一個模式上的特權。metastore管理,目錄的所有者,或模式所有者可以授予這些權限。例如,給所有用戶組中的“data_engineers”中創建表的權限lineagedemo模式的lineage_data目錄,metastore管理員可以運行以下查詢:創建模式lineage_data。lineagedemo;格蘭特使用模式,創建在模式lineage_data。lineagedemo來”data_engineers”;
捕獲和探索血統
捕捉譜係數據,使用以下步驟:
去你的磚的著陸頁,點擊
 新在側邊欄,選擇筆記本從菜單中。
新在側邊欄,選擇筆記本從菜單中。筆記本並選擇輸入一個名稱SQL在默認的語言。
在集群,選擇一個集群提供統一目錄。
點擊創建。
在第一個筆記本電池,輸入以下查詢:
創建表如果不存在lineage_data。lineagedemo。菜單(recipe_idINT,應用程序字符串,主要字符串,甜點字符串);插入成lineage_data。lineagedemo。菜單(recipe_id,應用程序,主要,甜點)值(1,“酸橘汁醃魚,“玉米餅”,“坯子”),(2,“番茄湯”,“雜音”,“焦糖布丁”),(3,“芯片”,“烤奶酪”,“芝士蛋糕”);創建表lineage_data。lineagedemo。晚餐作為選擇recipe_id,concat(應用程序,“+”,主要,“+”,甜點)作為full_menu從lineage_data。lineagedemo。菜單
運行查詢,點擊在細胞和媒體shift + enter或者點擊
 並選擇運行單元。
並選擇運行單元。
 並選擇運行單元。
並選擇運行單元。使用數據瀏覽器來查看這些查詢生成的血統,使用以下步驟:
在搜索框欄頂部的磚工作區,回車
lineage_data.lineagedemo.dinner並點擊搜索lineage_data.lineagedemo。晚餐在磚。下表,單擊
晚餐表。選擇血統選項卡。血統麵板出現並顯示相關的表(在這個例子中
菜單表)。查看數據沿襲的交互式圖形,點擊看到譜係圖。默認情況下,一層顯示在圖。你可以點擊
 圖標在節點上透露更多連接是否可用。
圖標在節點上透露更多連接是否可用。點擊箭頭打開血統中連接節點圖血統聯係麵板。的血統聯係麵板顯示連接的詳細信息,包括源和目標表,筆記本電腦,和工作流。
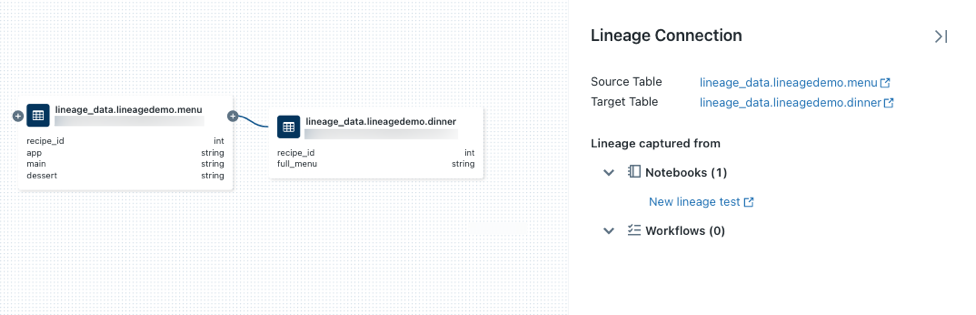
顯示相關的筆記本
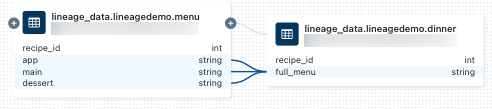
晚餐表,選擇的筆記本血統聯係麵板或關閉譜係圖,然後點擊筆記本電腦。在新標簽頁打開筆記本,點擊筆記本的名字。查看列級血統,點擊圖中的一列顯示鏈接到相關的列。例如,單擊“full_menu”列顯示上遊列列是來自:


演示創建和查看血統有不同的語言,例如,Python,使用以下步驟:
打開筆記本您在前麵創建,創建一個新細胞,並輸入以下Python代碼:
%python從pyspark.sql.functions進口蘭德,輪df=火花。範圍(3)。withColumn(“價格”,輪(10*蘭德(種子=42),2))。withColumnRenamed(“id”,“recipe_id”)df。寫。模式(“覆蓋”)。saveAsTable(“lineage_data.lineagedemo.price”)晚餐=火花。讀。表(“lineage_data.lineagedemo.dinner”)價格=火花。讀。表(“lineage_data.lineagedemo.price”)dinner_price=晚餐。加入(價格,在=“recipe_id”)dinner_price。寫。模式(“覆蓋”)。saveAsTable(“lineage_data.lineagedemo.dinner_price”)
在細胞和細胞通過點擊運行緊迫shift + enter或者點擊
並選擇運行單元。在搜索框欄頂部的磚工作區,回車
lineage_data.lineagedemo.price並點擊搜索lineage_data.lineagedemo。價格在磚。下表,單擊
價格表。選擇血統選項卡並單擊看到譜係圖。點擊
圖標探索數據沿襲和Python查詢生成的SQL。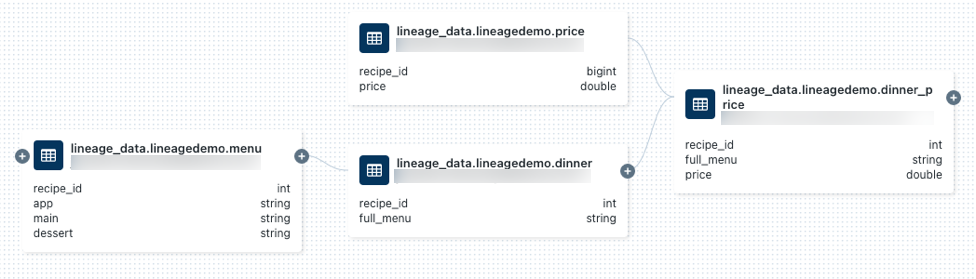
點擊箭頭打開血統中連接節點圖血統聯係麵板。的血統聯係麵板顯示連接的詳細信息,包括源和目標表,筆記本電腦,和工作流。

捕捉並查看工作流血統
血統也捕捉到任何讀取或寫入聯合目錄的工作流。為了演示觀看磚工作流的血統,使用以下步驟:
去你的磚的著陸頁,切換到數據科學與工程形象。
點擊
新在側邊欄並選擇筆記本從菜單中。筆記本並選擇輸入一個名稱SQL在默認的語言。
點擊創建。
在第一個筆記本電池,輸入以下查詢:
選擇*從lineage_data。lineagedemo。菜單
點擊時間表在窗口的頂部。在進度對話框中,選擇手冊,選擇一個集群提供統一目錄,然後單擊創建。
點擊現在運行。
在搜索框欄頂部的磚工作區,回車
lineage_data.lineagedemo.menu並點擊搜索lineage_data.lineagedemo。菜單在磚。下表查看所有表,單擊
菜單表。選擇血統選項卡上,單擊工作流,並選擇下遊選項卡。工作名稱出現作業名作為一個消費者
菜單表。
血統的權限
譜係圖共享相同的權限模型統一目錄。如果用戶沒有選擇特權在桌子上,他們將無法探索血統。另外,用戶隻能看到筆記本,工作流,儀表板,他們有權限查看。例如,如果您為一個非管理用戶運行以下命令userA:
格蘭特使用模式在lineage_data。lineagedemo來”userA@公司。com”;格蘭特選擇在lineage_data。lineagedemo。菜單來”userA@公司。com”;
當userA觀點的譜係圖lineage_data.lineagedemo.menu表,他們會看到菜單表,但將無法看到相關信息表,例如,下遊lineage_data.lineagedemo.dinner表。的晚餐表顯示為一個戴麵具的節點顯示userA,userA不能擴大圖揭示下遊表從表他們沒有權限訪問。
更多信息管理進入統一目錄,可到手的對象統一目錄管理權限。有關管理的更多信息訪問工作區對象像筆記本一樣,工作流,儀表板,不見了工作區對象訪問控製。
刪除數據血統
警告
下麵的說明刪除所有對象存儲在統一目錄。隻在必要時使用這些指令。例如,以滿足合規要求。
要刪除譜係數據,您必須刪除metastore統一目錄管理對象。關於刪除metastore的更多信息,請參閱刪除一個metastore。在30天內的數據將被刪除。
數據沿襲API
數據沿襲API允許您檢索表和列的血統。
重要的
訪問數據磚REST api,你必須進行身份驗證。
檢索表血統
這個示例檢索譜係數據晚餐表。
請求
curl——netrc - x\- h“application / json內容類型:\https:// < databricks-instance . . / api / 2.0 / lineage-tracking / table-lineage\- d{“table_name”:“lineage_data.lineagedemo。晚餐”、“include_entity_lineage”:真}}’
取代< databricks-instance >與磚工作區實例名例如,dbc-a1b2345c-d6e7.cloud.m.eheci.com。
這個示例使用. netrc文件。
響應
{“上遊”:({“tableInfo”:{“名稱”:“菜單”,“catalog_name”:“lineage_data”,“schema_name”:“lineagedemo”,“table_type”:“表”},“notebookInfos”:({“workspace_id”:4169371664718798,“notebook_id”:1111169262439324}]}),“下遊”:({“notebookInfos”:({“workspace_id”:4169371664718798,“notebook_id”:1111169262439324}]},{“tableInfo”:{“名稱”:“dinner_price”,“catalog_name”:“lineage_data”,“schema_name”:“lineagedemo”,“table_type”:“表”},“notebookInfos”:({“workspace_id”:4169371664718798,“notebook_id”:1111169262439324}]}]}
檢索列血統
這個示例檢索列數據晚餐表。
請求
curl——netrc - x\- h“application / json內容類型:\https:// < databricks-instance . . / api / 2.0 / lineage-tracking / column-lineage\- d{“table_name”:“lineage_data.lineagedemo。晚餐”、“column_name ": "甜點"}}’
取代< databricks-instance >與磚工作區實例名例如,dbc-a1b2345c-d6e7.cloud.m.eheci.com。
這個示例使用. netrc文件。
響應
{“upstream_cols”:({“名稱”:“甜點”,“catalog_name”:“lineage_data”,“schema_name”:“lineagedemo”,“table_name”:“菜單”,“table_type”:“表”},{“名稱”:“主要”,“catalog_name”:“lineage_data”,“schema_name”:“lineagedemo”,“table_name”:“菜單”,“table_type”:“表”},{“名稱”:“應用程序”,“catalog_name”:“lineage_data”,“schema_name”:“lineagedemo”,“table_name”:“菜單”,“table_type”:“表”}),“downstream_cols”:({“名稱”:“full_menu”,“catalog_name”:“lineage_data”,“schema_name”:“lineagedemo”,“table_name”:“dinner_price”,“table_type”:“表”}]}