使用AWS Glue Data Catalog作為metastore (legacy)
您可以配置Databricks Runtime,以使用AWS Glue數據目錄作為其metastore。這可以作為Hive metastore的插入式替代品。
每個AWS帳戶在AWS區域中擁有一個目錄,其目錄ID與AWS帳戶ID相同。使用Glue Catalog作為Databricks的介元,可以潛在地實現跨AWS服務、應用程序或AWS帳戶的共享介元。
您可以配置多個Databricks工作區來共享相同的metastore。
本文展示了如何使用實例配置文件安全地訪問Databricks中的Glue數據目錄。
請注意
使用外部介元是一種遺留數據治理模型。Databricks建議你升級到Unity Catalog。Unity Catalog通過提供一個中央位置來管理和審計帳戶中多個工作區的數據訪問,從而簡化了數據的安全性和治理。看到什麼是Unity Catalog?。
需求
您必須具有對部署Databricks的AWS帳戶和包含Glue數據目錄的AWS帳戶中的IAM角色和策略的AWS管理員訪問權限。
如果Glue數據目錄位於與Databricks部署位置不同的AWS帳戶中跨帳戶訪問策略必須允許從部署Databricks的AWS帳戶訪問目錄。請注意,我們隻支持使用Glue的資源策略授予跨帳戶訪問權限。
內置模式需要Databricks Runtime 8.4或以上版本,或Databricks Runtime 7.3 LTS。
將Glue Data Catalog配置為metastore
要啟用Glue Catalog集成,請設置AWS的配置spark.databricks.hive.metastore.glueCatalog.enabled真正的。默認情況下,禁用此配置。也就是說,默認是使用Databricks托管的Hive metastore,或者其他一些外部metastore(如果配置的話)。
對於交互式集群或作業集群,請在集群配置中設置配置之前集群啟動。
重要的
這個配置選項不能在運行中的集群中修改。
運行時spark-submit設置此配置選項spark-submit參數使用——設計spark.databricks.hive.metastore.glueCatalog.enabled = true或者用代碼設置之前創建SparkSession或SparkContext。例如:
從pyspark.sql進口SparkSession在這裏直接設置Glue的conf,而不是在spark-submit中使用——conf選項火花=SparkSession。構建器。\瀏覽器名稱(“ExamplePySparkSubmitTask”)。\配置(“spark.databricks.hive.metastore.glueCatalog.enabled”,“真正的”)。\enableHiveSupport()。\getOrCreate()打印(火花。sparkContext。getConf()。得到(“spark.databricks.hive.metastore.glueCatalog.enabled”))火花。sql(“顯示數據庫”)。顯示()火花。停止()
如何配置Glue Catalog訪問取決於Databricks和Glue Catalog是在相同的AWS帳戶和區域中,還是在不同的帳戶中,或者在不同的區域中。遵循本文其餘部分的相應步驟:
相同的AWS帳戶和區域遵循步驟1,然後是步驟3-5。
Cross-account執行步驟1-6。
區域遵循步驟1,然後是步驟3-6。
重要的
AWS Glue Data Catalog策略僅定義對元數據的訪問權限。S3策略定義對內容本身的訪問權限。這些步驟在AWS Glue數據目錄上設置策略。他們不設置S3桶級或對象級策略。看到使用實例配置文件配置S3訪問為Databricks設置S3權限。
有關更多信息,請參見使用資源級IAM權限和基於資源的策略限製對AWS Glue數據目錄的訪問。
步驟1:創建一個實例概要文件來訪問Glue Data Catalog
在AWS控製台中,進入IAM服務。
單擊側欄中的Roles選項卡。
點擊創建角色。
在“選擇受信任實體類型”下,選擇AWS服務。
單擊EC2服務。
在Select your use case下,單擊EC2。
點擊下一個:權限並點擊下一個:審查。
在“角色名稱”字段中,鍵入角色名稱。
點擊創建角色。顯示角色列表。
在角色列表中,單擊角色。
向Glue Catalog添加一個內聯策略。
在“權限”頁簽中,單擊
 。
。單擊JSON選項卡。
將此策略複製並粘貼到選項卡中。
{“版本”:“2012-10-17”,“聲明”:[{“席德”:“GrantCatalogAccessToGlue”,“效應”:“允許”,“行動”:[“膠:BatchCreatePartition”,“膠:BatchDeletePartition”,“膠:BatchGetPartition”,“膠:CreateDatabase”,“膠:不知道”,“膠:CreateUserDefinedFunction”,“膠:DeleteDatabase”,“膠:DeletePartition”,“膠:DeleteTable”,“膠:DeleteUserDefinedFunction”,“膠:GetDatabase”,“膠:getdatabase”,“膠:GetPartition”,“膠:GetPartitions”,“膠:可以獲得的”,“膠:可以獲得的”,“膠:GetUserDefinedFunction”,“膠:GetUserDefinedFunctions”,“膠:UpdateDatabase”,“膠:UpdatePartition”,“膠:UpdateTable”,“膠:UpdateUserDefinedFunction”],“資源”:[“*”]}]}

 。
。有關允許的資源(目錄、數據庫、表、userDefinedFunction)的細粒度配置,請參見指定AWS Glue資源ARNs。
如果上述策略中允許的操作列表不足,請與您的Databricks代表聯係並提供錯誤信息。最簡單的解決方法是使用一個允許Glue完全訪問的策略:
{“版本”:“2012-10-17”,“聲明”:[{“席德”:“GrantFullAccessToGlue”,“效應”:“允許”,“行動”:[“膠:*”],“資源”:“*”}]}
步驟2:為目標Glue Catalog創建策略
隻有在目標膠水目錄中才執行此步驟不同的AWS賬戶比Databricks部署時使用的要多。
登錄目標Glue Catalog的AWS賬戶,進入Glue Console。
在“設置”中,將以下策略粘貼到“權限”框中。集
< aws-account-id-databricks >,< iam-role-for-glue-access >從步驟1,< aws-region-target-glue-catalog >,< aws-account-id-target-glue-catalog >相應地,。{“版本”:“2012-10-17”,“聲明”:[{“席德”:“許可”,“效應”:“允許”,“校長”:{“AWS”:“攻擊:aws:我::< aws-account-id-databricks >:角色/ < iam-role-for-glue-access >”},“行動”:[“膠:BatchCreatePartition”,“膠:BatchDeletePartition”,“膠:BatchGetPartition”,“膠:CreateDatabase”,“膠:不知道”,“膠:CreateUserDefinedFunction”,“膠:DeleteDatabase”,“膠:DeletePartition”,“膠:DeleteTable”,“膠:DeleteUserDefinedFunction”,“膠:GetDatabase”,“膠:getdatabase”,“膠:GetPartition”,“膠:GetPartitions”,“膠:可以獲得的”,“膠:可以獲得的”,“膠:GetUserDefinedFunction”,“膠:GetUserDefinedFunctions”,“膠:UpdateDatabase”,“膠:UpdatePartition”,“膠:UpdateTable”,“膠:UpdateUserDefinedFunction”],“資源”:“攻擊:aws:膠:< aws-region-target-glue-catalog >: < aws-account-id-target-glue-catalog >: *”}]}
步驟3:查找用於創建Databricks部署的IAM角色
此IAM角色是您在設置Databricks帳戶時使用的角色。
的帳戶的以下步驟有所不同E2版本的平台Beplay体育安卓版本所有新的Databricks帳戶和大多數現有帳戶現在都是E2。Beplay体育安卓版本如果您不確定您擁有的是哪種帳戶類型,請聯係您的Databricks代表。
如果你在E2帳戶:
以帳號所有者或admin帳號登錄賬戶控製台。
去工作區然後單擊您的工作區名稱。
在憑證框中,請注意角色ARN末尾的角色名稱。
例如在角色ARN中
攻擊:aws:我::123456789123:/ finance-prod角色其中,finance-prod是角色名。
如果您不是E2帳戶:
以帳號所有者身份登錄賬戶控製台。
單擊AWS帳戶選項卡。
注意角色ARN末尾的角色名testco-role。

步驟4:將Glue Catalog實例概要文件添加到EC2策略
在AWS控製台中,進入IAM服務。
單擊角色選項卡。
單擊您在步驟3中記錄的角色。
在“權限”選項卡上,單擊策略。
點擊編輯政策。
修改策略以允許Databricks將您在步驟1中創建的實例配置文件傳遞給Spark集群的EC2實例。下麵是新政策應該是什麼樣的一個例子。取代
< iam-role-for-glue-access >使用您在步驟1中創建的角色。對於帳戶E2版本的平台Beplay体育安卓版本:
{“版本”:“2012-10-17”,“聲明”:[{“席德”:“Stmt1403287045000”,“效應”:“允許”,“行動”:[“ec2: AssociateDhcpOptions”,“ec2: AssociateIamInstanceProfile”,“ec2: AssociateRouteTable”,“ec2: AttachInternetGateway”,“ec2: AttachVolume”,“ec2: AuthorizeSecurityGroupEgress”,“ec2: AuthorizeSecurityGroupIngress”,“ec2: CancelSpotInstanceRequests”,“ec2: CreateDhcpOptions”,“ec2: CreateInternetGateway”,“ec2: CreatePlacementGroup”,“ec2: CreateRoute”,“ec2: CreateSecurityGroup”,“ec2: CreateSubnet”,“ec2: CreateTags”,“ec2: CreateVolume”,“ec2: CreateVpc”,“ec2: CreateVpcPeeringConnection”,“ec2: DeleteInternetGateway”,“ec2: DeletePlacementGroup”,“ec2: DeleteRoute”,“ec2: DeleteRouteTable”,“ec2: DeleteSecurityGroup”,“ec2: DeleteSubnet”,“ec2: DeleteTags”,“ec2: DeleteVolume”,“ec2: DeleteVpc”,“ec2: DescribeAvailabilityZones”,“ec2: DescribeIamInstanceProfileAssociations”,“ec2: DescribeInstanceStatus”,“ec2: DescribeInstances”,“ec2: DescribePlacementGroups”,“ec2: DescribePrefixLists”,“ec2: DescribeReservedInstancesOfferings”,“ec2: DescribeRouteTables”,“ec2: DescribeSecurityGroups”,“ec2: DescribeSpotInstanceRequests”,“ec2: DescribeSpotPriceHistory”,“ec2: DescribeSubnets”,“ec2: DescribeVolumes”,“ec2: DescribeVpcs”,“ec2: DetachInternetGateway”,“ec2: DisassociateIamInstanceProfile”,“ec2: ModifyVpcAttribute”,“ec2: ReplaceIamInstanceProfileAssociation”,“ec2: RequestSpotInstances”,“ec2: RevokeSecurityGroupEgress”,“ec2: RevokeSecurityGroupIngress”,“ec2: RunInstances”,“ec2: TerminateInstances”],“資源”:[“*”]},{“效應”:“允許”,“行動”:“我:PassRole”,“資源”:“攻擊:aws:我::< aws-account-id-databricks >:角色/ < iam-role-for-glue-access >”}]}
對於平台上其他版本的帳戶:Beplay体育安卓版本
{“版本”:“2012-10-17”,“聲明”:[{“席德”:“Stmt1403287045000”,“效應”:“允許”,“行動”:[“ec2: AssociateDhcpOptions”,“ec2: AssociateIamInstanceProfile”,“ec2: AssociateRouteTable”,“ec2: AttachInternetGateway”,“ec2: AttachVolume”,“ec2: AuthorizeSecurityGroupEgress”,“ec2: AuthorizeSecurityGroupIngress”,“ec2: CancelSpotInstanceRequests”,“ec2: CreateDhcpOptions”,“ec2: CreateInternetGateway”,“ec2: CreateKeyPair”,“ec2: CreateRoute”,“ec2: CreateSecurityGroup”,“ec2: CreateSubnet”,“ec2: CreateTags”,“ec2: CreateVolume”,“ec2: CreateVpc”,“ec2: CreateVpcPeeringConnection”,“ec2: DeleteInternetGateway”,“ec2: DeleteKeyPair”,“ec2: DeleteRoute”,“ec2: DeleteRouteTable”,“ec2: DeleteSecurityGroup”,“ec2: DeleteSubnet”,“ec2: DeleteTags”,“ec2: DeleteVolume”,“ec2: DeleteVpc”,“ec2: DescribeAvailabilityZones”,“ec2: DescribeIamInstanceProfileAssociations”,“ec2: DescribeInstanceStatus”,“ec2: DescribeInstances”,“ec2: DescribePrefixLists”,“ec2: DescribeReservedInstancesOfferings”,“ec2: DescribeRouteTables”,“ec2: DescribeSecurityGroups”,“ec2: DescribeSpotInstanceRequests”,“ec2: DescribeSpotPriceHistory”,“ec2: DescribeSubnets”,“ec2: DescribeVolumes”,“ec2: DescribeVpcs”,“ec2: DetachInternetGateway”,“ec2: DisassociateIamInstanceProfile”,“ec2: ModifyVpcAttribute”,“ec2: ReplaceIamInstanceProfileAssociation”,“ec2: RequestSpotInstances”,“ec2: RevokeSecurityGroupEgress”,“ec2: RevokeSecurityGroupIngress”,“ec2: RunInstances”,“ec2: TerminateInstances”],“資源”:[“*”]},{“效應”:“允許”,“行動”:“我:PassRole”,“資源”:“攻擊:aws:我::< aws-account-id-databricks >:角色/ < iam-role-for-glue-access >”}]}
點擊審查政策。
點擊保存更改。
步驟5:將Glue Catalog實例概要文件添加到Databricks工作區
進入管理設置頁麵。
單擊實例配置文件選項卡。
單擊添加實例配置文件按鈕。出現一個對話框。
粘貼步驟1中的實例配置文件ARN。
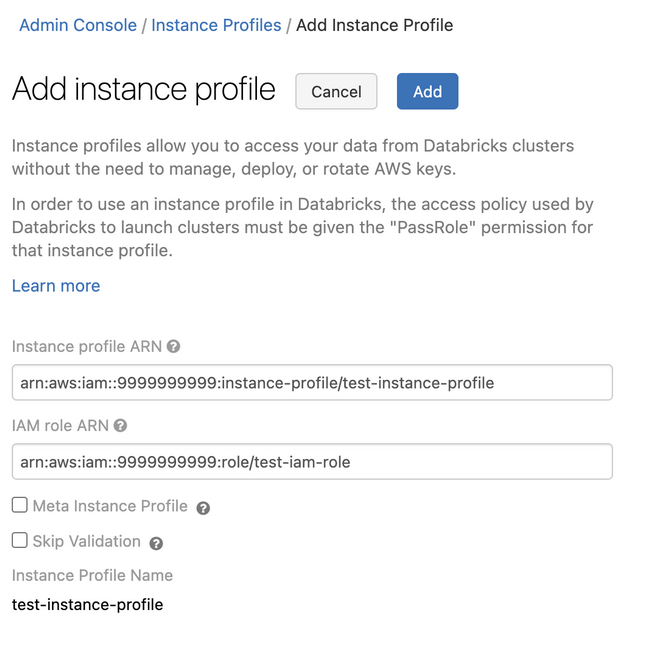
Databricks驗證實例配置文件ARN在語法和語義上都是正確的。為了驗證語義正確性,Databricks通過使用此實例配置文件啟動集群來進行演練。此試運行中的任何失敗都會在UI中產生驗證錯誤。
請注意
如果實例概要文件包含標記強製策略,則它的驗證可能會失敗,從而阻止您添加合法的實例概要文件。如果驗證失敗,並且您仍然希望將實例概要文件添加到Databricks,請使用instance Profiles API並指定
skip_validation。點擊添加。
可選地指定可以使用實例概要文件啟動集群的用戶。


步驟6:使用Glue Catalog實例概要文件啟動集群
創建集群
單擊實例選項卡。
在實例配置文件下拉列表中,選擇實例配置文件。
驗證您可以訪問Glue Catalog,在筆記本中使用以下命令:
顯示數據庫;
如果命令成功,說明該Databricks Runtime集群配置為使用Glue。根據您的AWS帳戶和Glue區域,您可能需要執行兩個額外步驟:
如果Databricks部署的AWS帳戶與Glue Data Catalog的AWS帳戶不同,則需要進行額外的跨帳戶設置。
集
spark.hadoop.hive.metastore.glue.catalogid< aws-account-id-for-glue-catalog >在AWS的配置。如果目標Glue Catalog位於與Databricks部署不同的區域,也要指定
spark.hadoop.aws.region< aws-region-for-glue-catalog >。
提示
提醒一下,spark.databrick .hive.metastore. glueccatalog .enabled true是連接到AWS Glue所需的配置。
Spark包含對Hive的內置支持,但是否使用該功能取決於Databricks Runtime版本。
隔離模式:關閉對Hive的內置支持。Hive 1.2.1的庫。從Spark2加載
/磚/膠水/。在Databricks Runtime 8.3中,隔離模式已啟用且無法禁用。在Databricks Runtime 7.3 LTS和Databricks Runtime 8.4及更高版本中,隔離模式是默認的,但可以禁用。內置模式:內置支持Hive, Hive版本以Spark版本為準。在Databricks Runtime 7.3 LTS和Databricks Runtime 8.4及以上版本中,您可以通過設置啟用內置模式
spark.databricks.hive.metastore.glueCatalog.isolation.enabled假在集群上。
若要啟用憑據直通,請設置
spark.databricks.passthrough.enabled真正的。這需要Databricks Runtime 7.3 LTS或Databricks Runtime 8.4或更高版本。在Databricks Runtime 7.3 LTS和Databricks Runtime 8.4及以上版本中,此設置還會自動啟用內置模式。

限製
使用AWS Glue Data Catalog作為Databricks中的metastore可能比默認的Hive metastore有更高的延遲。有關更多信息,請參見使用Glue Catalog比使用Databricks Hive metastore遇到更高的延遲請參見故障排除部分。
屬性創建默認數據庫,並將位置設置為URI
dbfs:(Databricks File System)方案。此位置不能從Databricks以外的AWS應用程序(如AWS EMR或AWS Athena)訪問。作為一種變通方法,使用位置子句指定存儲桶位置,例如s3: / / mybucket當你打來電話創建表格。或者,在默認數據庫以外的數據庫中創建表,並設置位置將該數據庫轉移到S3位置。不能在Glue Catalog和Hive metastore之間動態切換。新的Spark配置需要重啟集群才能生效。
僅在Databricks Runtime 8.4及以上版本中支持憑據直通。
不支持以下特性:
跨係統交互,跨多個係統共享相同的元數據目錄或實際表數據。
故障排除
在本節中:
Glue Catalog的延遲比Databricks Hive metastore高
使用Glue Data Catalog作為外部metastore可能會比默認的Databricks托管的Hive metastore產生更高的延遲。Databricks建議在Glue Catalog客戶端中啟用客戶端緩存。以下部分將展示如何為表和數據庫配置客戶端緩存。您可以為以下內容配置客戶端緩存集群和SQL倉庫。
請注意
客戶端緩存不適用於清單表操作
可以獲得的。生存時間(TTL)配置是在緩存的有效性和元數據可容忍的過時性之間進行權衡。選擇對特定場景有意義的TTL值。
有關詳細信息,請參見為Glue Catalog啟用客戶端緩存請參閱AWS文檔。
沒有附加到Databricks運行時集群的實例配置文件
如果沒有實例配置文件附加到Databricks運行時集群,那麼當您運行任何需要metastore查找的操作時,將發生以下異常:
[EnvironmentVariableCredentialsProvider:無法從環境變量(AWS_ACCESS_KEY_ID(或AWS_ACCESS_KEY)和AWS_SECRET_KEY(或AWS_SECRET_ACCESS_KEY))中加載AWS憑據,SystemPropertiesCredentialsProvider:無法從Java係統屬性(AWS_ACCESS_KEY)中加載AWS憑據。accessKeyId和aws.secretKey), com.amazonaws.auth.profile。ProfileCredentialsProvider@2245a35d: profile文件不能為空,com. amazon.com .auth。EC2ContainerCredentialsProviderWrapper@52be6b57: The requested metadata is not found at https://169.254.169.254/latest/meta-data/iam/security-credentials/];
附加具有訪問所需Glue Catalog的足夠權限的實例配置文件。
膠水目錄權限不足
當實例配置文件沒有授予執行metastore操作所需的權限時,會發生如下異常:
org.apache.spark.sql.AnalysisException: java.lang.RuntimeException: MetaException(消息:無法驗證默認數據庫的存在:com.amazonaws.services.glue.model.AccessDeniedException: User: arn:aws:sts:::假設-角色//…沒有被授權對資源執行:glue: GetDatabase: arn:aws:glue:::catalog (Service: AWSGlue;狀態碼:400;錯誤碼:AccessDeniedException;請求ID: < Request - ID >));
檢查附加的實例配置文件是否指定了足夠的權限。例如,在前麵的例外中,添加膠水:GetDatabase到實例概要文件。
權限錯誤膠水:GetDatabase直接在文件上運行SQL時
在Databricks Runtime 8.0以下版本中,運行SQL查詢時直接在文件上例如,
選擇*從拚花。`路徑-來-數據`
您可能會遇到如下錯誤:
SQL語句出現錯誤:AnalysisException…沒有被授權對資源執行:glue:GetDatabase: :database/parquet
當IAM策略不授予執行權限時,會發生這種情況膠水:GetDatabase關於資源數據庫/ < datasource-format >,在那裏< datasource-format >數據源格式是否如拚花或δ。
在IAM策略中添加允許的權限膠水:GetDatabase在數據庫/ < datasource-format >。
在Spark SQL分析器的實現中有一個限製,它嚐試根據目錄解析關係,然後再返回到嚐試針對已注冊的數據源解析文件中的SQL。隻有當針對目錄進行解析的初始嚐試無異常返回時,回退才有效。
即使資源數據庫/ < datasource-format >可能不存在,為了成功運行對文件的回退SQL查詢,Glue Catalog的IAM策略必須允許執行膠水:GetDatabase行動起來。
在Databricks Runtime 8.0及以上版本中,此問題將自動處理,不再需要此解決方案。
不匹配的膠水目錄編號
默認情況下,Databricks集群嚐試連接到用於Databricks部署的同一AWS帳戶中的Glue Catalog。
如果目標Glue Catalog位於與Databricks部署不同的AWS帳戶或區域中,則spark.hadoop.hive.metastore.glue.catalogid如果沒有設置Spark配置,集群將連接到Databricks部署的AWS帳戶中的Glue目錄,而不是目標目錄。
如果spark.hadoop.hive.metastore.glue.catalogid如果設置了配置,但是步驟2中的配置沒有正確完成,則任何對metastore的訪問都會導致如下異常:
org.apache.spark.sql.AnalysisException: java.lang.RuntimeException: MetaException(消息:無法驗證默認數據庫的存在:com.amazonaws.services.glue.model.AccessDeniedException: User:攻擊:aws: sts:: < aws-account-id >:自選角色/ < role-id > /……沒有被授權對資源執行:glue: GetDatabase: arn:aws:glue:::catalog (Service: AWSGlue;狀態碼:400;錯誤碼:AccessDeniedException;請求ID: < Request - ID >));
驗證配置是否與本文中的步驟2和6一致。
Athena Catalog與Glue Catalog衝突
如果您在2017年8月14日之前使用Amazon Athena或Amazon Redshift Spectrum創建了表,則數據庫和表存儲在Athena管理的目錄中,該目錄與AWS Glue數據目錄分開。要將Databricks Runtime與這些表集成,必須升級到AWS Glue數據目錄。否則,Databricks Runtime將無法連接到Glue Catalog或無法創建和訪問某些數據庫,並且異常消息可能是神秘的。
例如,如果“默認”數據庫存在於Athena目錄中,但不存在於Glue目錄中,則會出現如下異常消息:
無法驗證默認數據庫的存在:accessdeniedexception:請遷移您的目錄以啟用對該數據庫的訪問(Service: AWSGlue;狀態碼:400;錯誤碼:AccessDeniedException;請求ID: < Request - ID >)
在數據庫中創建一個空表位置
Glue Catalog中的數據庫可以從各種來源創建。默認情況下,Databricks Runtime創建的數據庫有一個非空的LOCATION字段。直接在Glue控製台中創建或從其他來源導入的數據庫可能具有空的位置字段。
當Databricks運行時嚐試在數據庫中創建一個表時位置字段時,發生如下異常:like:
不能從空字符串創建路徑
在Glue Catalog中使用有效的非空路徑創建數據庫位置字段,則指定位置在SQL中創建表時,或指定選項(“路徑”,< some_valid_path >)在DataFrame API。
在AWS Glue Console中創建數據庫時,隻需要名稱;“描述”和“位置”都被標記為可選。然而,Hive metastore操作依賴於“Location”,所以你必須為Databricks Runtime中使用的數據庫指定Location。
訪問在其他係統中創建的表和視圖
訪問由其他係統(如AWS Athena或Presto)創建的表和視圖,可能在Databricks Runtime或Spark中工作,也可能不工作,並且這些操作不受支持。它們可能會失敗,並顯示神秘的錯誤消息。例如,訪問由Athena、Databricks Runtime或Spark創建的視圖可能會拋出如下異常:
不能從空字符串創建路徑
出現這個異常是因為Athena和Presto以不同於Databricks Runtime和Spark期望的格式存儲視圖元數據。