磚連接
請注意
Databricks建議您使用其中任何一種dbx或者是Visual Studio Code的Databricks擴展用於本地開發而不是Databricks Connect。
Databricks Connect允許您連接您最喜歡的IDE (Eclipse, IntelliJ, PyCharm, RStudio, Visual Studio Code),筆記本服務器(Jupyter notebook, Zeppelin),和其他自定義應用程序到Databricks集群。
本文解釋了Databricks Connect的工作原理,引導您完成開始使用Databricks Connect的步驟,解釋了如何排除使用Databricks Connect時可能出現的問題,以及使用Databricks Connect運行與在Databricks筆記本上運行之間的區別。
概述
Databricks Connect是Databricks運行時的客戶端庫。它允許您使用Spark api編寫作業,並在Databricks集群上遠程運行它們,而不是在本地Spark會話中運行。
例如,執行DataFrame命令時spark.read.format(“鋪”).load(…).groupBy(…).agg(…),告訴()使用Databricks Connect,作業的解析和規劃在本地機器上運行。然後,任務的邏輯表示被發送到運行在Databricks中的Spark服務器,以便在集群中執行。
使用Databricks Connect,您可以:
從任何Python、Java、Scala或R應用程序運行大規模Spark作業。任何地方
進口pyspark,進口org.apache.spark,或要求(SparkR),您現在可以直接從應用程序運行Spark作業,而不需要安裝任何IDE插件或使用Spark提交腳本。即使在使用遠程集群時,也可以在IDE中逐步檢查和調試代碼。
在開發庫時快速迭代。在Databricks Connect中更改Python或Java庫依賴關係後,不需要重新啟動集群,因為每個客戶端會話在集群中是相互隔離的。
在不丟失工作的情況下關閉空閑集群。由於客戶機應用程序與集群分離,因此它不受集群重新啟動或升級的影響,而集群重新啟動或升級通常會導致丟失筆記本中定義的所有變量、rdd和DataFrame對象。
請注意
對於使用SQL查詢的Python開發,Databricks建議您使用Databricks SQL連接器for Python而不是Databricks Connect。Databricks SQL Connector for Python比Databricks Connect更容易設置。此外,Databricks Connect解析和計劃在本地機器上運行的作業,而作業在遠程計算資源上運行。這使得調試運行時錯誤變得特別困難。Databricks SQL Connector for Python直接向遠程計算資源提交SQL查詢並獲取結果。
需求
僅支持以下Databricks Runtime版本:
Databricks Runtime 11.3 LTS ML
Databricks Runtime 10.4 LTS ML
Databricks Runtime 9.1 LTS ML
Databricks Runtime 7.3 LTS ML
客戶端Python安裝的次要版本必須與Databricks集群的次要Python版本相同。下表顯示了每個Databricks Runtime安裝的Python版本。
Databricks運行時版本號
Python版本
11.3 LTS ml, 11.3 LTS
3.9
10.4 LTS ml, 10.4 LTS
3.8
9.1 LTS ml, 9.1 LTS
3.8
7.3 LTS ml
3.7
例如,如果你在本地開發環境中使用Conda,而你的集群運行的是Python 3.7,你必須創建一個該版本的環境,例如:
Conda create——name dbconnectpython=3.7 conda
Databricks Connect主要和次要包版本必須始終與您的Databricks運行時版本匹配。Databricks建議您始終使用與您的Databricks運行時版本相匹配的Databricks Connect最新包。例如,當使用Databricks Runtime 7.3 LTS集群時,使用
databricks-connect = = 7.3 . *包中。請注意
看到Databricks Connect發布說明參閱可用的Databricks Connect版本和維護更新的列表。
Java Runtime Environment (JRE)客戶端已使用OpenJDK 8 JRE進行測試。客戶端不支持Java 11。
請注意
在Windows上,如果您看到Databricks Connect無法找到的錯誤winutils.exe,請參閱在Windows上找不到winutils.exe.
設置客戶端
請注意
在開始設置Databricks Connect客戶端之前,您必須滿足要求用於Databricks Connect。
步驟1:安裝客戶端
卸載PySpark。這是必需的,因為
databricks-connect包與PySpark衝突。詳細信息請參見衝突的PySpark安裝.PIP卸載pyspark
安裝Databricks Connect客戶端。
pip install -U“databricks-connect = = 7.3 *”。#或x.y *來匹配您的集群版本。
請注意
總是指定
databricks-connect = = X.Y. *而不是databricks-connect = X。Y,以確保安裝了最新的軟件包。
步驟2:配置連接屬性
收集以下配置屬性:
配置連接。可以使用CLI、SQL或環境變量進行配置。配置方法的優先級從高到低依次為:SQL配置鍵、CLI和環境變量。
CLI
運行
databricks-connect.databricks-connect配置
license顯示如下:
版權(2018)磚,公司.這圖書館(的“軟件”)五月不是使用除了在連接與的被許可方根據協議使用Databricks平台服務Beplay体育安卓版本...
接受許可證並提供配置值。為磚的主機而且磚的令牌,輸入您在步驟1中注意到的工作區URL和個人訪問令牌。
你是否接受上述協議?[y/N] y設置新的配置值(保留輸入為空接受默認值):databrick Host[無當前值,必須以https://開頭]:
databrick Token[無當前值]: 集群ID(例如,0921-001415-jelly628)[無當前值]:< Cluster - ID >組織ID (Azure-only,見?o=orgId in URL) [0]: < Org - ID >端口[15001]:<端口>
SQL配置或環境變量。下表顯示了與步驟1中注意到的配置屬性對應的SQL配置鍵和環境變量。要設置SQL配置鍵,請使用
sql(“集配置=值”).例如:sql(“集spark.databricks.service.clusterId = 0304 - 201045 - abcdefgh”).參數
SQL配置鍵
環境變量名稱
磚的主機
spark.databricks.service.address
DATABRICKS_ADDRESS
磚的令牌
spark.databricks.service.token
DATABRICKS_API_TOKEN
集群ID
spark.databricks.service.clusterId
DATABRICKS_CLUSTER_ID
Org ID
spark.databricks.service.orgId
DATABRICKS_ORG_ID
港口
spark.databricks.service.port
DATABRICKS_PORT
測試到Databricks的連通性。
databricks-connect測驗如果您配置的集群沒有運行,測試將啟動集群,該集群將一直運行到其配置的自動終止時間。輸出應該是這樣的:
* PySpark安裝在/…/3.5.6/lib/python3.5/site-packages/ PySpark *檢查java版本java版本"1.8.0_152" java (TM) SE運行時環境(build 1.8.0_152-b16) java HotSpot(TM) 64位服務器虛擬機(build 25.152-b16,混合模式)*測試scala命令18/12/10 16:38:44警告NativeCodeLoader:無法為您的平台加載本機hadoop庫…Beplay体育安卓版本使用Spark的默認log4j配置文件:org/apache/spark/log4j-defaults。properties設置默認日誌級別為WARN。使用sc.setLogLevel(newLevel)調整日誌級別。對於SparkR,使用setLogLevel(newLevel)。18/12/10 16:38:50 WARN MetricsSystem:使用默認名稱SparkStatusTracker作為源,因為沒有設置spark.metrics.namespace和spark.app.id。18/12/10 16:39:53 WARN SparkServiceRPCClient: Now tracking server state for 5abb7c7e-df8e-4290-947c-c9a38601024e, invalidprev state 18/12/10 16:39:59 WARN SparkServiceRPCClient: Syncing 129 files (176036 bytes) took 3003 ms歡迎訪問____ __/__ /__ ___ _____/ /___ \ \/ _\ /_/ /___/ .__/\_,_/_/ /_/\_版本2.4.0-SNAPSHOT /_/ Using Scala version 2.11.12 (Java HotSpot(TM) 64-Bit server VM, Java 1.8.0_152)輸入表達式來計算它們。類型:幫助獲取更多信息。scala > spark.range(100)。reduce(_ + _) Spark context Web UI可用在https://10.8.5.214:4040 Spark context可用為'sc' (master = local[*], app id = local-1544488730553)。Spark會話可用為“Spark”。 View job details at
/?o=0#/setting/clusters/ /sparkUi View job details at ?o=0#/setting/clusters/ /sparkUi res0: Long = 4950 scala> :quit * Testing python command 18/12/10 16:40:16 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). 18/12/10 16:40:17 WARN MetricsSystem: Using default name SparkStatusTracker for source because neither spark.metrics.namespace nor spark.app.id is set. 18/12/10 16:40:28 WARN SparkServiceRPCClient: Now tracking server state for 5abb7c7e-df8e-4290-947c-c9a38601024e, invalidating prev state View job details at /?o=0#/setting/clusters/ /sparkUi

設置IDE或筆記本服務器
本節描述如何配置您的首選IDE或筆記本服務器以使用Databricks Connect客戶端。
本節:
Jupyter筆記本
請注意
Databricks建議您使用其中任何一種dbx或者是Visual Studio Code的Databricks擴展用於本地開發而不是Databricks Connect。
在開始使用Databricks Connect之前,您必須滿足要求而且設置客戶端用於Databricks Connect。
Databricks Connect配置腳本自動將包添加到項目配置中。要在Python內核中開始,運行:
從pyspark.sql進口SparkSession火花=SparkSession.構建器.getOrCreate()
要啟用%的sql運行和可視化SQL查詢的簡寫,使用下麵的代碼片段:
從IPython.core.magic進口line_magic,line_cell_magic,魔法,magics_class@magics_class類DatabricksConnectMagics(魔法):@line_cell_magicdefsql(自我,行,細胞=沒有一個):如果細胞而且行:提高ValueError(“單元格魔法行必須為空”,行)試一試:從autovizwidget.widget.utils進口display_dataframe除了ImportError:打印(“請運行' pip install autovizwidget '以啟用可視化小部件。”)display_dataframe=λx:x返回display_dataframe(自我.get_spark().sql(細胞orgydF4y2Ba行).toPandas())defget_spark(自我):user_ns=get_ipython().user_ns如果“火花”在user_ns:返回user_ns[“火花”]其他的:從pyspark.sql進口SparkSessionuser_ns[“火花”]=SparkSession.構建器.getOrCreate()返回user_ns[“火花”]知識產權=get_ipython()知識產權.register_magics(DatabricksConnectMagics)
PyCharm
請注意
Databricks建議您使用其中任何一種dbx或者是Visual Studio Code的Databricks擴展用於本地開發而不是Databricks Connect。
在開始使用Databricks Connect之前,您必須滿足要求而且設置客戶端用於Databricks Connect。
Databricks Connect配置腳本自動將包添加到項目配置中。
Python 3集群
創建PyCharm項目時,選擇現有的翻譯.從下拉菜單中,選擇您創建的Conda環境(參見需求).
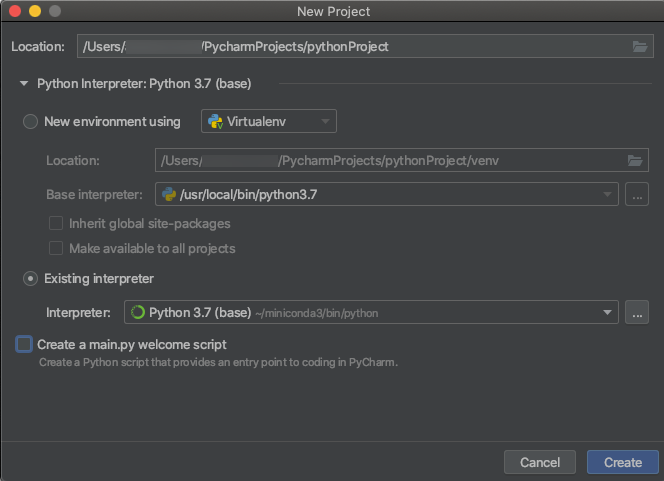
去執行>編輯配置.
添加
PYSPARK_PYTHON = python3作為一個環境變量。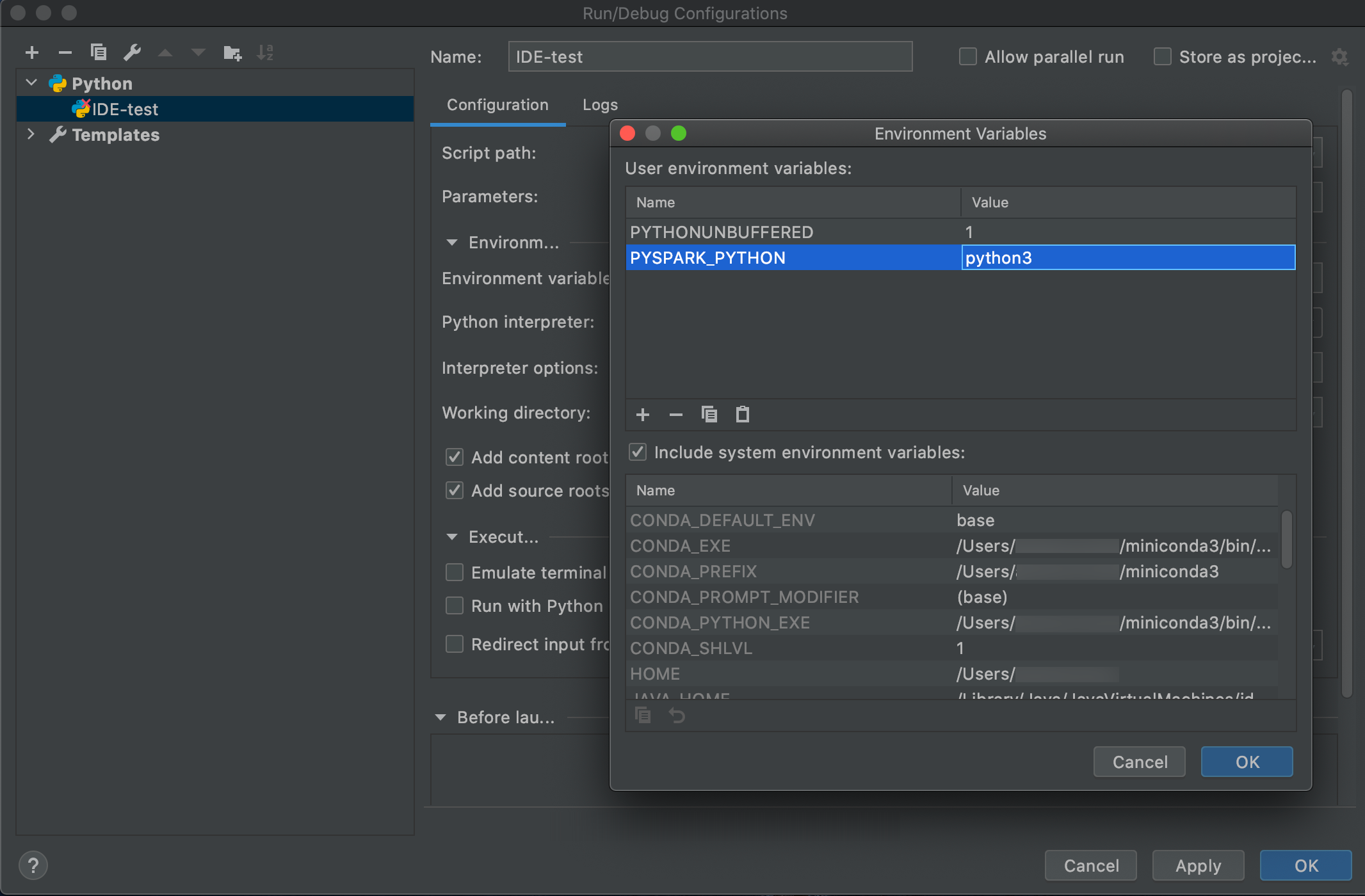


SparkR和RStudio Desktop
請注意
Databricks建議您使用其中任何一種dbx或者是Visual Studio Code的Databricks擴展用於本地開發而不是Databricks Connect。
在開始使用Databricks Connect之前,您必須滿足要求而且設置客戶端用於Databricks Connect。
下載並解包開源Spark到您的本地機器上。選擇與Databricks集群中相同的版本(Hadoop 2.7)。
運行
databricks-connectget-jar-dir.該命令返回類似於/usr/local/lib/python3.5/dist-packages / pyspark / jar.複製的文件路徑上麵一個目錄JAR目錄文件路徑,例如:/usr/local/lib/python3.5/dist-packages / pyspark,即SPARK_HOME目錄中。配置Spark lib路徑和Spark home路徑,將它們添加到R腳本的頂部。集
< spark-lib-path >到步驟1中解壓縮開源Spark包的目錄。集< spark-home-path >從步驟2到Databricks Connect目錄。#指向OSS包的路徑,例如/path/to/…/spark-2.4.0-bin-hadoop2.7圖書館(SparkR,lib.loc=.libPaths(c(file.path(' < spark-lib-path >”,“R”,“自由”),.libPaths())))#指向Databricks Connect PySpark安裝,例如:/path/to/…/ PySparkSys.setenv(SPARK_HOME=“< spark-home-path >”)
啟動Spark會話並開始執行SparkR命令。
sparkR.session()df<-作為。DataFrame(忠實的)頭(df)df1<-有斑紋的(df,函數(x){x},模式(df))收集(df1)
sparklyr和RStudio Desktop
預覽
此功能已在公共預覽.
請注意
Databricks建議您使用其中任何一種dbx或者是Visual Studio Code的Databricks擴展用於本地開發而不是Databricks Connect。
在開始使用Databricks Connect之前,您必須滿足要求而且設置客戶端用於Databricks Connect。
您可以複製使用Databricks Connect在本地開發的依賴於sparklyr的代碼,並在Databricks筆記本電腦或Databricks工作區中的托管RStudio服務器中運行,隻需進行很少或不進行代碼更改。
需求
Sparklyr 1.2或以上版本。
Databricks Runtime 7.3或以上版本,並搭配Databricks Connect。
安裝、配置和使用sparklyr
在RStudio Desktop中,從CRAN安裝sparklyr 1.2或以上版本,或從GitHub安裝最新的主版本。
#從CRAN安裝install.packages(“sparklyr”)#或從GitHub安裝最新的主版本install.packages(“devtools”)devtools::install_github(“sparklyr / sparklyr”)
激活安裝了Databricks Connect的Python環境,並在終端中運行以下命令以獲取
< spark-home-path >:databricks-connect get-spark-home
啟動Spark會話,執行sparklyr命令。
圖書館(sparklyr)sc<-spark_connect(方法=“磚”,spark_home=“< spark-home-path >”)iris_tbl<-copy_to(sc,虹膜,覆蓋=真正的)圖書館(dplyr)src_tbls(sc)iris_tbl% > %數
關閉連接。
spark_disconnect(sc)
IntelliJ (Scala或Java)
請注意
Databricks建議您使用其中任何一種dbx或者是Visual Studio Code的Databricks擴展用於本地開發而不是Databricks Connect。
在開始使用Databricks Connect之前,您必須滿足要求而且設置客戶端用於Databricks Connect。
運行
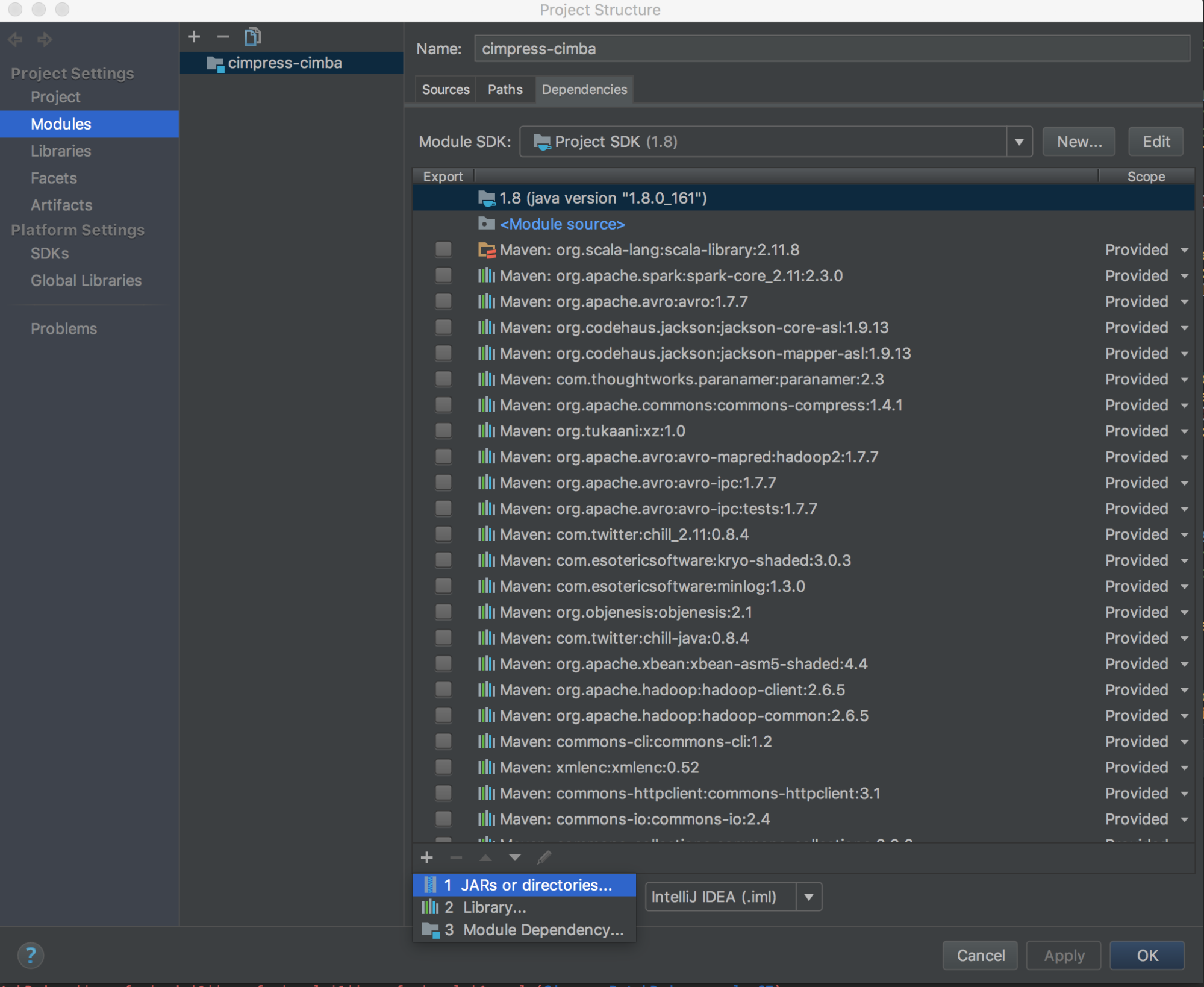
databricks-connectget-jar-dir.將依賴項指向命令返回的目錄。去>項目結構>模塊>依賴>“+”符號> jar或目錄.
為了避免衝突,我們強烈建議從您的類路徑中刪除任何其他Spark安裝。如果這是不可能的,請確保您添加的jar位於類路徑的前麵。特別是,它們必須在任何其他已安裝的Spark版本之前(否則您將使用其中一個其他Spark版本並在本地運行或拋出一個錯誤
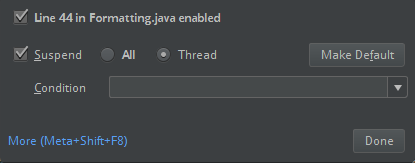
ClassDefNotFoundError).檢查IntelliJ中中斷選項的設置。默認為所有並且如果為調試設置斷點,將導致網絡超時。設置為線程避免停止後台網絡線程。


Eclipse
請注意
Databricks建議您使用其中任何一種dbx或者是Visual Studio Code的Databricks擴展用於本地開發而不是Databricks Connect。
在開始使用Databricks Connect之前,您必須滿足要求而且設置客戶端用於Databricks Connect。
運行
databricks-connectget-jar-dir.將外部jar配置指向命令返回的目錄。去項目菜單>屬性> Java構建路徑>庫>添加外部jar.
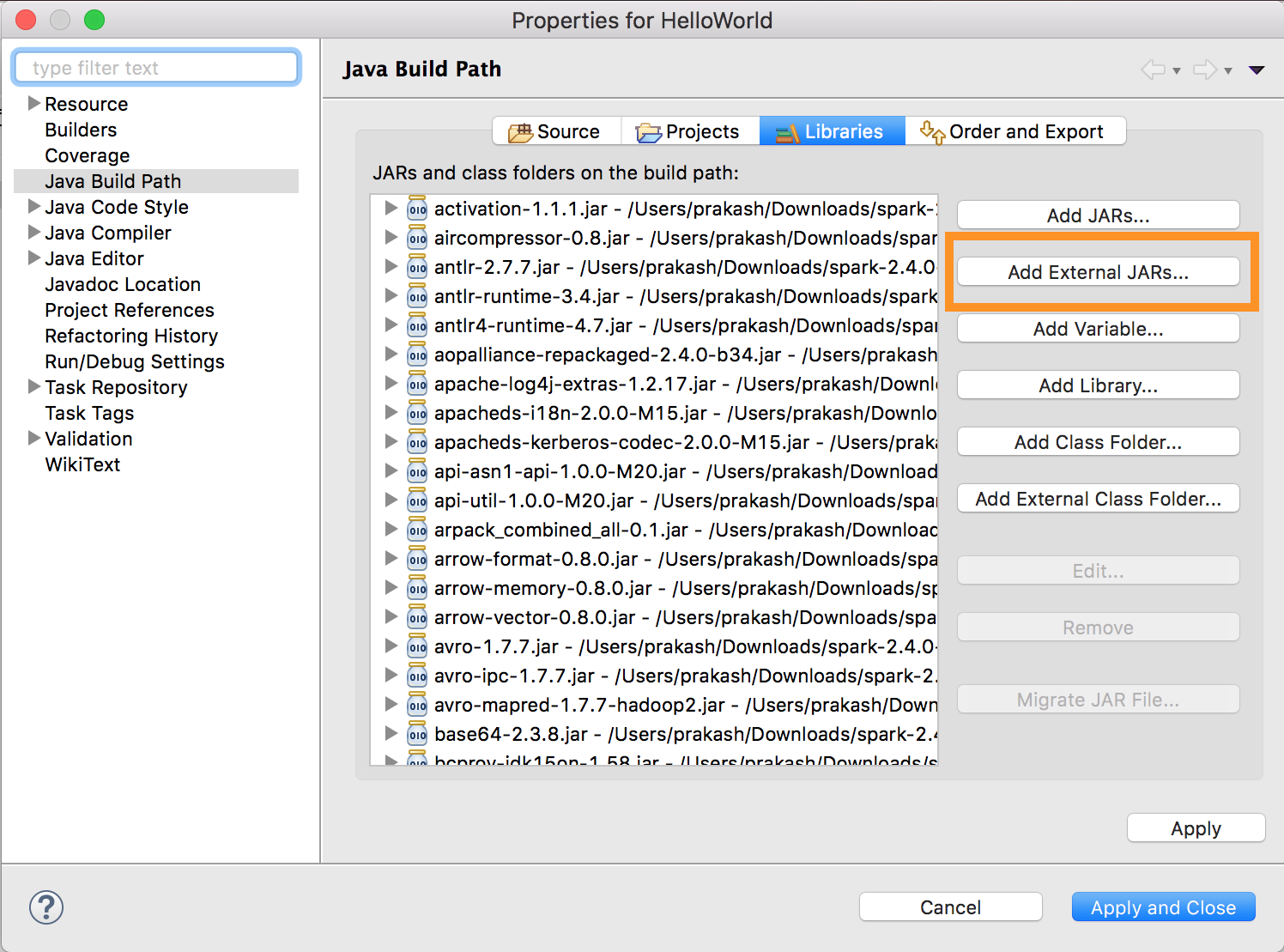
為了避免衝突,我們強烈建議從您的類路徑中刪除任何其他Spark安裝。如果這是不可能的,請確保您添加的jar位於類路徑的前麵。特別是,它們必須在任何其他已安裝的Spark版本之前(否則您將使用其中一個其他Spark版本並在本地運行或拋出一個錯誤
ClassDefNotFoundError).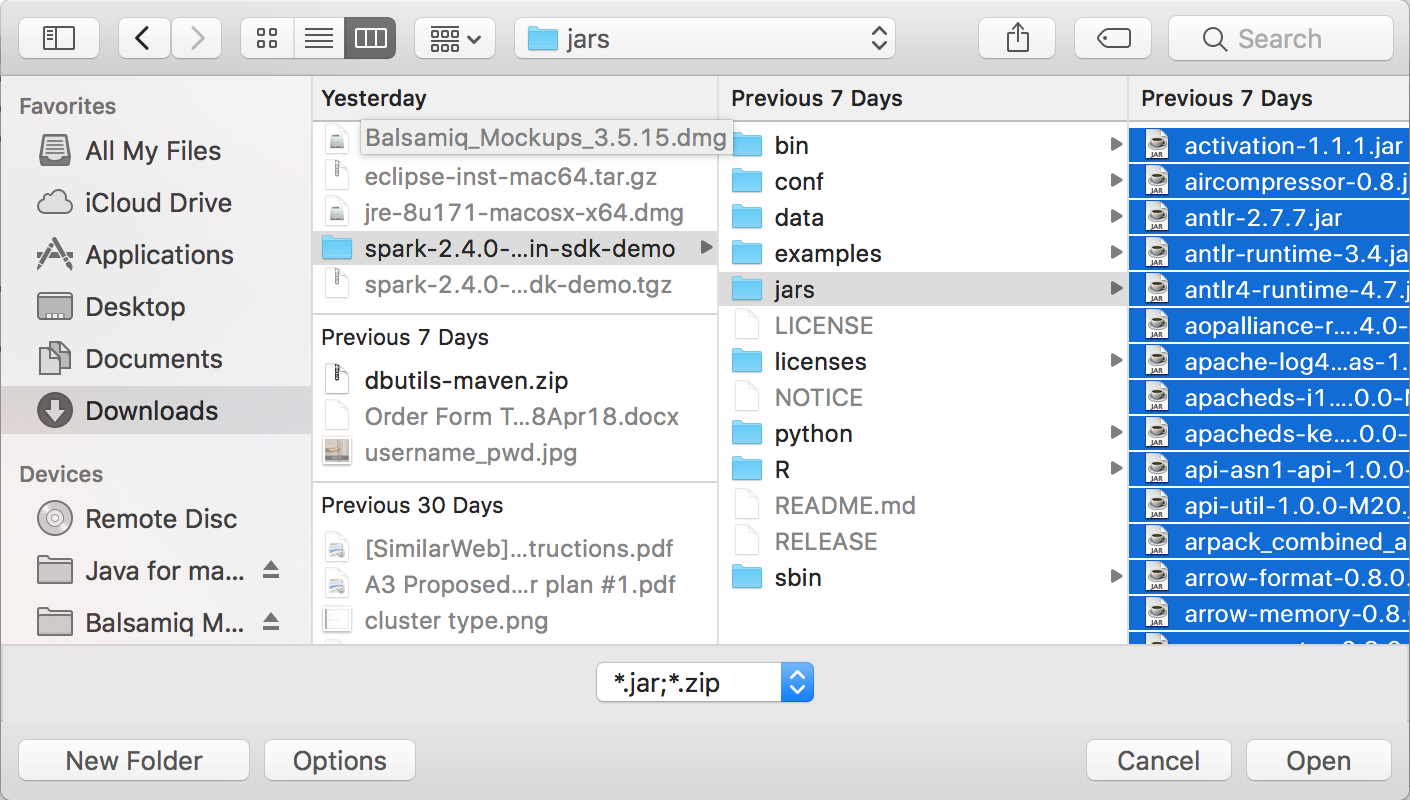


Visual Studio代碼
請注意
Databricks建議您使用其中任何一種dbx或者是Visual Studio Code的Databricks擴展用於本地開發而不是Databricks Connect。
在開始使用Databricks Connect之前,您必須滿足要求而且設置客戶端用於Databricks Connect。
驗證Python擴展安裝。
打開命令麵板(命令+ Shift + P在macOS和Ctrl + Shift + P在Windows / Linux)。
選擇一個Python解釋器。去Code > Preferences > Settings,並選擇python的設置.
運行
databricks-connectget-jar-dir.將命令返回的目錄添加到User Settings JSON下
python.venvPath.這應該被添加到Python配置中。關閉門栓。單擊...在右邊和編輯json設置.修改後的設置如下:
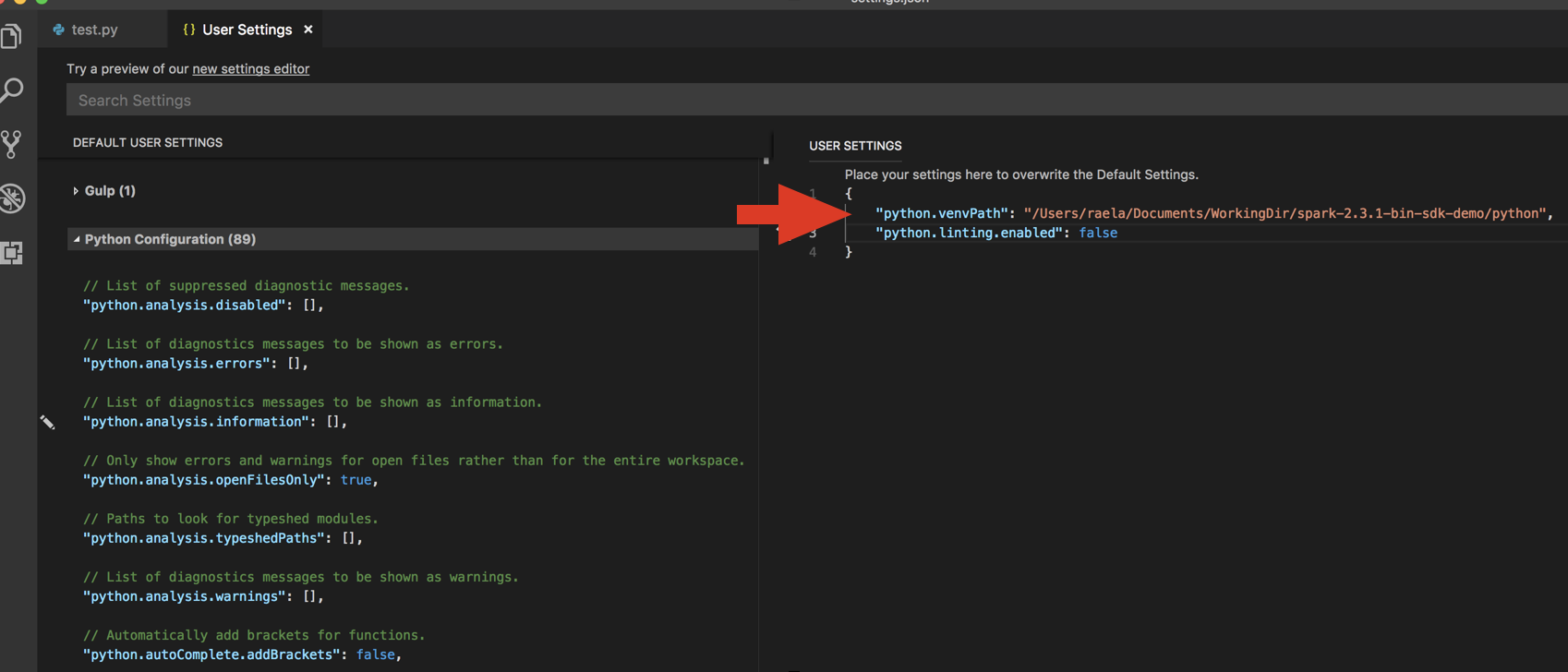
如果在虛擬環境中運行,這是在VS Code中為Python開發的推薦方式,在命令麵板類型中運行
選擇python翻譯並指出你的環境匹配你的集群Python版本。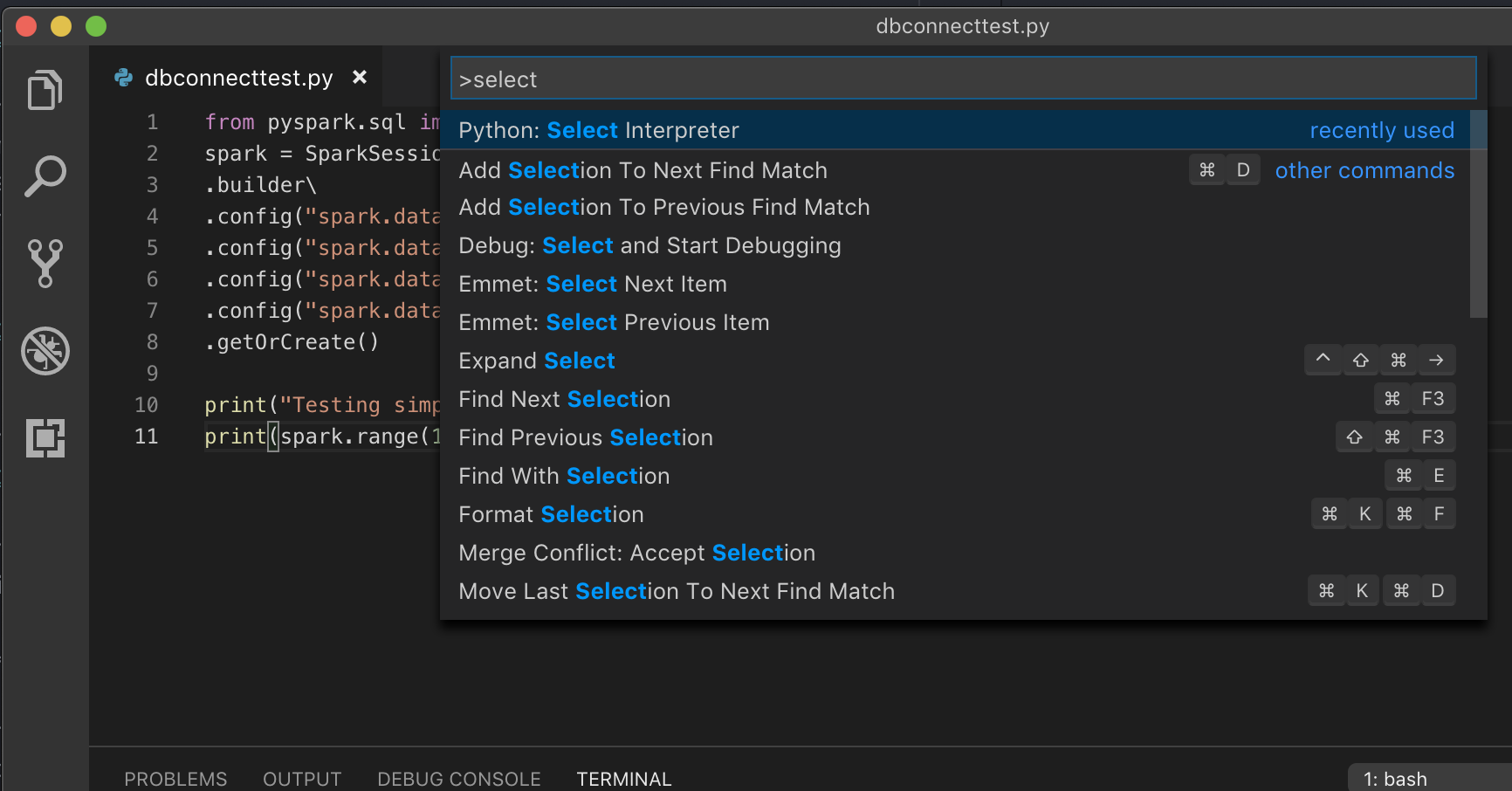
例如,如果您的集群是Python 3.5,那麼您的本地環境應該是Python 3.5。



SBT
請注意
Databricks建議您使用其中任何一種dbx或者是Visual Studio Code的Databricks擴展用於本地開發而不是Databricks Connect。
在開始使用Databricks Connect之前,您必須滿足要求而且設置客戶端用於Databricks Connect。
要使用SBT,必須配置您的build.sbt文件鏈接到Databricks Connect jar,而不是通常的Spark庫依賴。你用unmanagedBase指令在下麵的示例構建文件中,它假設Scala應用程序有一個com.example.Test主要對象:
從IDE運行示例
進口java.util.ArrayList;進口並不知道;進口java.sql.Date;進口org.apache.spark.sql.SparkSession;進口org.apache.spark.sql.types。*;進口org.apache.spark.sql.Row;進口org.apache.spark.sql.RowFactory;進口org.apache.spark.sql.Dataset;公共類應用程序{公共靜態無效主要(字符串[]arg遊戲)拋出異常{SparkSession火花=SparkSession.構建器().瀏覽器名稱(“臨時工演示”).配置(“spark.master”,“本地”).getOrCreate();//創建一個由高溫和低溫組成的Spark DataFrame//通過機場代碼和日期。StructType模式=新StructType(新StructField[]{新StructField(“AirportCode”,數據類型.StringType,假,元數據.空()),新StructField(“日期”,數據類型.DateType,假,元數據.空()),新StructField(“TempHighF”,數據類型.IntegerType,假,元數據.空()),新StructField(“TempLowF”,數據類型.IntegerType,假,元數據.空()),});列表<行>dataList=新ArrayList<行>();dataList.添加(RowFactory.創建(“BLI”,日期.返回對象的值(“2021-04-03”),52,43));dataList.添加(RowFactory.創建(“BLI”,日期.返回對象的值(“2021-04-02”),50,38));dataList.添加(RowFactory.創建(“BLI”,日期.返回對象的值(“2021-04-01”),52,41));dataList.添加(RowFactory.創建(“PDX”,日期.返回對象的值(“2021-04-03”),64,45));dataList.添加(RowFactory.創建(“PDX”,日期.返回對象的值(“2021-04-02”),61,41));dataList.添加(RowFactory.創建(“PDX”,日期.返回對象的值(“2021-04-01”),66,39));dataList.添加(RowFactory.創建(“海”,日期.返回對象的值(“2021-04-03”),57,43));dataList.添加(RowFactory.創建(“海”,日期.返回對象的值(“2021-04-02”),54,39));dataList.添加(RowFactory.創建(“海”,日期.返回對象的值(“2021-04-01”),56,41));數據集<行>臨時工=火花.createDataFrame(dataList,模式);//在Databricks集群上創建一個表,然後填充//包含DataFrame內容的表//如果表在之前運行時已經存在,//先刪除它。火花.sql(“使用默認”);火花.sql(DROP TABLE IF EXISTS demo_temps_table);臨時工.寫()。saveAsTable(“demo_temps_table”);//查詢Databricks集群上的表,返回行//如果機場代碼不是BLI,日期是晚些//比2021-04-01。將結果分組,按高排序//溫度由高到低。數據集<行>df_temps=火花.sql(SELECT * FROM demo_temps_table+“WHERE AirportCode != 'BLI' AND Date > '2021-04-01'”+GROUP BY AirportCode, Date, TempHighF, TempLowF+“TempHighF DESC訂單”);df_temps.顯示();/ /結果://// +-----------+----------+---------+--------+// |AirportCode| Date|TempHighF|TempLowF| .使用實例// +-----------+----------+---------+--------+// | pdx |2021-04-03| 64| 45| .使用實例// | pdx |2021-04-02| 61| 41| .使用實例// | sea |2021-04-03| 57| 43|// | sea |2021-04-02| 54| 39|// +-----------+----------+---------+--------+//刪除Databricks集群中的表火花.sql(DROP TABLE demo_temps_table);}}
從pyspark.sql進口SparkSession從pyspark.sql.types進口*從datetime進口日期火花=SparkSession.構建器.瀏覽器名稱(“temps-demo”).getOrCreate()#創建一個由高溫和低溫組成的Spark數據幀#按機場代碼和日期。模式=StructType([StructField(“AirportCode”,StringType(),假),StructField(“日期”,DateType(),假),StructField(“TempHighF”,IntegerType(),假),StructField(“TempLowF”,IntegerType(),假)])數據=[[“BLI”,日期(2021,4,3.),52,43),[“BLI”,日期(2021,4,2),50,38),[“BLI”,日期(2021,4,1),52,41),[“PDX”,日期(2021,4,3.),64,45),[“PDX”,日期(2021,4,2),61,41),[“PDX”,日期(2021,4,1),66,39),[“海”,日期(2021,4,3.),57,43),[“海”,日期(2021,4,2),54,39),[“海”,日期(2021,4,1),56,41]]臨時工=火花.createDataFrame(數據,模式)在Databricks集群上創建一個表,然後填充# DataFrame的內容。#如果表在之前的運行中已經存在,#先刪除它。火花.sql(使用默認的)火花.sql(刪除表如果存在demo_temps_table)臨時工.寫.saveAsTable(“demo_temps_table”)#查詢Databricks集群的表,返回行#,其中機場代碼不是BLI,日期是稍後#比2021-04-01。將結果分組,按高排序#溫度由高到低。df_temps=火花.sql(SELECT * FROM demo_temps_table\“WHERE AirportCode != 'BLI' AND Date > '2021-04-01'”\GROUP BY AirportCode, Date, TempHighF, TempLowF\“TempHighF DESC訂單”)df_temps.顯示()#結果:## +-----------+----------+---------+--------+# |AirportCode| Date|TempHighF|TempLowF|# +-----------+----------+---------+--------+# | pdx |2021-04-03| 64| 45|# | pdx |2021-04-02| 61| 41|# |海|2021-04-03| 57| 43|# |海|2021-04-02| 54| 39|# +-----------+----------+---------+--------+刪除Databricks集群中的表火花.sql(DROP TABLE demo_temps_table)
進口org.apache.火花.sql.SparkSession進口org.apache.火花.sql.類型._進口org.apache.火花.sql.行進口java.sql.日期對象演示{def主要(arg遊戲:數組[字符串]){瓦爾火花=SparkSession.構建器.主(“本地”).getOrCreate()//創建一個由高溫和低溫組成的Spark DataFrame//通過機場代碼和日期。瓦爾模式=StructType(數組(StructField(“AirportCode”,StringType,假),StructField(“日期”,DateType,假),StructField(“TempHighF”,IntegerType,假),StructField(“TempLowF”,IntegerType,假)))瓦爾數據=列表(行(“BLI”,日期.返回對象的值(“2021-04-03”),52,43),行(“BLI”,日期.返回對象的值(“2021-04-02”),50,38),行(“BLI”,日期.返回對象的值(“2021-04-01”),52,41),行(“PDX”,日期.返回對象的值(“2021-04-03”),64,45),行(“PDX”,日期.返回對象的值(“2021-04-02”),61,41),行(“PDX”,日期.返回對象的值(“2021-04-01”),66,39),行(“海”,日期.返回對象的值(“2021-04-03”),57,43),行(“海”,日期.返回對象的值(“2021-04-02”),54,39),行(“海”,日期.返回對象的值(“2021-04-01”),56,41))瓦爾抽樣=火花.sparkContext.makeRDD(數據)瓦爾臨時工=火花.createDataFrame(抽樣,模式)//在Databricks集群上創建一個表,然後填充//包含DataFrame內容的表//如果表在之前運行時已經存在,//先刪除它。火花.sql(“使用默認”)火花.sql(DROP TABLE IF EXISTS demo_temps_table)臨時工.寫.saveAsTable(“demo_temps_table”)//查詢Databricks集群上的表,返回行//如果機場代碼不是BLI,日期是晚些//比2021-04-01。將結果分組,按高排序//溫度由高到低。瓦爾df_temps=火花.sql(SELECT * FROM demo_temps_table+“WHERE AirportCode != 'BLI' AND Date > '2021-04-01'”+GROUP BY AirportCode, Date, TempHighF, TempLowF+“TempHighF DESC訂單”)df_temps.顯示()/ /結果://// +-----------+----------+---------+--------+// |AirportCode| Date|TempHighF|TempLowF| .使用實例// +-----------+----------+---------+--------+// | pdx |2021-04-03| 64| 45| .使用實例// | pdx |2021-04-02| 61| 41| .使用實例// | sea |2021-04-03| 57| 43|// | sea |2021-04-02| 54| 39|// +-----------+----------+---------+--------+//刪除Databricks集群中的表火花.sql(DROP TABLE demo_temps_table)}}
使用依賴項
通常,主類或Python文件會有其他依賴jar和文件。您可以通過調用來添加此類依賴jar和文件sparkContext.addJar(“path-to-the-jar”)orgydF4y2BasparkContext.addPyFile(文件路徑).,還可以添加Egg文件和zip文件addPyFile ()接口。每次在IDE中運行代碼時,依賴jar和文件都會安裝在集群上。
從自由進口噴火從pyspark.sql進口SparkSession火花=SparkSession.構建器.getOrCreate()sc=火花.sparkContext# sc.setLogLevel(“信息”)打印(“測試簡單計數”)打印(火花.範圍(One hundred.).數())打印("測試addPyFile隔離")sc.addPyFile(“lib.py”)打印(sc.並行化(範圍(10)).地圖(λ我:噴火(2)).收集())類噴火(對象):def__init__(自我,x):自我.x=x
Python + Java udf
從pyspark.sql進口SparkSession從pyspark.sql.column進口_to_java_column,_to_seq,列在這個例子中,udf.jar包含了編譯好的Java / Scala udf:#包com.example##進口org.apache.spark.sql._#進口org.apache.spark.sql.expressions._#進口org.apache.spark.sql.functions.udf##對象測試{# val: UserDefinedFunction = udf((i: Long) => i + 1)#}火花=SparkSession.構建器\.配置(“spark.jars”,“/道路/ / udf.jar”)\.getOrCreate()sc=火花.sparkContextdefplus_one_udf(上校):f=sc._jvm.com.例子.測試.plusOne()返回列(f.應用(_to_seq(sc,[上校),_to_java_column)))sc._jsc.addJar(“/道路/ / udf.jar”)火花.範圍(One hundred.).withColumn(“plusOne”,plus_one_udf(“id”)).顯示()
包com.例子進口org.apache.火花.sql.SparkSession情況下類噴火(x:字符串)對象測試{def主要(arg遊戲:數組[字符串]):單位={瓦爾火花=SparkSession.構建器()....getOrCreate();火花.sparkContext.setLogLevel(“信息”)println(“正在運行簡單的show查詢…”)火花.讀.格式(“鋪”).負載(“/ tmp / x”).顯示()println(“運行簡單的UDF查詢…”)火花.sparkContext.addJar(”。/目標/ scala - 2.11 / hello-world_2.11-1.0.jar”)火花.udf.注冊(“f”,(x:Int)= >x+1)火花.範圍(10).selectExpr(“f (id)”).顯示()println("運行自定義對象查詢…")瓦爾obj=火花.sparkContext.並行化(Seq(噴火(“再見”),噴火(“嗨”)))。收集()println(obj.toSeq)}}
訪問DBUtils
你可以使用dbutils.fs而且dbutils.secrets公用事業磚公用事業模塊。支持的命令包括dbutils.fs.cp,dbutils.fs.head,dbutils.fs.ls,dbutils.fs.mkdirs,dbutils.fs.mv,dbutils.fs.put,dbutils.fs.rm,dbutils.secrets.get,dbutils.secrets.getBytes,dbutils.secrets.list,dbutils.secrets.listScopes.看到文件係統實用程序(dbutls .fs)或運行dbutils.fs.help ()而且秘密實用程序(dbutils.secrets)或運行dbutils.secrets.help ().
從pyspark.sql進口SparkSession從pyspark.dbutils進口DBUtils火花=SparkSession.構建器.getOrCreate()dbutils=DBUtils(火花)打印(dbutils.fs.ls(“dbfs: /))打印(dbutils.秘密.listScopes())
當使用Databricks Runtime 7.3 LTS或以上版本時,要以本地和Databricks集群中都可以工作的方式訪問DBUtils模塊,請使用以下方法get_dbutils ():
defget_dbutils(火花):從pyspark.dbutils進口DBUtils返回DBUtils(火花)
否則,請使用以下方法get_dbutils ():
defget_dbutils(火花):如果火花.相依.得到(“spark.databricks.service.client.enabled”)= =“真正的”:從pyspark.dbutils進口DBUtils返回DBUtils(火花)其他的:進口IPython返回IPython.get_ipython().user_ns[“dbutils”]
瓦爾dbutils=com.磚.服務.DBUtilsprintln(dbutils.fs.ls(“dbfs: /))println(dbutils.秘密.listScopes())
訪問Hadoop文件係統
您也可以直接使用標準Hadoop文件係統接口訪問DBFS:
>進口org.apache.hadoop.fs._//獲取新的DBFS連接>瓦爾dbfs=文件係統.得到(火花.sparkContext.hadoopConfiguration)dbfs:org.apache.hadoop.fs.文件係統=com.磚.後端.守護進程.數據.客戶端.DBFS@二維036335//列出文件>dbfs.listStatus(新路徑(“dbfs: /))res1:數組[org.apache.hadoop.fs.FileStatus]=數組(FileStatus{路徑=dbfs:/$;isDirectory=真正的;…})//打開文件>瓦爾流=dbfs.開放(新路徑(“dbfs: /道路/ / your_file”))流:org.apache.hadoop.fs.FSDataInputStream=org.apache.hadoop.fs.FSDataInputStream@7aa4ef24//獲取文件內容為字符串>進口org.apache.下議院.io._>println(新字符串(IOUtils.toByteArray(流)))
設置Hadoop配置
方法在客戶端上設置Hadoop配置spark.conf.setAPI,應用於SQL和DataFrame操作。的Hadoop配置sparkContext必須在集群配置或使用筆記本設置。這是因為設置了配置sparkContext不綁定到用戶會話,而是應用於整個集群。
故障排除
運行databricks-connect測驗檢查連接問題。本節介紹可能遇到的一些常見問題以及解決方法。
Python版本不匹配
檢查您在本地使用的Python版本至少與集群上的版本具有相同的次要版本(例如,3.5.1與3.5.2是好的,3.5與3.6不是)。
如果本地安裝了多個Python版本,請通過設置Databricks Connect的PYSPARK_PYTHON環境變量(例如,PYSPARK_PYTHON = python3).
服務器未啟用
確保集群中已啟用Spark服務器spark.databricks.service.server.enabled真正的.如果是,你應該在驅動日誌中看到以下幾行:
18/10/25 21:39:18 INFO SparkConfUtils$: Set spark config: spark. databicks .service.server.enabled -> true…18/10/25 21:39:21 INFO SparkContext: Loading SparkServiceRPCServer 18/10/25 21:39:21 INFO SparkServiceRPCServer: Starting SparkServiceRPCServer 18/10/25 21:39:21 INFO Server: jetty-9.3.20。v20170531 18/10/25 21:39:21 INFO AbstractConnector: Started ServerConnector@6a6c7f42 {HTTP/1.1,[HTTP/1.1]}{0.0.0.0:15001} 18/10/25 21:39:21 INFO Server: Started @5879ms
衝突的PySpark安裝
的databricks-connect包與PySpark衝突。在Python中初始化Spark上下文時會導致錯誤。這可以通過幾種方式表現出來,包括“流損壞”或“類未找到”錯誤。如果在Python環境中安裝了PySpark,請確保在安裝databicks -connect之前已將其卸載。卸載PySpark後,請確保完全重新安裝Databricks Connect包:
pip uninstall pyspark pip uninstall databicks -connect pip install -U“databricks-connect = = 9.1 *”。#或x.y *來匹配您的集群版本。
相互衝突的SPARK_HOME
如果您以前在計算機上使用過Spark,則您的IDE可能已配置為使用其他版本的Spark之一,而不是Databricks Connect Spark。這可以通過幾種方式表現出來,包括“流損壞”或“類未找到”錯誤。屬性的值可以查看正在使用哪個版本的SparkSPARK_HOME環境變量:
係統.出.println(係統.采用(“SPARK_HOME”));
進口操作係統打印(操作係統.環境[“SPARK_HOME”])
println(sys.env.得到(“SPARK_HOME”))
衝突或缺失路徑二進製條目
有可能您的PATH已配置,以便命令像spark-shell將運行之前安裝的其他二進製文件,而不是Databricks Connect提供的二進製文件。這會導致databricks-connect測驗失敗。您應該確保Databricks Connect二進製文件優先,或者刪除之前安裝的二進製文件。
如果你不能運行命令spark-shell,也有可能您的PATH沒有被自動設置皮普安裝您需要添加安裝箱子手動到您的PATH。即使沒有設置,也可以使用Databricks Connect與ide連接。然而,databricks-connect測驗命令是行不通的。
集群上的序列化設置衝突
如果您在運行時看到“流損壞”錯誤databricks-connect測驗,這可能是由於不兼容的集群序列化配置。例如,設置spark.io.compression.codec配置可能會導致此問題。要解決此問題,請考慮從集群設置中刪除這些配置,或在Databricks Connect客戶端中設置配置。
找不到winutils.exe在Windows上
如果您在Windows上使用Databricks Connect,請參閱:
錯誤殼牌:失敗的來定位的winutils二進製在的hadoop二進製路徑java.io.IOException:可以不定位可執行的零\箱子\winutils.exe在的Hadoop二進製文件.
按照說明操作Windows下配置Hadoop路徑.
限製
Databricks Connect不支持以下Databricks特性和第三方平台:Beplay体育安卓版本
統一目錄.
結構化的流。
在遠程集群上運行不屬於Spark作業的任意代碼。
原生Scala, Python和R api用於Delta表操作(例如,
DeltaTable.forPath)不受支持。然而,SQL API (spark.sql(…)Delta Lake操作和Spark API(例如,spark.read.load)都支持。進入副本。
使用SQL函數,Python或Scala udf,這些都是服務器目錄的一部分。但是,本地引入的Scala和Python udf可以工作。
Apache飛艇0.7.x而且是low.
連接到集群表訪問控製.
連接到啟用了進程隔離的集群(換句話說,其中
spark.databricks.pyspark.enableProcessIsolation設置為真正的).δ
克隆SQL命令。全局臨時視圖。
考拉.
創建表格表格作為選擇...SQL命令並不總是有效。相反,使用spark.sql(“選擇……”).write.saveAsTable(“表”).