磚擴展Visual Studio代碼參考
請注意
學習如何快速開始使用磚擴展Visual Studio代碼,看到磚擴展Visual Studio代碼教程。
磚擴展Visual Studio代碼允許您連接到遠程數據磚的工作區Visual Studio代碼集成開發環境(IDE)在當地的開發機器上運行。通過這些連接,您可以:
同步本地代碼Visual Studio中開發的代碼的代碼在你的遠程工作空間。
從Visual Studio代碼運行本地Python代碼文件在遠程磚集群的工作區。
運行本地Python代碼文件(
. py)和Python, R, Scala, SQL筆記本(. py,.ipynb,。r,. scala,. sql)從Visual Studio代碼自動磚在遠程工作的工作區。
請注意
的磚擴展Visual Studio代碼支持運行R, Scala和SQL筆記本自動工作,但是不提供任何更深的Visual Studio代碼中支持這些語言。
在你開始之前
之前,您可以使用Visual Studio的磚擴展代碼,你的磚工作區和地方發展機器必須符合以下要求。
工作空間的需求
你必須至少有一個磚工作區,和工作區必須符合以下要求:
當地開發機需求
你必須有以下本地開發機器上:
Visual Studio代碼1.69.1或更高版本。查看安裝的版本,點擊代碼>關於Visual Studio代碼在Linux或macOS和從主菜單中幫助>在Windows上。下載、安裝和配置Visual Studio代碼,看看設置Visual Studio代碼。
Visual Studio代碼必須配置為Python代碼,包括Python解釋器的可用性。有關詳細信息,請參見開始使用Python在VS代碼。
磚擴展Visual Studio代碼。看到安裝並打開擴展。
開始
之前,您可以使用Visual Studio的磚擴展代碼必須下載、安裝、開放、擴展和配置,如下所示。
安裝並打開擴展
在Visual Studio代碼,打開擴展視圖(視圖>擴展從主菜單中)。
在搜索擴展市場,輸入磚。
單擊磚條目。
請注意
有幾個條目磚在他們的頭銜。一定要點擊一個隻有磚在其標題和藍磚旁邊的複選標記圖標。
點擊安裝。
重新啟動Visual Studio代碼。
打開擴展:在側邊欄,點擊磚圖標。
配置項目
擴展開,打開你的代碼項目的文件夾在Visual Studio代碼(文件>打開文件夾)。如果你沒有一個代碼項目然後使用PowerShell, Linux或macOS終端,或命令提示符窗口,創建一個文件夾,切換到新文件夾,然後打開Visual Studio代碼從文件夾中。例如:
mkdir databricks-democddatabricks-demo代碼。
醫學博士databricks-democddatabricks-demo代碼。
提示
如果你得到這個錯誤命令不發現:代碼,請參閱從命令行啟動在Visual Studio代碼文檔。
配置擴展
使用擴展,你開始通過建立磚擴展和你的目標之間的身份驗證數據磚的工作區。
身份驗證配置
的磚擴展Visual Studio的代碼實現部分磚客戶端統一身份驗證標準,統一和一致的體係結構和編程方法來驗證。這種方法有助於使設置和自動化驗證磚更集中的和可預測的。它允許您配置數據磚身份驗證一次,然後使用該配置多個磚工具和sdk沒有進一步驗證配置更改。
之前,您可以使用Visual Studio的磚擴展代碼,您必須設置身份驗證數據磚之間的擴展Visual Studio代碼和數據磚工作區。取決於您想要使用的類型的身份驗證,完成你的設置通過完成目標的指令數據磚身份驗證類型。
設置身份驗證配置概要文件
下麵的說明假定您已經建立了一個磚與磚的必填字段配置概要文件的驗證類型。看到磚配置概要文件和配置文件你的驗證類型選項卡或部分身份驗證數據磚自動化。
您的項目和擴展開,做到以下幾點:
在配置窗格中,單擊配置數據磚。
請注意
如果配置數據磚是不可見的,點擊齒輪(配置工作空間旁邊)圖標配置代替。
在命令麵板,因為磚的主機,輸入您的工作區實例URL例如,
https://dbc-a1b2345c-d6e7.cloud.m.eheci.com。然後按輸入。列表中選擇你的目標數據磚配置概要文件的URL。

擴展項目中創建一個隱藏文件夾命名.databricks如果它不存在。擴展還創建了一個文件在這個文件夾命名project.json如果它不存在。這個文件包含您輸入的URL,以及一些磚認證細節的磚擴展Visual Studio代碼需要操作。
擴展還增加了一個隱藏的.gitignore文件的項目如果文件不存在或現有的.gitignore不能被發現在任何父文件夾。如果一個新的.gitignore創建文件,擴展添加一個.databricks /進入這個新的文件。如果發現現有的延伸.gitignore文件,它添加了一個.databricks /進入現有的文件。
繼續設置集群。
建立了OAuth U2M身份驗證
預覽
這個特性是在公共預覽。
AWS支持OAuth用戶機器上的磚(U2M)身份驗證。這使您能夠產生短暫的(一個小時)OAuth訪問令牌,這樣可以排除意外暴露的風險長期令牌如磚個人通過版本控製簽到或其他方式訪問令牌。這也使得更好的服務器端會話失效和範圍。
本節假設您已經完成了OAuth U2M身份驗證設置說明OAuth user-to-machine (U2M)身份驗證。
OAuth M2M成套設置身份驗證,您的項目和擴展開,做到以下幾點:
在配置窗格中,單擊配置數據磚。
請注意
如果配置數據磚是不可見的,點擊齒輪(配置工作空間旁邊)圖標配置代替。
在命令麵板,因為磚的主機,輸入您的工作區實例URL例如,
https://dbc-a1b2345c-d6e7.cloud.m.eheci.com。然後按輸入。選擇OAuth用戶(機)。
在web瀏覽器完成屏幕上的指令完成驗證你的磚賬戶和允許所有api訪問。
擴展項目中創建一個隱藏文件夾命名.databricks如果它不存在。擴展還創建了一個文件在這個文件夾命名project.json如果它不存在。這個文件包含您輸入的URL,以及一些磚認證細節的磚擴展Visual Studio代碼需要操作。
擴展還增加了一個隱藏的.gitignore文件的項目如果文件不存在或現有的.gitignore不能被發現在任何父文件夾。如果一個新的.gitignore創建文件,擴展添加一個.databricks /進入這個新的文件。如果發現現有的延伸.gitignore文件,它添加了一個.databricks /進入現有的文件。
繼續設置集群。
設置集群
擴展和代碼項目開了,一個磚配置概要文件已經設置,選擇您想要使用現有的集群磚,或者創建一個新的集群磚並使用它。
使用現有的集群
如果你有一個你想使用現有集群磚,做以下之一:
在集群窗格,請執行以下操作:
請注意
的集群窗格中似乎隻有
views.cluster實驗功能啟用。看到設置。您想要使用的集群,旁邊點擊插頭(附加集群)圖標。
提示
如果集群中不可見集群窗格中,單擊過濾器(過濾器集群)圖標來見所有集群,集群由我創建,或運行集群。或者,單擊箭頭的圓圈(刷新)過濾器圖標旁邊的圖標。
擴展將集群ID添加到您的項目的代碼
.databricks / project.json文件,例如“clusterId”:“1234 - 567890 abcd12e3”。這個過程就完成了。繼續設置工作區目錄。
在配置窗格,請執行以下操作:
旁邊集群,點擊齒輪(集群配置)圖標。
在命令麵板,點擊您想要使用的集群。
擴展將集群ID添加到您的項目的代碼
.databricks / project.json文件,例如“clusterId”:“1234 - 567890 abcd12e3”。這個過程就完成了。繼續設置工作區目錄。



創建一個新的集群
如果你沒有現有的集群磚,或者你想要創建一個新的和使用它,做到以下幾點:
在配置旁邊的窗格中,集群,點擊齒輪(集群配置)圖標。
在命令麵板,點擊創建新集群。
當提示打開外部網站(磚工作區),點擊開放。
如果提示,登錄到你的磚工作區。
按照指示創建一個集群。
請注意
磚建議您創建一個個人計算集群。這使您能夠立即開始運行工作負載,減少計算管理開銷。
集群的創建和運行後,回到Visual Studio代碼。
做下列之一:
在集群窗格中,您希望使用的集群,旁邊點擊插頭(附加集群)圖標。
請注意
的集群窗格中似乎隻有
views.cluster實驗功能啟用。看到設置。
提示
如果集群不可見,請單擊過濾器(過濾器集群)圖標來見所有集群,集群由我創建,或運行集群。或者,單擊箭頭的圓圈(刷新)圖標。
擴展將集群ID添加到項目的代碼
.databricks / project.json文件,例如“clusterId”:“1234 - 567890 abcd12e3”。這個過程就完成了。繼續設置工作區目錄。
在配置旁邊的窗格中,集群,點擊齒輪(集群配置)圖標。
在命令麵板,點擊您想要使用的集群。
擴展將集群ID添加到項目的代碼
.databricks / project.json文件,例如“clusterId”:“1234 - 567890 abcd12e3”。繼續設置工作區目錄。
設置工作區目錄
擴展和代碼項目開了,一個磚配置概要文件已經設置,使用磚擴展Visual Studio代碼來創建一個新的工作區目錄和使用它,或選擇現有的工作區目錄。
請注意
磚擴展Visual Studio代碼隻能用它創建工作區目錄。你不能使用現有的工作空間目錄在您的工作空間中,除非它是由擴展。
使用工作區目錄的磚擴展Visual Studio代碼,您必須使用0.3.5或更高版本的擴展,和你的磚集群必須安裝磚運行時的11.2或更高。
工作區目錄是默認設置,開始0.3.15版本的擴展。然而,如果你設置擴展使用磚回購而不是工作區目錄,您可以設置擴展回到使用工作區目錄如下:
擴展和代碼項目開了,一個磚配置概要文件已經設置,在命令麵板(視圖>命令麵板),類型
偏好:開放用戶設置,然後單擊偏好:開放的用戶設置。在用戶選項卡,擴大擴展,然後單擊磚。
為同步:目的地類型中,選擇工作空間。
退出並重新啟動Visual Studio代碼。
注意,改變了設置之後使用磚回購使用工作區目錄,您可能需要手動同步代碼到您的工作空間中。要做到這一點,您創建一個新的工作區目錄後在接下來的過程中,單擊箭頭的圓圈(開始同步旁邊)圖標同步的目的地。
創建一個新的工作區目錄
創建一個新的工作區目錄,請執行以下操作:
在配置旁邊的窗格中,同步的目的地,點擊齒輪(配置同步目的地)圖標。
在命令麵板,點擊創建新的同步目的地。
為新工作區目錄,輸入一個名字,然後按輸入。
擴展創建一個目錄中指定的目錄名稱
/用戶/ <用戶名> / .ide在工作區中,然後添加代碼項目的工作區目錄的路徑.databricks / project.json文件,例如“workspacePath”:“/用戶/ <用戶名> / .ide / < your-directory-name >”。請注意
如果遠程工作區目錄的名字不匹配你的本地代碼項目的名稱、圖標出現這個警告信息:遠程同步目的地名稱不匹配當前Visual Studio代碼工作區名稱。你可以忽略這個警告,如果你不需要名字匹配。
設置工作區目錄後,開始與工作區目錄同步通過點擊箭頭的圓圈(開始同步旁邊)圖標同步的目的地。


重要的
磚擴展Visual Studio代碼隻執行單向、自動同步文件變更從你當地的Visual Studio代碼項目相關的工作區目錄在你的遠程數據磚工作區。這個偏遠的工作區目錄中的文件的目的是瞬態。不發起更改這些文件從遠程工作空間內,隨著這些變化不會被同步回本地項目。
繼續開發任務。
重用現有的工作區目錄
如果你有一個現有的工作區目錄,您在前麵創建的磚擴展Visual Studio代碼和想要重用在當前Visual Studio項目代碼,然後執行以下操作:
在配置旁邊的窗格中,同步的目的地,點擊齒輪(配置同步目的地)圖標。
在命令麵板從列表中,選擇工作區目錄的名字。
擴展添加代碼項目的工作區目錄的路徑.databricks / project.json文件,例如“workspacePath”:“/用戶/ <用戶名> / .ide / < your-directory-name >”。
請注意
如果遠程工作區目錄的名字不匹配你的本地代碼項目的名稱、圖標出現這個警告信息:遠程同步目的地名稱不匹配當前Visual Studio代碼工作區名稱。你可以忽略這個警告,如果你不需要名字匹配。
設置工作區目錄後,開始與工作區目錄同步通過點擊箭頭的圓圈(開始同步旁邊)圖標同步的目的地。
重要的
磚擴展Visual Studio代碼隻執行單向、自動同步文件變更從你當地的Visual Studio代碼項目相關的工作區目錄在你的遠程數據磚工作區。這個偏遠的工作區目錄中的文件的目的是瞬態。不發起更改這些文件從遠程工作空間內,隨著這些變化不會被同步回本地項目。
繼續開發任務。
設置存儲庫
請注意
磚不建議您使用磚與磚回購的擴展Visual Studio代碼,除非工作區目錄不可用。看到設置工作區目錄。
如果您選擇使用磚回購而不是工作區目錄在你的磚工作區,然後擴展代碼項目打開時,和一個磚配置概要文件已經設置,使用磚擴展Visual Studio代碼來創建一個新的存儲庫在磚回購協議和使用它,或選擇現有的存儲庫與磚磚回購,您在前麵創建的擴展Visual Studio代碼和想要重用。
請注意
的磚擴展Visual Studio代碼隻能創建存儲庫。你不能使用現有的存儲庫工作區中。
使磚擴展Visual Studio代碼在磚磚內回購的使用存儲庫工作區,您必須首先設置擴展的同步:目的地類型設置為回購如下:
擴展和代碼項目開了,一個磚配置概要文件已經設置,在命令麵板(視圖>命令麵板),類型
偏好:開放用戶設置,然後單擊偏好:開放的用戶設置。在用戶選項卡,擴大擴展,然後單擊磚。
為同步:目的地類型中,選擇回購。
退出並重新啟動Visual Studio代碼。
創建一個新的回購
請注意
磚不建議您使用磚與磚回購的擴展Visual Studio代碼,除非工作區目錄不可用。看到設置工作區目錄。
創建一個新的存儲庫,執行以下操作:
在配置旁邊的窗格中,同步的目的地,點擊齒輪(配置同步目的地)圖標。
在命令麵板,點擊創建新的同步目的地。
類型在磚回購的新的存儲庫的名稱,然後按輸入。
擴展附加字符
.ide結束的回購的名字,然後將回購的工作區路徑添加到項目的代碼.databricks / project.json文件,例如“workspacePath”:“/工作區/回購/ someone@example.com/my-repo.ide”。請注意
如果遠程回購的名字不匹配您的本地代碼項目的名稱、圖標出現這個警告信息:遠程同步目的地名稱不匹配當前Visual Studio代碼工作區名稱。你可以忽略這個警告,如果你不需要名字匹配。
設置存儲庫之後,開始與存儲庫同步通過點擊箭頭的圓圈(開始同步旁邊)圖標同步的目的地。
重要的
磚擴展Visual Studio代碼隻執行單向、自動同步文件從你當地的Visual Studio代碼更改項目相關庫的遠程數據磚工作區。這些遠程存儲庫文件的目的是瞬態。不發起更改這些文件從遠程存儲庫中,隨著這些變化不會被同步回本地項目。
繼續開發任務。
重用現有的回購
請注意
磚不建議您使用磚與磚回購的擴展Visual Studio代碼,除非工作區目錄不可用。看到設置工作區目錄。
如果你有一個現有的庫與磚磚回購,您在前麵創建的擴展Visual Studio代碼和想要重用在當前Visual Studio項目代碼,然後執行以下操作:
在配置旁邊的窗格中,同步的目的地,點擊齒輪(配置同步目的地)圖標。
在命令麵板從列表中,選擇存儲庫的名字。
這個擴展將回購的工作區路徑添加到項目的代碼
.databricks / project.json文件,例如“workspacePath”:“/工作區/回購/ someone@example.com/my-repo.ide”。請注意
如果遠程回購的名字不匹配您的本地代碼項目的名稱、圖標出現這個警告信息:遠程同步目的地名稱不匹配當前Visual Studio代碼工作區名稱。你可以忽略這個警告,如果你不需要名字匹配。
設置存儲庫之後,開始與存儲庫同步通過點擊箭頭的圓圈(開始同步旁邊)圖標同步的目的地。
重要的
磚擴展Visual Studio代碼隻執行單向、自動同步文件從你當地的Visual Studio代碼更改項目相關庫的遠程數據磚工作區。這些遠程存儲庫文件的目的是瞬態。不發起更改這些文件從遠程存儲庫中,隨著這些變化不會被同步回本地項目。
繼續開發任務。
開發任務
配置後的磚擴展Visual Studio代碼,您可以使用擴展集群上運行本地Python文件在一個偏遠的磚工作區,或運行本地Python文件或本地Python, R, Scala,或SQL筆記本作為一個工作在一個偏遠的工作區,如下。
如果你沒有一個本地文件或筆記本測試的磚擴展Visual Studio代碼,這裏有一些基本的代碼,您可以添加到您的項目:
從pyspark.sql進口SparkSession從pyspark.sql.types進口*火花=SparkSession。構建器。getOrCreate()模式=StructType([StructField(“CustomerID”,IntegerType(),假),StructField(“FirstName”,StringType(),假),StructField(“姓”,StringType(),假)])數據=((1000年,“Mathijs”,“Oosterhout-Rijntjes”),(1001年,Joost的,“範Brunswijk”),(1002年,“斯坦”,“Bokenkamp”]]beplay体育app下载地址=火花。createDataFrame(數據,模式)beplay体育app下载地址。顯示()#輸出:## + - - - - - - - - - - - - - - - - - - - - - - - + - - - - - - - - - - - - - - - - - - - +# | CustomerID | FirstName LastName | |# + - - - - - - - - - - - - - - - - - - - - - - - + - - - - - - - - - - - - - - - - - - - +# | 1000 | Mathijs | Oosterhout-Rijntjes |# | 1001 | Joost van Brunswijk | |# | 1002 |斯坦| Bokenkamp |# + - - - - - - - - - - - - - - - - - - - - - - - + - - - - - - - - - - - - - - - - - - - +
#磚筆記本的來源從pyspark.sql.types進口*模式=StructType([StructField(“CustomerID”,IntegerType(),假),StructField(“FirstName”,StringType(),假),StructField(“姓”,StringType(),假)])數據=((1000年,“Mathijs”,“Oosterhout-Rijntjes”),(1001年,Joost的,“範Brunswijk”),(1002年,“斯坦”,“Bokenkamp”]]beplay体育app下载地址=火花。createDataFrame(數據,模式)beplay体育app下载地址。顯示()#輸出:## + - - - - - - - - - - - - - - - - - - - - - - - + - - - - - - - - - - - - - - - - - - - +# | CustomerID | FirstName LastName | |# + - - - - - - - - - - - - - - - - - - - - - - - + - - - - - - - - - - - - - - - - - - - +# | 1000 | Mathijs | Oosterhout-Rijntjes |# | 1001 | Joost van Brunswijk | |# | 1002 |斯坦| Bokenkamp |# + - - - - - - - - - - - - - - - - - - - - - - - + - - - - - - - - - - - - - - - - - - - +
#磚筆記本的來源圖書館(SparkR)sparkR.session()數據< -列表(列表(1000升,“Mathijs”,“Oosterhout-Rijntjes”),列表(1001升,“Joost”,“範Brunswijk”),列表(1002升,“斯坦”,“Bokenkamp”))模式< -structType(structField(“CustomerID”,“整數”),structField(“FirstName”,“字符串”),structField(“姓”,“字符串”))df< -createDataFrame(數據=數據,模式=模式)showDF(df)#輸出:## + - - - - - - - - - - - - - - - - - - - - - - - + - - - - - - - - - - - - - - - - - - - +# | CustomerID | FirstName LastName | |# + - - - - - - - - - - - - - - - - - - - - - - - + - - - - - - - - - - - - - - - - - - - +# | 1000 | Mathijs | Oosterhout-Rijntjes |# | 1001 | Joost van Brunswijk | |# | 1002 |斯坦| Bokenkamp |# + - - - - - - - - - - - - - - - - - - - - - - - + - - - - - - - - - - - - - - - - - - - +
/ /磚筆記本的來源進口org。apache。火花。sql。類型。_進口org。apache。火花。sql。行瓦爾模式=StructType(數組(StructField(“CustomerID”,IntegerType,假),StructField(“FirstName”,StringType,假),StructField(“姓”,StringType,假)))瓦爾數據=列表(行(1000年,“Mathijs”,“Oosterhout-Rijntjes”),行(1001年,“Joost”,“範Brunswijk”),行(1002年,“斯坦”,“Bokenkamp”),)瓦爾抽樣=火花。sparkContext。makeRDD(數據)瓦爾beplay体育app下载地址=火花。createDataFrame(抽樣,模式)顯示(beplay体育app下载地址)/ /輸出:/ // / + - - - - - - - - - - - + - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - +/ / | CustomerID | FirstName LastName | |/ / + - - - - - - - - - - - + - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - +/ / | 1000 | Mathijs | Oosterhout-Rijntjes |/ / | 1001 | Joost van Brunswijk | |/ / | 1002 |斯坦| Bokenkamp |/ / + - - - - - - - - - - - + - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - +
——磚筆記本的來源創建表如果不存在zzz_beplay体育app下载地址customers(CustomerIDINT,FirstName字符串,姓字符串);- - - - - - - - - - - - - -命令插入成zzz_beplay体育app下载地址customers值(1000年,“Mathijs”,“Oosterhout-Rijntjes”),(1001年,“Joost”,“範Brunswijk”),(1002年,“斯坦”,“Bokenkamp”);- - - - - - - - - - - - - -命令選擇*從zzz_beplay体育app下载地址customers;——輸出:- - -- + - - - - - - - - - - - - - - - - - - - + - - - - - - - - - - - - - - - - - - - +——| CustomerID | FirstName LastName | |- + - - - - - - - - - - - - - - - - - - - + - - - - - - - - - - - - - - - - - - - +——| 1000 | Mathijs | Oosterhout-Rijntjes |——| 1001 | Joost | van Brunswijk |——| 1002 |斯坦| Bokenkamp |- + - - - - - - - - - - - - - - - - - - - + - - - - - - - - - - - - - - - - - - - +- - - - - - - - - - - - - -命令下降表zzz_beplay体育app下载地址customers;
啟用PySpark和磚實用程序代碼完成
要啟用智能感知(也稱為代碼自動完成在Visual Studio代碼代碼編輯器PySpark,磚公用事業等,以及相關的全局變量火花和dbutils和你的代碼,請執行以下操作項目打開:
在命令麵板(視圖>命令麵板),類型
磚:配置自動完成為磚全局變量並按輸入。按照屏幕上的提示,讓磚擴展Visual Studio代碼安裝PySpark為您的項目,並添加或修改
__builtins__.pyi為您的項目文件,使磚實用工具。
您現在可以使用全局變量等火花和dbutils在您的代碼中沒有聲明任何相關進口事先聲明。
運行或調試與磚連接的Python代碼
Visual Studio代碼包括磚擴展磚連接。您可以使用磚從磚擴展Visual Studio中連接個人Python代碼運行,分步調試(. py)文件和Python Jupyter筆記本(.ipynb)。磚擴展Visual Studio代碼包括磚的磚連接運行時13.0和更高版本。磚的早期版本中不支持連接。
磚連接要求
之前,您可以使用磚從內部連接的磚擴展Visual Studio代碼,您必須首先滿足磚連接要求。這些需求包括諸如工作區與統一目錄啟用,集群運行磚與集群運行時13.0或更高版本和單用戶或共享訪問模式,和一個本地版本的Python安裝的主要和次要版本匹配的Python安裝在集群。
步驟1:創建一個Python虛擬環境
創建並激活一個Python虛擬環境為您的Python代碼項目。Python虛擬環境有助於確保你的代碼項目使用兼容版本的Python和Python包(在這種情況下,數據磚連接包)。本文說明和示例使用venvPython虛擬環境。創建一個虛擬環境中使用Pythonvenv:
從Visual Studio代碼終端(視圖>終端)設置為您的Python代碼項目的根目錄,指導
venv使用Python的虛擬環境中,然後創建虛擬環境的支持一個隱藏目錄中的文件命名.venv在您的Python代碼項目的根目錄,通過運行下麵的命令:# Linux和macOSpython3.10 - m venv。/ .venv#窗口python3.10 - m venv。\。venv
前麵的命令使用Python 3.10,匹配的主要和次要的數據磚的Python版本13.0運行時使用。一定要使用Python的主要和次要版本匹配您的集群的Python安裝的版本。
如果Visual Studio代碼顯示消息“我們發現創建了一個新的環境。你想選擇的工作區文件夾,“點擊是的。
使用
venv激活虛擬環境。看到venv文檔使用正確的命令,根據你的操作係統和終端類型。例如,在macOS運行zsh:源/ .venv / bin /激活你會知道你的虛擬環境是激活虛擬環境的名稱(例如,
.venv)顯示在括號之前終端提示符。隨時關閉虛擬環境,運行命令
禁用。你會知道你的虛擬環境時禁用虛擬環境的名字不再顯示在括號之前您的終端提示符。
步驟2:更新您的Python代碼建立調試環境
建立一個上下文磚之間的連接和調試您的集群,您的Python代碼必須初始化DatabricksSession通過調用類DatabricksSession.builder.getOrCreate ()。
請注意,您不需要指定設置如工作區的實例名,一個訪問令牌,或者您的集群的ID和端口號當你初始化DatabricksSession類。磚連接得到的這些信息從配置細節,你已經通過磚提供擴展Visual Studio代碼本文前麵。
額外的初始化信息DatabricksSession類,看磚連接代碼示例。
第三步:使磚連接
擴展開了,工作空間部分配置為您的代碼項目,請執行以下操作:
在Visual Studio代碼狀態欄,點擊紅色磚連接禁用按鈕。
如果集群部分不是已經配置的擴展,出現以下消息:“請附上一個集群使用磚連接。“點擊附加集群並選擇一個集群滿足磚連接的要求。
如果集群部分配置但集群不是兼容磚連接,點擊紅色磚連接禁用按鈕,點擊附加集群,並選擇一個兼容的集群。
如果磚連接的包沒有安裝,出現以下消息:“交互式調試和自動完成你需要的磚連接。你想安裝的環境
< environment-name >“點擊。安裝。在Visual Studio代碼狀態欄,藍色磚連接啟用按鈕出現。
如果紅色的磚連接禁用按鈕仍然出現,點擊它,完成藍色屏幕上的指導磚連接啟用按鈕出現。
藍後磚連接啟用按鈕出現了,您現在可以使用磚連接。
請注意
你不需要配置的擴展同步的目的地節為了代碼項目使用磚連接。
步驟4:運行或調試您的Python代碼
啟用磚連接代碼項目之後,運行或調試您的Python文件或筆記本如下。
運行或調試一個Python (. py)文件:
Python代碼中的項目,打開文件,您想運行或調試。
在Python文件設置任何調試斷點。
文件編輯器的標題欄,單擊下拉箭頭旁邊玩(運行或調試)圖標。然後在下拉列表中,選擇Python調試文件。這個選擇支持分步調試斷點,看表情,調用堆棧,和類似的功能。這個選擇使用磚連接到運行在本地Python代碼,在集群上運行PySpark代碼在偏遠的工作區,並將遠程響應發送回本地調試Visual Studio代碼。
請注意
其他的選擇,它不支持調試,包括:
運行Python文件使用磚連接到運行的文件或筆記本,但是沒有調試支持。這個選擇將文件發送到遠程工作空間,運行文件的Python和PySpark代碼在遠程集群在工作區中,並發送遠程終端響應Visual Studio代碼。
上傳和磚上運行文件發送文件到遠程工作空間,運行文件的Python和PySpark代碼在遠程集群在工作區中,並發送遠程響應< vc >終端。這個選擇不使用磚連接。
磚上運行文件作為工作流發送文件到遠程工作空間,運行文件的Python和PySpark代碼在集群上與自動數據磚相關聯的工作,並將結果發送給一個編輯在Visual Studio代碼。這個選擇不使用磚連接。
的當前文件在交互式窗口運行選項,如果可行的話,嚐試在本地運行的文件在一個特殊的Visual Studio代碼交互編輯器。磚不建議此選項。

運行或調試一個Python Jupyter筆記本(.ipynb):
在您的代碼項目,打開Python Jupyter筆記本你想運行或調試。確保Jupyter筆記本的Python文件格式和擴展
.ipynb。提示
您可以創建一個新的Python Jupyter筆記本通過運行>新建:Jupyter筆記本命令從內部命令麵板。
點擊運行所有細胞所有的細胞都沒有調試運行,執行單元運行一個人相應的細胞沒有調試,或由行運行單個細胞逐行調試、有限的變量值顯示在Jupyter麵板(視圖> > Jupyter打開視圖)。
單個細胞內進行全麵調試,設置斷點,然後單擊調試細胞在菜單中細胞的旁邊運行按鈕。
點擊這些選項之後,你可能會提示安裝失蹤Python Jupyter筆記本包的依賴關係。單擊安裝。
有關更多信息,請參見Jupyter筆記本在VS代碼。
請注意
磚擴展Visual Studio代碼支持額外的實驗為磚筆記本功能連接。看到額外的筆記本與磚連接的特性。
一個集群上運行Python文件
擴展和代碼項目開了,一個磚配置概要文件,集群,回購已經設置,做到以下幾點:
Python代碼中的項目,打開文件,你想在集群上運行。
做下列之一:
在資源管理器視圖(視圖>探險家),右鍵單擊該文件,然後選擇上傳和磚上運行文件從上下文菜單中。
文件編輯器的標題欄,單擊下拉箭頭旁邊玩(運行或調試)圖標。下拉列表中,點擊上傳和磚上運行文件。

文件在集群上運行,並打印輸出調試控製台(視圖>調試控製台)。
運行一個Python文件的工作
擴展和代碼項目開了,一個磚配置概要文件,集群,回購已經設置,做到以下幾點:
在您的代碼項目,打開你想要運行的Python文件工作。
做下列之一:
在資源管理器視圖(視圖>探險家),右鍵單擊該文件,然後選擇磚上運行文件作為工作流從上下文菜單中。
文件編輯器的標題欄,單擊下拉箭頭旁邊玩(運行或調試)圖標。下拉列表中,點擊磚上運行文件作為工作流。


將出現一個新的編輯器標簽,標題磚的工作運行。工作區中的文件運行工作,和任何新編輯器標簽的打印輸出輸出區域。
查看工作運行的信息,點擊任務運行ID鏈接在新磚的工作運行編輯選項卡。工作區中打開和運行工作的細節都顯示在工作區。
運行一個Python筆記本工作
擴展和代碼項目開了,一個磚配置概要文件,集群,回購已經設置,做到以下幾點:
在項目代碼,打開你想要運行的Python筆記本工作。
提示
創建一個Python筆記本文件在Visual Studio代碼,點擊開始文件>新建文件中,選擇Python文件,並保存新的文件
. py文件擴展名。把
. py文件到一個磚筆記本,添加特殊的評論#磚筆記本源文件的開頭,添加特殊的評論#命令- - - - - - - - - - -在每一個細胞。有關更多信息,請參見導入一個文件,並將它轉換成一個筆記本。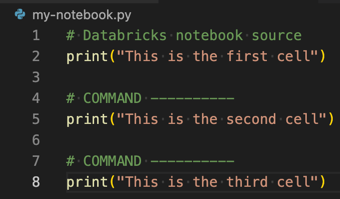
做下列之一:
在資源管理器視圖(視圖>探險家筆記本文件),右鍵單擊,然後選擇磚上運行文件作為工作流從上下文菜單中。
在筆記本上文件編輯器的標題欄,單擊下拉箭頭旁邊玩(運行或調試)圖標。下拉列表中,點擊磚上運行文件作為工作流。

將出現一個新的編輯器標簽,標題磚的工作運行。筆記本運行作為一個工作在工作區中,筆記本和它的輸出顯示在新的編輯器選項卡輸出區域。
查看工作運行的信息,點擊任務運行ID鏈接磚的工作運行編輯選項卡。工作區中打開和運行工作的細節都顯示在工作區。
運行一個R, Scala,或SQL筆記本工作
擴展和代碼項目開了,一個磚配置概要文件,集群,回購已經設置,做到以下幾點:
在您的代碼項目,打開R, Scala或SQL筆記本你想運行的工作。
提示
創建一個R, Scala或SQL筆記本文件在Visual Studio代碼,點擊開始文件>新建文件中,選擇Python文件,並保存新的文件
。r,. scala,或. sql文件擴展名。把
。r,. scala,或. sql文件到一個磚筆記本,添加特殊的評論磚筆記本源一開始的文件並添加特殊的評論命令- - - - - - - - - - -在每一個細胞。一定要使用正確的評論標記為每個語言(#為R,/ /Scala,- - -對於SQL)。有關更多信息,請參見導入一個文件,並將它轉換成一個筆記本。這類似於Python筆記本的模式:
在運行和調試視圖(視圖>運行),選擇在磚上運行工作流從下拉列表中,然後單擊綠色箭頭(玩開始調試)圖標。

請注意
如果在磚上運行工作流不可用,看到了嗎創建一個自定義的運行配置。

將出現一個新的編輯器標簽,標題磚的工作運行。筆記本電腦作為工作在工作空間中運行。筆記本和它的輸出顯示在新的編輯器選項卡輸出區域。
查看工作運行的信息,點擊任務運行ID鏈接磚的工作運行編輯選項卡。工作區中打開和運行工作的細節都顯示在工作區。
先進的任務
您可以使用Visual Studio的磚擴展代碼執行以下先進的任務。
運行測試與pytest
您可以運行pytest在本地代碼,不需要連接到一個集群在一個偏遠的磚工作區。例如,您可能使用pytest測試你的函數接受和返回PySpark DataFrames在本地內存中。開始使用pytest並在本地運行它,明白了開始在pytest文檔。
運行pytest代碼在一個偏遠的磚工作區,在Visual Studio代碼做以下項目:
步驟1:創建測試
添加一個Python與下麵的代碼文件,其中包含您的測試運行。這個例子假設這個文件命名spark_test.py並在Visual Studio代碼項目的根源。這個文件包含一個pytest夾具,這使得集群的SparkSession(集群)上的入口點火花功能測試。這個文件包含一個單獨的測試,檢查表中指定的細胞是否包含指定值。您可以添加您自己的測試,以根據需要這個文件。
從pyspark.sql進口SparkSession進口pytest@pytest。夾具def火花()- >SparkSession:#創建一個SparkSession(入口點引發功能)#集群在偏遠的磚工作區。單元測試不#默認訪問這個SparkSession。返回SparkSession。構建器。getOrCreate()#現在添加你的單元測試。#為例,這是一個必須在運行單元測試#集群在偏遠的磚工作區。#這個例子判斷指定的細胞#指定表包含指定值。例如,#第三列在第一行應該包含“理想”這個詞:## + - - - - - - - - - - - - - - - - - - - + + - - - - - - - - - - - - - - - - - - - + - - - - - - - - - - - - - - + - - - - - - - - - - - - - + - - - - - - - - - - - - - +# | _c0 |克拉削減| | | | |清晰深度色表x y z | | | | |價格# + - - - - - - - - - - - - - - - - - - - + + - - - - - - - - - - - - - - - - - - - + - - - - - - - - - - - - - - + - - - - - - - - - - - - - + - - - - - - - - - - - - - +理想# | 1 | 0.23 | | | E SI2 55 | 326 | 3.95 | 61.5 | | 3。98 | 2.43 |# + - - - - - - - - - - - - - - - - - - - + + - - - - - - - - - - - - - - - - - - - + - - - - - - - - - - - - - - + - - - - - - - - - - - - - + - - - - - - - - - - - - - +#……#deftest_spark(火花):火花。sql(使用默認的)數據=火花。sql(“SELECT * FROM鑽石”)斷言數據。收集()(0][2]= =“理想”
步驟2:創建pytest跑步者
添加一個Python文件,下麵的代碼,指示pytest從上一步運行你的測試。這個例子假定文件命名pytest_databricks.py並在Visual Studio代碼項目的根源。
進口pytest進口操作係統進口sys#運行所有測試遠程數據磚的連接存儲庫工作區。#默認情況下,pytest搜索通過與文件名結尾的所有文件#“_t。py”測試。在這些文件中,pytest運行每個函數#用一個函數名開始“test_”。#得到這個文件的路徑存儲庫工作區。repo_root=操作係統。路徑。目錄名(操作係統。路徑。realpath(__file__))#切換到存儲庫的根目錄。操作係統。是指(repo_root)#跳過.pyc文件寫入的字節碼緩存集群。sys。dont_write_bytecode=真正的#現在從存儲庫的根目錄,運行pytest使用#參數所提供的定製運行配置# Visual Studio代碼項目。在這種情況下,定製的運行#配置JSON必須包含這些獨特的“程序”#“參數”對象:##……# {#……#“程序”:“$ {workspaceFolder} /道路/ /這個/文件/ /工作空間”,#“參數”:(“/道路/ / _test.py-files”)#}#……#retcode=pytest。主要(sys。argv(1:])
步驟3:創建一個自定義的運行配置
指導pytest運行你的測試,你必須創建一個自定義的運行配置。使用現有的磚基於集群的運行配置來創建您自己的自定義運行配置,如下:
在主菜單中,點擊運行>添加配置。
在命令麵板中,選擇磚。
Visual Studio代碼添加一個
.vscode / launch.json文件到您的項目,如果這個文件不存在。改變起動運行配置如下所示,然後保存文件:
改變這一運行配置的名字
運行在磚為這個配置一些獨特的顯示名稱,在本例中單位測試(在磚)。改變
程序從$ {file}道路項目中包含測試運行器,在這個例子中$ {workspaceFolder} / pytest_databricks.py。改變
arg遊戲從[]道路項目中包含的文件和你的測試,在這個例子中(“。”)。
你的
launch.json文件應該是這樣的:{/ /使用智能感知了解可能的屬性。/ /鼠標查看現有屬性的描述。/ /獲取更多信息,請訪問:https://go.microsoft.com/fwlink/?linkid=830387“版本”:“0.2.0”,“配置”:({“類型”:“磚”,“請求”:“啟動”,“名稱”:“單元測試”(磚),“程序”:“$ {workspaceFolder} / pytest_databricks.py”,“參數”:(“。”),“env”:{}}]}
步驟4:運行測試
確保pytest已經安裝在集群上。例如,集群的設置頁麵打開在你磚工作區,做到以下幾點:
在庫選項卡,如果pytest是可見的,那麼
pytest已經安裝。如果pytest是不可見的,點擊安裝新。為庫源,點擊PyPI。
為包,輸入
pytest。點擊安裝。
等到狀態改變從等待來安裝。
運行測試,從Visual Studio代碼做以下項目:
在主菜單中,點擊視圖>運行。
在運行和調試列表中,點擊單元測試(磚),如果尚未選中。
單擊綠色箭頭(開始調試)圖標。
的pytest結果顯示在調試控製台(視圖>調試控製台在主菜單)。例如,這些結果表明,發現了至少一個測試spark_test.py文件和一個點(。)意味著一個測試被發現和傳遞。(一個失敗的測試將顯示一個F。)
<日期>、<時間>——創建集群上執行上下文< cluster-id >…<日期>、<時間>——同步代碼/回購/ < someone@example.com > / < your-repository-name >…<日期>、<時間> -運行/ pytest_databricks。py……= = = = = = = = = = = = = = = = = = = = = = = = = = = = =測試會話開始= = = = = = = = = Beplay体育安卓版本= = = = = = = = = = = = = = = = = = = = =平台linux——Python <版本>,pytest——<版本> pluggy - <版本> rootdir: /工作區/回購/ < someone@example.com > / < your-repository-name > spark_test收集1項。py。(100%)= = = = = = = = = = = = = = = = = = = = = = = = = = = = = = 1通過3.25 s = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = <日期>、<時間>,完成(花了10818 ms)
額外的筆記本與磚連接的特性
磚擴展Visual Studio代碼支持以下特性的磚筆記本運行的擴展通過其磚連接集成。要啟用這些功能,打開notebooks.dbconnect功能實驗:選擇在Visual Studio代碼。看到設置和運行或調試與磚連接的Python代碼。
以下筆記本啟用了全局變量:
火花,代表的一個實例databricks.connect.DatabricksSession預配置實例化DatabricksSession通過磚的身份驗證憑證的擴展。udf,預配置作為一個別名pyspark.sql.functions.udf,這是一個Python udf的別名。sql,預配置作為一個別名spark.sql。火花如前所述,代表了一個預配置的實例databricks.connect.DatabricksSession。dbutils,預配置磚實用程序的一個實例,這是進口的databricks-sdk並通過實例化磚的身份驗證憑證的擴展。請注意
隻有一個子集的磚與磚連接工具支持的筆記本電腦。
顯示,預配置的一個別名Jupyter內置命令IPython.display.display。displayHTML,預配置作為一個別名dbruntime.display.displayHTML,這是一個別名display.HTML從ipython。
以下筆記本魔法是可用的:
% fs,這是一樣的dbutils.fs調用。% sh運行一個命令使用細胞魔法% %腳本在本地機器上。這並不是遠程數據磚的工作區中運行該命令。%醫學博士和% md-sandbox細胞,魔法% %減價。%的sql,spark.sql。%皮普,皮普安裝在本地機器上。這並不運行皮普安裝在偏遠的磚工作區。
額外的功能包括:
火花DataFrames轉換為熊貓DataFrames, Jupyter表中顯示的格式。
限製包括:
筆記本的魔法
運行%,r %,% scala如果叫不支持和顯示一個錯誤。筆記本電腦的魔力
%的sql不支持一些DML命令,如顯示表。
使用環境變量定義文件
Visual Studio代碼支持環境變量定義為Python項目文件。這使您能夠創建一個文件的擴展名.env在開發機器上的某個地方,和Visual Studio代碼將應用在這個環境變量.env文件在運行時。有關更多信息,請參見環境變量定義文件在Visual Studio代碼文檔。
有磚擴展Visual Studio使用您的代碼.env文件,設置databricks.python.envFile在你的settings.json文件或Python擴展>磚>:Env文件在設置編輯器的絕對路徑.env文件。
重要的
如果你設置settings.json,做不集python.envFile的絕對路徑.env文件中所描述的Visual Studio代碼文檔,作為Visual Studio的磚擴展的代碼必須覆蓋python.envFile其內部使用。一定要隻設置databricks.python.envFile代替。
創建一個自定義的運行配置
您可以創建自定義的運行配置在Visual Studio代碼傳遞自定義參數等做一個工作或一個筆記本,或者創建不同的運行設置不同的文件。例如,下麵的自定義配置運行通過——刺激這份工作參數:
{“版本”:“0.2.0”,“配置”:({“類型”:“databricks-workflow”,“請求”:“啟動”,“名稱”:“磚作為工作流的運行”,“程序”:" $ {file} ",“參數”:{},“參數”:(”——刺激”),“preLaunchTask”:“磚:同步”}]}
要創建一個自定義的運行配置,單擊運行>添加配置從主菜單中在Visual Studio代碼。然後選擇磚基於集群的配置或運行磚:工作流就業型運行配置。
通過使用自定義運行配置,您還可以通過命令行參數和運行您的代碼隻是按F5。有關更多信息,請參見啟動配置在Visual Studio代碼文檔。
卸載擴展
您可以卸載的磚擴展Visual Studio代碼如果需要,如下:
在Visual Studio代碼,點擊視圖>擴展從主菜單。
在擴展的列表,選擇Visual Studio代碼的磚條目。
點擊卸載。
點擊需要重新加載,或重新啟動Visual Studio代碼。
故障排除
通過一個代理錯誤時同步
問題:當你試圖運行的磚擴展Visual Studio代碼同步您的本地代碼通過一個代理項目,類似於一條錯誤消息出現後,和同步操作不成功:得到“https:// < workspace-instance > . . / api / 2.0 /預覽/ scim / v2 /我”:EOF。
可能的原因:Visual Studio代碼不知道如何找到代理。
推薦解決方案:重新啟動Visual Studio代碼從你的終端通過運行下麵的命令,然後再次嚐試同步:
envHTTPS_PROXY=< proxy-url >: <口>代碼
在前麵的命令:
取代
< proxy-url >完整的URL到你的代理。取代
<口>使用正確的港口在你的代理。
錯誤:“產生未知的係統錯誤-86”當你試圖同步本地代碼
問題:當你試圖同步本地代碼在一個項目中遠程數據磚工作區,終端表明,同步已經開始但隻會顯示錯誤消息產卵未知的係統錯誤-86年。此外,同步的目的地部分的配置窗格中仍處於等待狀態。
可能的原因:錯了版本的磚擴展Visual Studio代碼為您的開發機器的操作係統安裝。
發送日誌數據磚使用
如果你有問題同步本地代碼遠程數據磚工作空間,您可以發送使用日誌和磚支持通過以下相關信息:
打開詳細模式為磚由檢查命令行界麵(CLI)磚:詳細模式設置,或設置
databricks.bricks.verboseMode來真正的描述的一樣,設置。還打開日誌通過檢查日誌:啟用設置,或設置
databricks.logs.enabled來真正的描述的一樣,設置。一定要重新啟動Visual Studio代碼後打開日誌記錄。試圖重現你的問題。
從命令麵板(視圖>命令麵板從主菜單中),運行磚:開放完整的日誌命令。
發送
bricks-logs.json和sdk-and-extension-logs.json文件似乎磚的支持。也複製的內容終端(視圖>終端)的問題,並將這些內容發送到磚的支持。
發送錯誤日誌,沒有對代碼同步問題磚支持:
從命令麵板(視圖>命令麵板),運行磚:開放完整的日誌命令。
隻發送
sdk-and-extension-logs.json文件似乎磚的支持。
的輸出視圖(視圖>輸出,磚日誌如果)顯示截短信息日誌:啟用檢查或databricks.logs.enabled被設置為真正的。顯示更多信息,更改以下設置,如中描述設置:
日誌:馬克斯數組長度orgydF4y2Ba
databricks.logs.maxArrayLength日誌:馬克斯字段長度orgydF4y2Ba
databricks.logs.maxFieldLength日誌:截斷深度orgydF4y2Ba
databricks.logs.truncationDepth
命令麵板
磚擴展Visual Studio代碼將以下命令添加到Visual Studio代碼命令麵板。另請參閱命令麵板在Visual Studio代碼文檔。
命令 |
描述 |
|---|---|
|
使智能感知PySpark Visual Studio代碼代碼編輯器,磚公用事業、和相關的全局變量等 |
|
移動焦點的命令麵板創建、選擇或改變磚集群為當前項目使用。看到設置集群。 |
|
|
|
移動焦點的命令麵板創建、選擇或改變磚認證用於當前項目的細節。看到設置身份驗證配置概要文件。 |
|
創建一個新的目的地同步。 |
|
刪除當前項目的參考數據磚集群。 |
|
消除了同步目的地從當前項目的引用。 |
|
移動的焦點磚視圖的集群窗格。 這個命令隻有在出現 |
|
移動的焦點磚視圖的配置窗格。 |
|
移動的焦點磚視圖的工作空間瀏覽器窗格。 這個命令隻有在出現 |
|
重置磚視圖顯示配置數據磚和顯示快速入門按鈕的配置窗格。在當前項目的任何內容 |
|
打開數據磚配置概要文件,默認位置,為當前項目。看到設置身份驗證配置概要文件。 |
|
打開文件夾,其中包含應用程序日誌文件的磚擴展Visual Studio代碼寫入您的開發機器上。 |
|
刷新工作空間瀏覽器窗格中磚視圖。 |
|
在集群上運行Python文件。 |
|
在編輯器中顯示了快速入門文件。 |
|
如果它已經停止啟動集群。 |
|
開始同步當前項目的代碼磚工作區。這個命令執行增量同步。 |
|
開始同步當前項目的代碼磚工作區。這個命令執行一個完整的同步,即使增量同步是可能的。 |
|
如果它已經停止集群運行。 |
|
停止同步當前項目的代碼磚工作區。 |
|
運行Python文件或一個筆記本作為自動化磚工作在工作區中。 |
設置
Visual Studio的磚擴展Visual Studio代碼代碼添加以下設置。另請參閱設置編輯器和settings.json在Visual Studio代碼文檔。
設置編輯器(擴展>磚) |
settings.json |
描述 |
|---|---|---|
Cli:詳細模式 |
|
檢查或設置為 檢查或設置為 |
集群:隻顯示訪問集群 |
|
檢查或設置為 |
實驗:選擇 |
|
啟用或禁用實驗特性的擴展。可用的功能包括:
|
日誌:啟用 |
|
檢查或設置為 |
日誌:馬克斯數組長度 |
|
對數組字段顯示的條目的最大數量。默認值是 |
日誌:馬克斯字段長度 |
|
每個字段的最大長度顯示在日誌輸出麵板。默認值是 |
日誌:截斷深度 |
|
沒有截斷日誌顯示的最大深度。默認值是 |
覆蓋磚配置文件 |
|
一個替代的位置 |
Python: Env文件 |
|
您的自定義Python的絕對路徑環境變量定義( |
同步:目的地類型 |
|
在工作區中是否使用一個目錄( 設置這個 刷新你的窗口任何改變生效。 |
常見問題(faq)
你有支持或支持的時間表,有下列功能?
其他語言,比如Scala或SQL
三角洲生活表
磚SQL的倉庫
其他的ide,比如PyCharm
附加的庫
完整的CI / CD集成
磚是意識到這些請求和優先工作,使簡單的場景為當地發展和遠程運行的代碼。請轉發其他請求和場景你磚的代表。磚將輸入合並到未來的規劃。
起程拓殖提供者如何磚與磚擴展Visual Studio代碼?
磚繼續推薦磚起程拓殖的提供者管理你的CI / CD管道以可預測的方式。請讓你的磚代表知道如何使用IDE來管理你的將來部署。磚將輸入合並到未來的規劃。
如何由磚實驗室與dbx磚擴展Visual Studio代碼?
的主要特征dbx的磚實驗室包括:
項目腳手架。
有限的地方發展
dbx執行命令。CI / CD磚的工作。
的磚擴展Visual Studio代碼支持地方發展和遠程運行Python代碼文件數據磚集群,在磚和遠程運行Python代碼文件和筆記本工作。dbx可以繼續用於項目腳手架和CI / CD磚的工作。
如果我已經有一個現有的磚我創建的配置概要文件通過磚CLI ?
您可以選擇您的現有配置概要文件配置的磚擴展Visual Studio時代碼。擴展和代碼項目打開時,執行以下操作:
在配置窗格中,點擊齒輪(配置工作空間)圖標。
輸入您的工作區實例URL例如,
https://dbc-a1b2345c-d6e7.cloud.m.eheci.com。在命令麵板,選擇您的現有配置概要文件。
我需要什麼權限磚工作區使用磚擴展Visual Studio代碼?
你必須有執行權限磚集群運行代碼,以及權限來創建一個存儲庫在磚回購。
我可以用的磚擴展Visual Studio代碼與代理?
是的。看到推薦的解決方案通過一個代理錯誤時同步。
我可以使用Visual Studio的磚擴展代碼與現有與遠程Git存儲庫存儲提供商?
不。的磚擴展Visual Studio代碼隻能創建存儲庫。