訪問S3與SCIM我憑證透傳(遺留)
預覽
這個特性是在公共預覽。
請注意
我憑證透傳是一個遺留數據治理模型。磚建議你升級到統一的目錄。統一目錄簡化了數據的安全性和治理提供一個中心位置管理和審計數據訪問跨多個工作空間在您的帳戶。看到聯合目錄是什麼?。
我憑證透傳允許您進行身份驗證自動從磚S3 bucket集群使用你的身份登錄到磚。當你使我憑證透傳您的集群,命令你運行在集群可以讀取和寫入數據在S3中使用您的身份。我憑證透傳有兩個關鍵好處在確保訪問S3 bucket使用實例配置文件:
我憑證透傳允許多個用戶提供不同的數據訪問策略共享一個磚集群在S3中訪問數據時總是保持數據安全。實例配置文件可以隻有一個相關聯我的角色。這需要磚集群上的所有用戶共享這個角色和數據訪問政策的作用。
我憑據透傳將用戶與身份。這反過來使S3對象通過CloudTrail日誌。所有S3訪問都是直接綁定到用戶通過攻擊CloudTrail日誌中。
建立一個元實例配置文件
為了使用我憑證透傳,你必須首先設置至少一個元實例配置文件假設我的角色分配給用戶。
一個我的角色是一個AWS身份與政策,確定在AWS身份可以和不能做什麼。一個實例配置文件是一個容器,一個我的角色,您可以使用通過角色信息實例啟動時一個EC2實例。實例配置文件允許您從磚的集群,而無需訪問數據嵌入AWS鑰匙在筆記本電腦。
而集群實例配置文件進行配置角色很簡單,配置文件隻能與一個實例一個我的角色。這需要磚集群上的所有用戶共享這個角色和數據訪問政策的作用。然而,角色可以用來承擔其他我自己角色或直接訪問數據。使用憑證為一個角色承擔不同的角色角色鏈接。
憑據透傳允許管理員把我的角色實例配置文件是使用和角色用戶使用訪問數據。在磚,我們調用實例的作用元我的角色和數據訪問的角色數據我角色。類似於實例配置文件,元實例配置文件元我的角色是一個容器。

用戶被授予數據訪問我的角色使用SCIM API。如果你與你的身份提供者角色映射,然後這些角色將同步到磚SCIM API。當你使用一個集群憑據透傳和元實例配置文件,你可以假設隻有我角色,您可以訪問的數據。這允許多個用戶使用不同的數據訪問政策共享一個磚集群,同時保持數據安全。
本節描述如何設置所需的元實例配置文件啟用我憑證透傳。
步驟1:為我配置角色憑據透傳
在本節中:
創建一個數據我的角色
使用現有的數據我角色或選擇S3訪問配置實例配置文件創建一個數據我角色可以訪問S3 bucket。
配置一個元我的角色
配置您的元角色承擔數據我的角色。
在AWS控製台,去我服務。
單擊角色在側邊欄選項卡。
點擊創建角色。
下選擇類型的信任的實體中,選擇AWS服務。
單擊EC2服務。
點擊下一個權限。
點擊創建政策。一個新窗口打開。
單擊JSON選項卡。
複製以下政策和設置
<帳戶id >你的AWS帳戶ID和< data-iam-role >您的數據我角色的名稱從前麵的部分。{“版本”:“2012-10-17”,“聲明”:({“席德”:“AssumeDataRoles”,“效應”:“允許”,“行動”:“sts: AssumeRole”,“資源”:(“攻擊:aws:我::<帳戶id >: / < data-iam-role >”角色]}]}
點擊審查政策。
在Name字段中,輸入名稱,然後單擊政策創建政策。
返回角色窗口和刷新它。
搜索策略名稱和名稱旁邊的複選框選擇策略。
點擊下一個標簽和下一個評論。
角色名稱的文件,為元輸入一個名字我的角色。
點擊創建角色。
在總結作用,複製實例配置文件是。
配置數據角色信任元我的角色
使元角色能夠承擔數據我的角色,你所信任的元作用作用的數據。
在AWS控製台,去我服務。
單擊角色在側邊欄選項卡。
發現前一步驟中創建的數據作用並單擊它去角色細節頁麵。
單擊信任關係如果沒有設置選項卡,並添加以下語句:
{“版本”:“2012-10-17”,“聲明”:({“效應”:“允許”,“校長”:{“AWS”:“攻擊:aws:我::<帳戶id >: / < meta-iam-role >”角色},“行動”:“sts: AssumeRole”}]}
步驟2:配置元實例在磚
本節描述如何配置一個元實例配置文件數據磚。
確定我的角色用於磚部署
去賬戶控製台。
單擊工作區圖標。
點擊你的名字工作區。
注意角色名稱的盡頭是憑證的關鍵部分,在下圖'testco-role”。

我修改政策作用用於磚部署
在AWS控製台,去我服務。
單擊角色在側邊欄選項卡。
編輯您前麵部分中提到的角色。
單擊附加到角色的策略。
修改政策允許EC2實例火花集群內磚使用元實例中創建配置文件配置一個元我的角色。例如,看到的步驟3:添加一個S3 EC2政策我的角色。
點擊審查政策和保存更改。


步驟3:附上我磚用戶角色權限
有兩種方法可以保持用戶我角色的映射:
使用下麵的圖表來幫助你決定哪些映射方法更適合您的工作區:
要求 |
SCIM |
身份提供商 |
|---|---|---|
單點登錄到磚 |
沒有 |
是的 |
配置AWS身份提供商 |
沒有 |
是的 |
配置元實例配置文件 |
是的 |
是的 |
磚的工作空間管理 |
是的 |
是的 |
AWS管理 |
是的 |
是的 |
身份提供商管理 |
沒有 |
是的 |
當你開始一個集群元實例配置文件,集群將通過你的身份,隻以為我角色,您可以訪問的數據。管理員必須授予用戶權限數據使用我的角色SCIM API方法來設置權限的角色。
請注意
如果你是映射在你的國內流離失所者的角色,這些角色將覆蓋任何角色映射在SCIM和你不應該直接將用戶映射到角色。看到步驟6:可選配置映射從SAML SCIM磚同步的作用。
你也可以附加一個實例用戶或組的概要文件磚起程拓殖的提供者和databricks_user_role或databricks_group_instance_profile。
發射一個我憑證透傳集群
進程啟動與憑證透傳的集群根據不同集群模式。
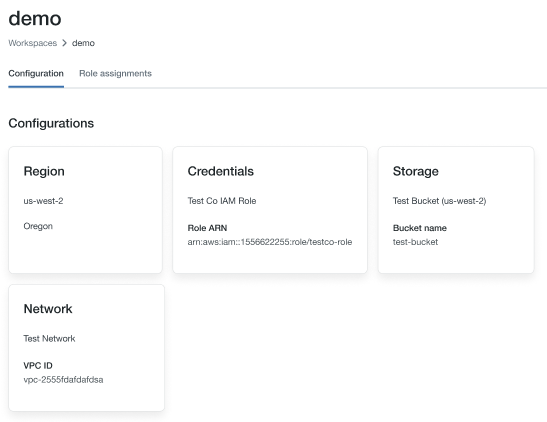
高並發集群使憑證透傳
高並發的集群可以由多個用戶共享。他們隻支持Python和SQL透傳。
選擇一個磚運行時版本6.1或更高版本。
下高級選項中,選擇為用戶級啟用憑據透傳數據訪問和隻允許Python和SQL命令。

單擊實例選項卡。在實例配置文件下拉,選擇元實例中創建配置文件元實例配置文件添加到磚。

使我憑證透傳為一個標準的集群
標準集群憑據支持透傳,僅限於單個用戶。標準集群支持Python、SQL、Scala和r .上麵的磚運行時10.4 LTS和sparklyr還支持。
您必須指定一個用戶在創建集群,但集群可以由用戶編輯可以管理在任何時間來替換原來的用戶權限。
重要的
用戶分配給集群必須至少可以連接到允許集群為了在集群上運行命令。工作區管理員和集群的創造者可以管理權限,但不能在集群上運行命令,除非它們指定集群用戶。
選擇一個磚運行時版本6.1或更高版本。
下高級選項中,選擇為用戶級啟用憑據透傳數據訪問。
選擇的用戶名單用戶訪問下拉。
單擊實例選項卡。在實例配置文件下拉,選擇元實例中創建配置文件元實例配置文件添加到磚。

使用我訪問S3憑據透傳
您可以使用證書訪問S3透傳通過假設一個角色和訪問S3直接或通過使用山S3 bucket中的角色和訪問數據通過掛載。
使用憑據讀取和寫入S3數據透傳
讀取和寫入數據從S3 /:
dbutils。憑證。assumeRole(“攻擊:aws:我::xxxxxxxx:角色/ < data-iam-role >”)火花。讀。格式(“csv”)。負載(“s3a: / / prod-foobar / sampledata.csv”)火花。範圍(1000年)。寫。模式(“覆蓋”)。保存(“s3a: / / prod-foobar / sampledata.parquet”)
dbutils.credentials.assumeRole(“攻擊:aws:我::xxxxxxxx:角色/ < data-iam-role >”)# SparkR圖書館(SparkR)sparkR.session()read.df(“s3a: / / prod-foobar / sampledata.csv”,源=“csv”)write.df(as.DataFrame(data.frame(1:1000年)),路徑=“s3a: / / prod-foobar / sampledata.parquet”,源=“鋪”,模式=“覆蓋”)# sparklyr圖書館(sparklyr)sc< -spark_connect(方法=“磚”)sc% > %spark_read_csv(“s3a: / / prod-foobar / sampledata.csv”)sc% > %sdf_len(1000年)% > %spark_write_parquet(“s3a: / / prod-foobar / sampledata.parquet”,模式=“覆蓋”)
使用dbutils與一個角色:
dbutils。憑證。assumeRole(“攻擊:aws:我::xxxxxxxx:角色/ < data-iam-role >”)dbutils。fs。ls(“s3a: / / bucketA /”)
dbutils.credentials.assumeRole(“攻擊:aws:我::xxxxxxxx:角色/ < data-iam-role >”)dbutils.fs.ls(“s3a: / / bucketA /”)
為其他dbutils.credentials方法,請參閱證書效用(dbutils.credentials)。
掛載一個S3 bucket DBFS使用我憑證透傳
對於更高級的場景不同的桶或前綴需要不同的角色,更方便使用磚桶安裝指定角色的使用當訪問一個特定的桶的道路。
當你使用集群使我證書掛載數據透傳,任何讀或寫掛載點使用您的憑據進行身份驗證的掛載點。這個掛載點會對其他用戶可見,但隻會讀和寫訪問的用戶都是那些:
通過我訪問底層S3存儲賬戶數據角色
使用一個集群支持我憑證透傳
dbutils。fs。山(“s3a: / / < s3 bucket > /數據/機密”,“/ mnt /機密數據”,extra_configs={“fs.s3a.credentialsType”:“自定義”,“fs.s3a.credentialsType.customClass”:“com.databricks.backend.daemon.driver.aws.AwsCredentialContextTokenProvider”,“fs.s3a.stsAssumeRole.arn”:“攻擊:aws:我::xxxxxxxx:角色/ < confidential-data-role >”})
訪問S3數據使用我憑證透傳的工作
使用證書訪問S3數據透傳的工作,根據配置集群發射一個我憑證透傳集群當您選擇一個新的或現有的集群。

集群隻承擔工作的所有者的角色已經被授予許可假設,因此隻能訪問S3數據角色權限來訪問。
從一個JDBC訪問S3數據或ODBC客戶端使用我憑據透傳
使用我訪問S3數據使用JDBC、ODBC客戶端憑據透傳,根據配置集群發射一個我憑證透傳集群在您的客戶端連接到這個集群。集群隻承擔的角色用戶連接到它已經被授予訪問權限,因此隻能訪問S3數據,用戶有權限訪問。
指定一個角色在您的SQL查詢,執行以下操作:
集火花。磚。憑證。假定。角色=在攻擊:aws:我::XXXX:角色/ <數據- - - - - -我- - - - - -角色>;——訪問桶的<我的角色>有權限訪問選擇數(*)從csv。”s3:/ /我的- - - - - -桶/測試。csv”;
已知的限製
以下我憑證透傳功能不支持:
% fs(使用相當於dbutils.fs命令相反)。下列方法SparkContext (
sc)和SparkSession (火花)對象:棄用的方法。
方法如
addFile ()和addJar ()允許非管理用戶調用Scala代碼。S3以外的任何方法訪問一個文件係統。
老Hadoop api (
hadoopFile ()和hadoopRDD ())。流api,因為通過證書將過期而流仍在運行。
DBFS坐騎(
/ dbfs)隻有在磚運行時7.3 LTS及以上。掛載點與憑證透傳配置不支持通過這條路。整個集群範圍的圖書館需要集群實例配置文件下載的權限。隻有庫DBFS路徑支持。