

レ郵箱クハウスを統合
デタ·ai
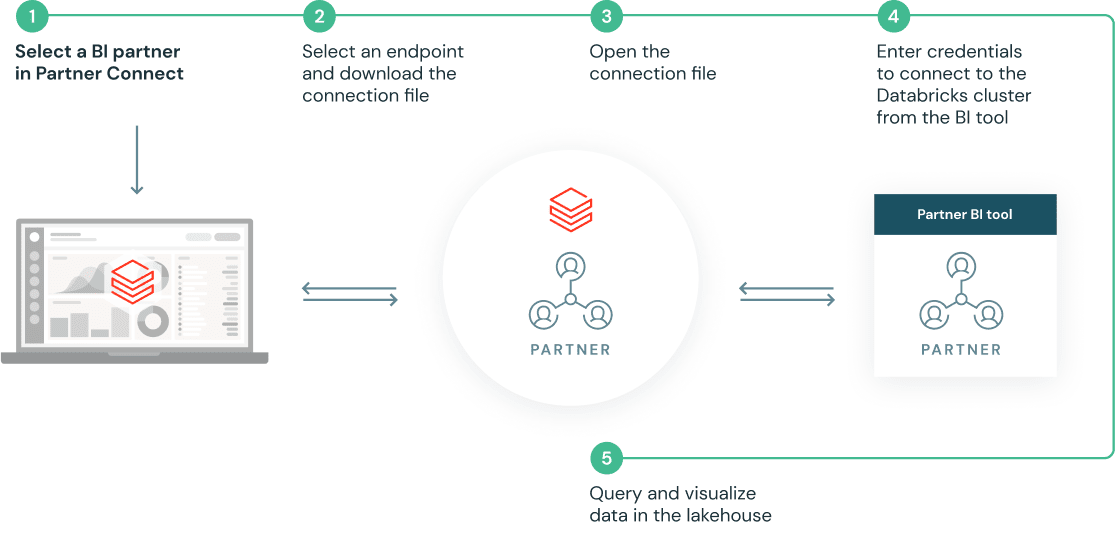

數據庫認定のデタ·AIソリュションで新たなユスケスを構築
事前構築された統合で設定を容易に

數據庫のパトナとして
磚のパートナーになることで,分析結果や知見をより迅速にお客様に提供できるユニークなポジショニングが可能になります。磚の開発者およびパートナー向けのリソースと、クラウドベースのオープンなプラットフォームを活用して、共にビジネスを発展させましょう!
パトナになる“合作夥伴連接での連攜は,磚との長期にわたるパートナーシップを基盤とするものです。合作夥伴連接によって,多くのユーザーによりよいエクスペリエンスを提供できるようになりました。Fivetranを既に利用するユーザーも、Partner Connect を介して初めて利用するユーザーも、數百種のデータソースをレイクハウスに容易に接続することで、データからの知見の抽出、分析ユースケースの探索を加速させ、レイクハウスのデータの価値を最大化できます。」
Fivetran CEOジョジ·フレザ(喬治·弗雷澤)氏
![]()
デモ



デモ動畫のトランスクリプト
Fivetranのデモ
磚からFivetranに接続することで,データの取得やメンテナンスがシンプルになります。Fivetranは、180 以上のデータソースに対応するフルマネージドコネクタを提供しており、データソースの変更データキャプチャもサポートしています。
トランスクリプト→
用戶現在可以在夥伴連接中點擊幾下就可以發現並連接到Fivetran
在合作夥伴連接中點擊進入Fivetran啟動兩個產品之間的自動化工作流:
- Databricks自動提供一個SQL端點和相關的憑證為Fivetran進行交互,與最佳實踐烘焙到端點的配置中。
Databricks通過安全API自動將用戶身份和SQL端點配置傳遞給Fivetran
然後我們會被重定向到Fivetran的產品,要麼注冊Fivetran試用版,要麼登錄Fivetran(如果我們是現有用戶)。Fivetran會自動設置一個試用賬號。
Fivetran識別這是一個來自Databricks合作夥伴連接的用戶,並自動創建一個Databricks目的地,該目的地配置為通過由合作夥伴連接自動配置的SQL端點輸入Delta(通過暫停視頻&放大或突出顯示左上角的“Databricks合作夥伴- demo_cloud”圖標來強調已設置的自動Databricks目的地,這將是有幫助的)
Databricks Delta目的地已經設置好,用戶現在可以選擇他們想要從哪個源中攝取——我們將使用Salesforce作為源(注意用戶可以自由選擇Fivetran支持的數百個源中的任何一個)。用戶驗證到Salesforce源,選擇他們想要攝取到Databricks Delta的Salesforce對象(在本例中是account & Contact對象),並啟動初始同步
通過點擊日誌,我們可以看到Fivetran正在使用api從Salesforce讀取數據,然後通過自動建立的SQL端點將數據輸入Databricks Delta
從Salesforce到Databricks Delta的同步頻率也可以從Fivetran配置
如果我們點擊Destination,我們可以看到SQL端點配置的詳細信息,這是通過Databricks Partner Connect進入Fivetran後自動創建的結果——這種自動化為用戶節省了幾十個手動步驟和複製/粘貼配置,如果用戶手動設置連接,則必須進行這些操作。它還可以防止用戶犯任何無意的配置錯誤,並避免花費時間調試這些錯誤
回到Databricks UI,我們可以看到Partner Connect為Fivetran自動創建的SQL端點。
現在,Salesforce數據通過這個SQL端點從Fivetran無縫地流入Databricks Delta,我們可以在Databricks data Explorer中查看輸入的Delta表
我們現在可以通過SQL查詢這些Salesforce表,並分析從Fivetran流入的數據,用於下遊BI分析,並與Lakehouse中的其他數據集混合
裏弗裏のデモ
データの取り込みから変換,供給まで,三角洲湖を活用したデータ処理の全工程がシンプルになり,組織全體でのデータ共有を促進できます。150年以上のデータソースに対応するコネクタが事前構築されており,変更データキャプチャもサポートされています。
トランスクリプト→
用戶現在隻需在“夥伴連接”中點擊幾下,就可以發現並連接到Rivery
在Partner Connect中單擊進入Rivery,啟動兩個產品之間的自動化工作流,其中:
Databricks自動提供一個SQL端點和相關的憑證供Rivery交互,並將最佳實踐烘焙到端點的配置中。
Databricks通過安全API自動將用戶身份和SQL端點配置傳遞給Rivery
然後,我們被重定向到Rivery的產品控製台,要麼注冊Rivery試用版,要麼登錄Rivery(如果我們是現有用戶)。rivere會自動建立一個試用賬戶。
現在,我們準備利用Rivery的原生數據源連接器將數據加載到Delta Lake中。
Rivery識別出這是來自Databricks合作夥伴連接的用戶,並自動創建Databricks目的地,該目的地配置為通過由合作夥伴連接自動配置的SQL端點攝取到Delta
現在,轉到連接。它包括數據源和目標之間的連接。我們有一個目標連接,就是Databricks SQL。
Databricks Delta目的地已經設置好了,用戶現在可以選擇他們想從哪個數據源中攝取數據——我們將使用Salesforce CRM作為數據源(注意用戶可以自由選擇Rivery支持的150多個預構建數據源連接器)。用戶驗證到Salesforce CRM源,通過測試後保存連接。它顯示在連接列表中。
我們點擊“Create New River”並選擇“Source to Target”以開始數據攝取。
-選擇Salesforce CRM作為我們的數據源。它自動填充我們前麵設置的Salesforce連接。
-對於輸入配置,您可以選擇同時加載多個表或隻從Salesforce加載一個表。在這個演示中,我們隻選擇一個表,即“Account”表。保存它。
-在“目標”上。對於已設置的Databricks Delta目的地的輸入,用戶可以在Databricks端輸入一個現有的數據庫名稱,也可以創建一個新數據庫。
我們輸入自己的數據庫名稱並添加表前綴。並選擇“覆蓋”作為默認攝入模式。
—保存並單擊“Run”按鈕以啟動輸入工作流。
一旦攝入完成,我們就可以返回Databricks UI,在Databricks SQL Data Explorer中查看攝入的Delta表
我們可以看到這個表的模式、樣本數據以及其他詳細信息。容易和簡單。
我們現在可以通過SQL查詢這些Salesforce表,並在數據從riververy流入時對其進行分析,以便進行下遊BI分析,並與Lakehouse中的其他數據集進行混合
預言のデモ
磚から,ローコードのデータエンジニアリングプラットフォーム預言にワンクリックで容易に接続。ドラッグ&ドロップの視覚的な操作で,Apache火花™,三角洲パイプラインをインタラクティブに構築・デプロイできます。
トランスクリプト→
-從這裏,打開夥伴連接頁麵,選擇預言登錄。
-當創建一個預言帳戶,Databricks將自動建立一個安全連接,直接運行您的管道在您的工作空間。
隨著您的電子郵件憑證被傳遞,您隻需要選擇一個新密碼來注冊預言。
現在您已經登錄了預言,讓我們看看開發和運行您的Spark數據管道有多容易。
讓我們選擇一個“開始”示例管道並打開工作流。
這顯示了一個可視畫布,我們可以在上麵開始構建我們的管道。
讓我們從旋轉一個新的Databricks集群開始。
現在我們的集群已經啟動,隻需單擊一下,就可以轉到Databricks界麵,並在您的工作空間中查看我們的集群。
回到預言UI,讓我們來探索我們的管道。這裏我們正在讀取“客戶”和“訂單”的兩個數據源,並將它們連接在一起……beplay体育app下载地址
....然後通過金額一欄的累加把它們加起來。
稍後,我們將對數據進行排序並將其直接寫入Delta表
有了預言,我們可以直接運行我們的工作流程,隻需要點擊一下就可以看到每一步之後的數據
我們可以看到我們的“客戶”數據,“訂單”數據,數據連接在一起....
.....the aggregated field with the summed amounts…..
..最後,排序後的數據被寫入目標Delta表
現在,讓我們通過清理一些字段來修改我們的管道
為此,我們隻需拖放一個名為“Reformat”.....的新“Gem”
把它連接到我們現有的管道....
....然後選擇列。我們可以添加一個名為“全名”的新列,連接我們的名和姓,並添加一個清理後的金額列,該金額將具有四舍五入的值。
讓我們將此寶石重命名為“Cleanup”。
有了它,我們可以直接創建工作流,並在清理列之後直接查看數據。
正如您所看到的,我們已經很容易地向管道添加了一個Cleanup步驟。
但是預言不僅僅是一個視覺編輯器。在幕後,一切都被保存為高質量的Spark代碼,您可以編輯。
此外,通過直接將代碼存儲到Git中,Prophecy允許您遵循最佳的軟件工程實踐。
在這裏,我們可以看到我們的工作流程和最新的更改直接作為Git上的Scala代碼。

