機器學習在許多文章和博客工作流與數據準備和結束與開始到生產部署模型。但在現實中,這是一個機器學習模型的生命周期的開始。正如他們所說,“改變是生活中唯一不變的”。這也適用於機器學習模型,隨著時間的推移,他們可能會在其準確性或惡化他們的預測能力,通常被稱為模型drift。這個博客討論如何檢測和解決漂移模型。
在機器學習類型的漂移
模型會發生漂移當有某種形式的變化特性數據或目標的依賴關係。我們可以大致將這些變化為以下三類:概念漂移,漂移數據,上遊數據變化。
概念漂移
當目標變量的統計特性的變化,你的概念,試圖預測變化。例如,什麼被認為是欺詐交易的定義可能會改變隨著時間的推移等開發新方法進行非法交易。這種類型的變化將導致概念漂移。
數據漂移
用於訓練模型的特性選擇從輸入數據。當輸入數據統計特性的變化,它將有一個下遊影響模型的質量。例如,數據由於季節性變化,個人喜好的變化,趨勢等將導致輸入數據漂移。
上遊數據變化
有時可以操作數據管道上遊的變化對模型質量產生影響。例如,更改功能編碼,如從華氏攝氏度和切換功能不再生成導致零或缺失值,等等。
方法來檢測和防止漂移模型
考慮到將會有這樣的變化模型部署到生產環境之後,最好的行動就是監視變化和發生變更時采取行動。從一個監控係統有一個反饋回路,刷新模型隨著時間的推移,將有助於避免模型過時。
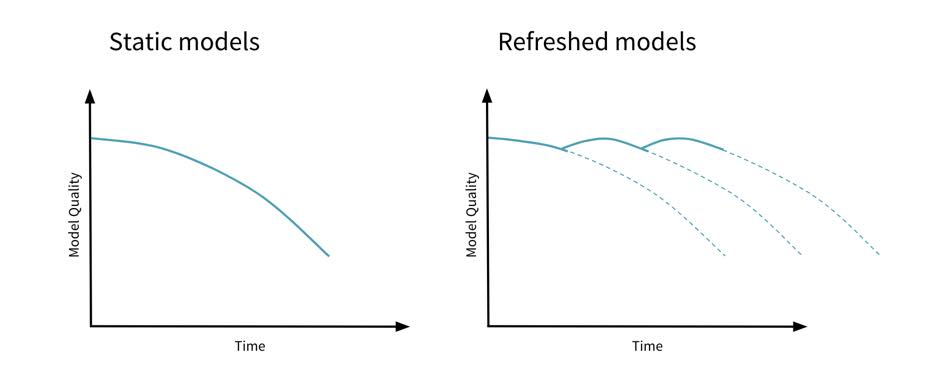
正如我們以上所見,漂移可能從各種來源,因此你應該監視所有這些來源,以確保完全覆蓋。這裏有一些場景,您可以部署監控:<一個href="//m.eheci.com/wp-content/uploads/2019/09/model_drift.png">
訓練數據
請求與預測
管理模式漂移大規模使用磚
檢測數據與三角洲湖漂移
數據質量的第一道防線對模型質量差和漂移模型。三角洲湖有助於確保數據管道是建立高質量和可靠性等提供功能模式執行,數據類型和質量的期望。通常你可以解決數據質量或正確性問題通過更新傳入的數據管道,如修複或進化模式和清理錯誤的標簽,等等。
檢測的概念和模型與磚運行時對ML和MLflow漂移
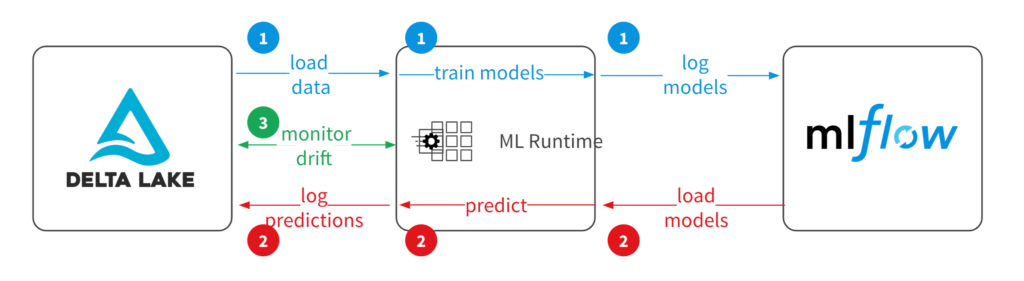
漂移的常見的方法來檢測模型監控預測的質量。理想毫升模型訓練會加載數據來源如三角洲湖表,其次是工程特性,模型優化和選擇使用磚運行時毫升,而所有實驗在MLflow經營和生產模型跟蹤。<一個href="//m.eheci.com/wp-content/uploads/2019/09/model_drift.png">
在部署階段,從MLflow在運行時加載的模型進行預測。您可以登錄模型性能指標以及預測三角洲湖等回到存儲用於下遊係統和性能監控。通過訓練數據、性能指標和預測記錄在一個地方你可以確保準確的監測。<一個href="//m.eheci.com/wp-content/uploads/2019/09/model_drift.png">
在監督訓練,你從訓練數據使用特性和標簽來評估模型的質量。一旦部署了一個模型,你可以日誌和監控兩種類型的數據:性能指標和模型質量度量模型。
- 模型的性能指標參考模型的技術方麵,如推理延遲或內存占用。這些度量模型時很容易被記錄和監控部署在磚上。
- 模型質量指標取決於實際的標簽。一旦登錄標簽,你可以比較預測和實際標簽計算質量指標和檢測漂移預測模型的質量。
示例架構如下所示使用數據從物聯網傳感器(特性)和實際產品質量(標簽)從三角洲湖流源。從這些數據,您創建一個模型來預測產品質量從物聯網傳感器數據。部署生產模型在裝載MLflow得分管道產品質量預測(預測標簽)。
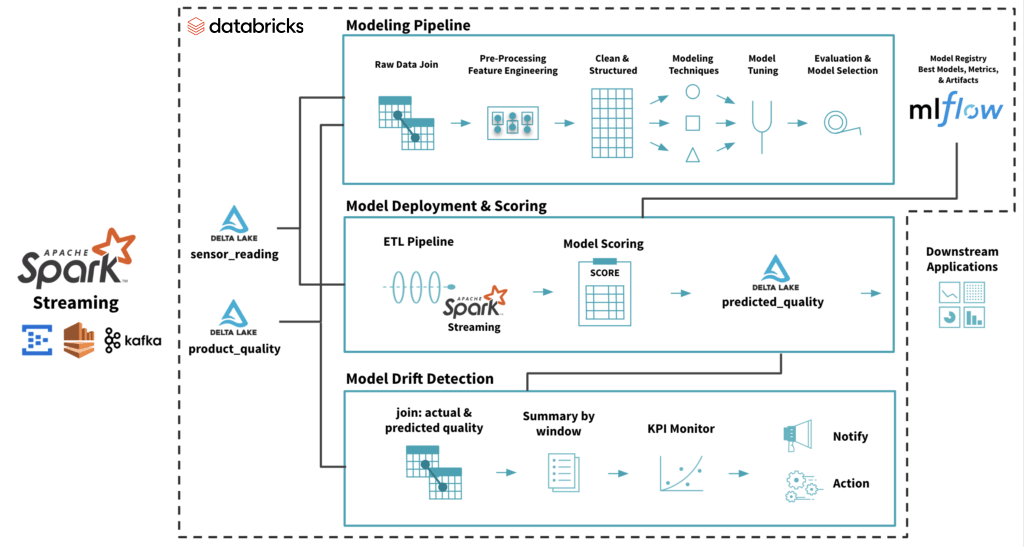
監控漂移,你加入實際產品質量(標簽)和預測(預測標簽)和總結在一個時間窗口趨勢模型質量。這對監測總結KPI模型質量取決於業務需求和多個這樣的KPI可以計算以確保足夠的覆蓋率。看下麵的代碼片段為例。
<b>def</b>track_model_quality (真正的,預計):#加入實際標簽和預測的標簽quality_compare=predicted.join (真正的“pid”)#創建一個列如果預測標簽指示是準確的quality_compare=quality_compare.withColumn (“accurate_prediction”,F.when ((F.col (“質量”)==F.col (“predicted_quality”)),1)\.otherwise (0))#總結正確的標簽在一個時間窗口來趨勢百分比的準確的預測accurate_prediction_summary=(quality_compare.groupBy (F.window (F.col (“process_time”),“一天”).alias (“窗口”),F.col (“accurate_prediction”))。數().withColumn (“window_day”F.expr (“to_date (window.start)”)).withColumn (“總”F。總和(F.col (“數”))。在(Window.partitionBy (“window_day”))).withColumn (“比”F.col (“數”)*One hundred./F.col (“總”))。選擇(“window_day”,“accurate_prediction”,“數”,“總”,“比”).withColumn (“accurate_prediction”,F.when (F.col (“accurate_prediction”)==1,“準確”).otherwise (“不準確”)).orderBy (“window_day”))<b>返回</b>accurate_prediction_summary
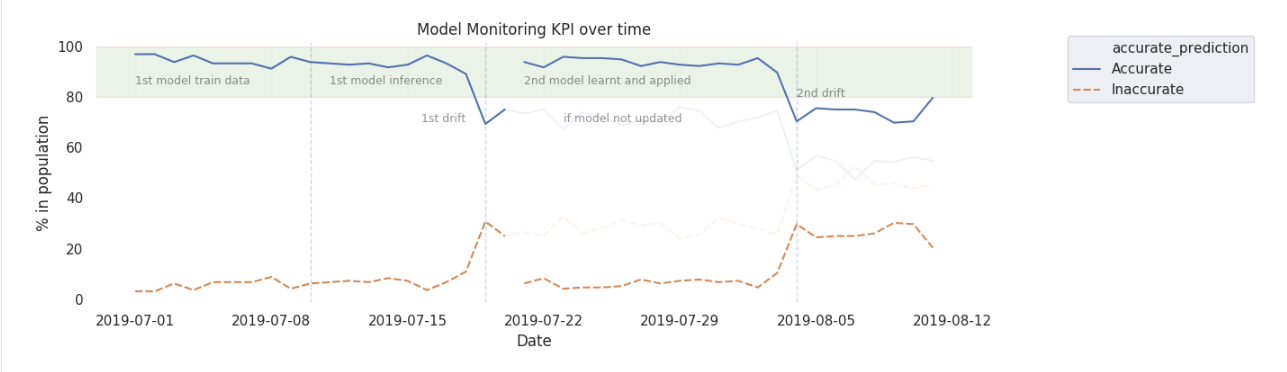
取決於延遲實際標簽到達預測標簽相比,這可能是一個重要的滯後指標。提供一些漂移的早期預警,該指標可以伴隨著領先指標的分布預測等質量標簽。為了避免假警報,這些kpi設計需要與業務上下文。
你可以設置準確預測總結趨勢控製範圍內可接受的業務需求。摘要可以監控使用標準的統計過程控製方法。當趨勢失去控製的限製,它可以觸發一個通知或一個動作使用新的數據重新創建一個新的模式。
下一個步驟
按照說明<一個href="https://github.com/joelcthomas/modeldrift" target="_blank">在這個GitHub回購複製上麵的例子和適應你的用例。提供更多的背景下,伴隨網絡研討會,<一個href="https://pages.m.eheci.com/ProductionizingMLWebinar_Reg.html" target="_blank">Productionizing機器學習——從部署到漂移檢測。










